* MMC quirks relating to performance/lifetime.
@ 2011-02-08 21:22 Andrei Warkentin
2011-02-08 21:38 ` Wolfram Sang
` (3 more replies)
0 siblings, 4 replies; 117+ messages in thread
From: Andrei Warkentin @ 2011-02-08 21:22 UTC (permalink / raw)
To: linux-arm-kernel
Hi,
I'm not sure if this is the best place to bring this up, but Russel's
name is on a fair share of drivers/mmc code, and there does seem to be
quite a bit of MMC-related discussions. Excuse me in advance if this
isn't the right forum :-).
Certain MMC vendors (maybe even quite a bit of them) use a pretty
rigid buffering scheme when it comes to handling writes. There is
usually a buffer A for random accesses, and a buffer B for sequential
accesses. For certain Toshiba parts, it looks like buffer A is 8KB
wide, with buffer B being 4MB wide, and all accesses larger than 8KB
effectively equating to 4MB accesses. Worse, consecutive small (8k)
writes are treated as one large sequential access, once again ending
up in buffer B, thus necessitating out-of-order writing to work around
this.
What this means is decreased life span for the parts, and it also
means a performance impact on small writes, but the first item is much
more crucial, especially for smaller parts.
As I've mentioned, probably more vendors are affected. How about a
generic MMC_BLOCK quirk that splits the requests (and optionally
reorders) them? The thresholds would then be adjustable as
module/kernel parameters based on manfid. I'm asking because I have a
patch now, but its ugly and hardcoded against a specific manufacturer.
Thanks,
A
^ permalink raw reply [flat|nested] 117+ messages in thread* Re: MMC quirks relating to performance/lifetime. 2011-02-08 21:22 MMC quirks relating to performance/lifetime Andrei Warkentin @ 2011-02-08 21:38 ` Wolfram Sang 2011-02-08 22:42 ` Russell King - ARM Linux ` (2 subsequent siblings) 3 siblings, 0 replies; 117+ messages in thread From: Wolfram Sang @ 2011-02-08 21:38 UTC (permalink / raw) To: Andrei Warkentin; +Cc: linux-arm-kernel, linux-mmc [-- Attachment #1: Type: text/plain, Size: 2032 bytes --] On Tue, Feb 08, 2011 at 03:22:59PM -0600, Andrei Warkentin wrote: > Hi, > > I'm not sure if this is the best place to bring this up, but Russel's > name is on a fair share of drivers/mmc code, and there does seem to be > quite a bit of MMC-related discussions. Excuse me in advance if this > isn't the right forum :-). Searching for MMC in MAINTAINERS will get you: MULTIMEDIA CARD (MMC), SECURE DIGITAL (SD) AND SDIO SUBSYSTEM M: Chris Ball <cjb@laptop.org> L: linux-mmc@vger.kernel.org ... List CCed... > Certain MMC vendors (maybe even quite a bit of them) use a pretty > rigid buffering scheme when it comes to handling writes. There is > usually a buffer A for random accesses, and a buffer B for sequential > accesses. For certain Toshiba parts, it looks like buffer A is 8KB > wide, with buffer B being 4MB wide, and all accesses larger than 8KB > effectively equating to 4MB accesses. Worse, consecutive small (8k) > writes are treated as one large sequential access, once again ending > up in buffer B, thus necessitating out-of-order writing to work around > this. > > What this means is decreased life span for the parts, and it also > means a performance impact on small writes, but the first item is much > more crucial, especially for smaller parts. > > As I've mentioned, probably more vendors are affected. How about a > generic MMC_BLOCK quirk that splits the requests (and optionally > reorders) them? The thresholds would then be adjustable as > module/kernel parameters based on manfid. I'm asking because I have a > patch now, but its ugly and hardcoded against a specific manufacturer. > > Thanks, > A > > _______________________________________________ > linux-arm-kernel mailing list > linux-arm-kernel@lists.infradead.org > http://lists.infradead.org/mailman/listinfo/linux-arm-kernel -- Pengutronix e.K. | Wolfram Sang | Industrial Linux Solutions | http://www.pengutronix.de/ | [-- Attachment #2: Digital signature --] [-- Type: application/pgp-signature, Size: 197 bytes --] ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-08 21:38 ` Wolfram Sang 0 siblings, 0 replies; 117+ messages in thread From: Wolfram Sang @ 2011-02-08 21:38 UTC (permalink / raw) To: linux-arm-kernel On Tue, Feb 08, 2011 at 03:22:59PM -0600, Andrei Warkentin wrote: > Hi, > > I'm not sure if this is the best place to bring this up, but Russel's > name is on a fair share of drivers/mmc code, and there does seem to be > quite a bit of MMC-related discussions. Excuse me in advance if this > isn't the right forum :-). Searching for MMC in MAINTAINERS will get you: MULTIMEDIA CARD (MMC), SECURE DIGITAL (SD) AND SDIO SUBSYSTEM M: Chris Ball <cjb@laptop.org> L: linux-mmc at vger.kernel.org ... List CCed... > Certain MMC vendors (maybe even quite a bit of them) use a pretty > rigid buffering scheme when it comes to handling writes. There is > usually a buffer A for random accesses, and a buffer B for sequential > accesses. For certain Toshiba parts, it looks like buffer A is 8KB > wide, with buffer B being 4MB wide, and all accesses larger than 8KB > effectively equating to 4MB accesses. Worse, consecutive small (8k) > writes are treated as one large sequential access, once again ending > up in buffer B, thus necessitating out-of-order writing to work around > this. > > What this means is decreased life span for the parts, and it also > means a performance impact on small writes, but the first item is much > more crucial, especially for smaller parts. > > As I've mentioned, probably more vendors are affected. How about a > generic MMC_BLOCK quirk that splits the requests (and optionally > reorders) them? The thresholds would then be adjustable as > module/kernel parameters based on manfid. I'm asking because I have a > patch now, but its ugly and hardcoded against a specific manufacturer. > > Thanks, > A > > _______________________________________________ > linux-arm-kernel mailing list > linux-arm-kernel at lists.infradead.org > http://lists.infradead.org/mailman/listinfo/linux-arm-kernel -- Pengutronix e.K. | Wolfram Sang | Industrial Linux Solutions | http://www.pengutronix.de/ | -------------- next part -------------- A non-text attachment was scrubbed... Name: not available Type: application/pgp-signature Size: 197 bytes Desc: Digital signature URL: <http://lists.infradead.org/pipermail/linux-arm-kernel/attachments/20110208/88da88a3/attachment.sig> ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. 2011-02-08 21:22 MMC quirks relating to performance/lifetime Andrei Warkentin 2011-02-08 21:38 ` Wolfram Sang @ 2011-02-08 22:42 ` Russell King - ARM Linux 2011-02-09 8:37 ` Linus Walleij 2011-02-11 14:41 ` Pavel Machek 3 siblings, 0 replies; 117+ messages in thread From: Russell King - ARM Linux @ 2011-02-08 22:42 UTC (permalink / raw) To: linux-arm-kernel On Tue, Feb 08, 2011 at 03:22:59PM -0600, Andrei Warkentin wrote: > I'm not sure if this is the best place to bring this up, but Russel's > name is on a fair share of drivers/mmc code, and there does seem to be > quite a bit of MMC-related discussions. Excuse me in advance if this > isn't the right forum :-). I dropped out of MMC stuff once we had a functional infrastructure in place in the kernel - before that, there were various competing implementations around. The implementation that's there was based off what meager information was available on the MMC protocol, as published by some of the card manufacturers. Certainly no one had the backing to be able to get the official specifications and such like, nor to approach the various companies to get the sort of details you're talking about. So, what's there is basically a best-effort to provide something usable and which works (most of the time.) And to reflect that, error handling is almost non-existent. As part of trying to get better performance out of PIO-based interfaces, I've recently been putting some effort into making the mmc block driver a little more rugged in the face of various communication errors. That's not to say that I'm now taking an active interest in MMC - I'm not. I'm just fixing the occasional issue which causes me problem. As for what you're talking about (controlling the coalescing of requests), I think you're better off sorting that out with the higher block layers to restrict the amount of coalescing that happens there. I think there are some hooks already in place which allow you to define the maximum size of any request, but this doesn't take account of read/write properties. Maybe that's something the higher block layer should be extended with? If so, you'll have to discuss it with the block layer folk. ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-08 21:22 MMC quirks relating to performance/lifetime Andrei Warkentin @ 2011-02-09 8:37 ` Linus Walleij 2011-02-08 22:42 ` Russell King - ARM Linux ` (2 subsequent siblings) 3 siblings, 0 replies; 117+ messages in thread From: Linus Walleij @ 2011-02-09 8:37 UTC (permalink / raw) To: Andrei Warkentin, linux-mmc; +Cc: linux-arm-kernel [Quoting in verbatin so the orginal mail hits linux-mmc, this is very interesting!] 2011/2/8 Andrei Warkentin <andreiw@motorola.com>: > Hi, > > I'm not sure if this is the best place to bring this up, but Russel's > name is on a fair share of drivers/mmc code, and there does seem to be > quite a bit of MMC-related discussions. Excuse me in advance if this > isn't the right forum :-). > > Certain MMC vendors (maybe even quite a bit of them) use a pretty > rigid buffering scheme when it comes to handling writes. There is > usually a buffer A for random accesses, and a buffer B for sequential > accesses. For certain Toshiba parts, it looks like buffer A is 8KB > wide, with buffer B being 4MB wide, and all accesses larger than 8KB > effectively equating to 4MB accesses. Worse, consecutive small (8k) > writes are treated as one large sequential access, once again ending > up in buffer B, thus necessitating out-of-order writing to work around > this. > > What this means is decreased life span for the parts, and it also > means a performance impact on small writes, but the first item is much > more crucial, especially for smaller parts. > > As I've mentioned, probably more vendors are affected. How about a > generic MMC_BLOCK quirk that splits the requests (and optionally > reorders) them? The thresholds would then be adjustable as > module/kernel parameters based on manfid. I'm asking because I have a > patch now, but its ugly and hardcoded against a specific manufacturer. There is a quirk API so that specific quirks can be flagged for certain vendors and cards, e.g. some Toshibas in this case. e.g. grep the kernel source for MMC_QUIRK_BLKSZ_FOR_BYTE_MODE. But as Russell says this probably needs to be signalled up to the block layer to be handled properly. Why don't you post the code you have today as an RFC: patch, I think many will be interested? Yours, Linus Walleij ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-09 8:37 ` Linus Walleij 0 siblings, 0 replies; 117+ messages in thread From: Linus Walleij @ 2011-02-09 8:37 UTC (permalink / raw) To: linux-arm-kernel [Quoting in verbatin so the orginal mail hits linux-mmc, this is very interesting!] 2011/2/8 Andrei Warkentin <andreiw@motorola.com>: > Hi, > > I'm not sure if this is the best place to bring this up, but Russel's > name is on a fair share of drivers/mmc code, and there does seem to be > quite a bit of MMC-related discussions. Excuse me in advance if this > isn't the right forum :-). > > Certain MMC vendors (maybe even quite a bit of them) use a pretty > rigid buffering scheme when it comes to handling writes. There is > usually a buffer A for random accesses, and a buffer B for sequential > accesses. For certain Toshiba parts, it looks like buffer A is 8KB > wide, with buffer B being 4MB wide, and all accesses larger than 8KB > effectively equating to 4MB accesses. Worse, consecutive small (8k) > writes are treated as one large sequential access, once again ending > up in buffer B, thus necessitating out-of-order writing to work around > this. > > What this means is decreased life span for the parts, and it also > means a performance impact on small writes, but the first item is much > more crucial, especially for smaller parts. > > As I've mentioned, probably more vendors are affected. How about a > generic MMC_BLOCK quirk that splits the requests (and optionally > reorders) them? The thresholds would then be adjustable as > module/kernel parameters based on manfid. I'm asking because I have a > patch now, but its ugly and hardcoded against a specific manufacturer. There is a quirk API so that specific quirks can be flagged for certain vendors and cards, e.g. some Toshibas in this case. e.g. grep the kernel source for MMC_QUIRK_BLKSZ_FOR_BYTE_MODE. But as Russell says this probably needs to be signalled up to the block layer to be handled properly. Why don't you post the code you have today as an RFC: patch, I think many will be interested? Yours, Linus Walleij ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-09 8:37 ` Linus Walleij @ 2011-02-09 9:13 ` Arnd Bergmann -1 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-09 9:13 UTC (permalink / raw) To: linux-arm-kernel; +Cc: Linus Walleij, Andrei Warkentin, linux-mmc On Wednesday 09 February 2011 09:37:40 Linus Walleij wrote: > [Quoting in verbatin so the orginal mail hits linux-mmc, this is very > interesting!] > > 2011/2/8 Andrei Warkentin <andreiw@motorola.com>: > > Hi, > > > > I'm not sure if this is the best place to bring this up, but Russel's > > name is on a fair share of drivers/mmc code, and there does seem to be > > quite a bit of MMC-related discussions. Excuse me in advance if this > > isn't the right forum :-). > > > > Certain MMC vendors (maybe even quite a bit of them) use a pretty > > rigid buffering scheme when it comes to handling writes. There is > > usually a buffer A for random accesses, and a buffer B for sequential > > accesses. For certain Toshiba parts, it looks like buffer A is 8KB > > wide, with buffer B being 4MB wide, and all accesses larger than 8KB > > effectively equating to 4MB accesses. Worse, consecutive small (8k) > > writes are treated as one large sequential access, once again ending > > up in buffer B, thus necessitating out-of-order writing to work around > > this. It's more complex, but I now have a pretty good understanding of what the flash media actually do, after doing a lot of benchmarking. Most of my results so far are documented on https://wiki.linaro.org/WorkingGroups/KernelConsolidation/Projects/FlashCardSurvey but I still need to write about the more recent discoveries. What you describe as buffer A is the "page size" of the underlying flash. It depends on the size and brand of the NAND flash chip and can be anywhere between 2 KB and 16 KB for modern cards, depending on how they combine multiple chips and planes within the chips. What you describe as buffer B is sometime called an "erase block group" or an "allocation unit". This is the smallest unit that gets kept in a global lookup table in the medium and can be anywhere between 1 MB and 8 MB for cards larger than 4 GB, or as small as 128 KB (a single erase block) for smaller media, as far as I have seen. When you don't write full aligned allocation units, the card will have to eventually do garbage collection on the allocation unit, which can take a long time (many milliseconds). Most cards have a third size, typically somewhere between 32 and 128 KB, which is the optimimum size for writes. While you can do linear writes to the card in page size units (writing an allocation unit from start to finish), doing random access within the allocation unit will be much faster doing larger writes. > > What this means is decreased life span for the parts, and it also > > means a performance impact on small writes, but the first item is much > > more crucial, especially for smaller parts. > > > > As I've mentioned, probably more vendors are affected. How about a > > generic MMC_BLOCK quirk that splits the requests (and optionally > > reorders) them? The thresholds would then be adjustable as > > module/kernel parameters based on manfid. I'm asking because I have a > > patch now, but its ugly and hardcoded against a specific manufacturer. It's not just MMC specific: USB flash drives, CF cards and even cheap PATA or SATA SSDs have the same patterns. I think this will need to be solved on a higher level, in the block device elevator code and in the file systems. > There is a quirk API so that specific quirks can be flagged for certain > vendors and cards, e.g. some Toshibas in this case. e.g. grep the > kernel source for MMC_QUIRK_BLKSZ_FOR_BYTE_MODE. > > But as Russell says this probably needs to be signalled up to the > block layer to be handled properly. > > Why don't you post the code you have today as an RFC: patch, > I think many will be interested? Yes, I agree, that would be good. Also, I'd be interested to see the output of 'head /sys/block/mmcblk0/device/*' on that card. I'm guessing that the manufacturer ID of 0x0002 is Toshiba, and these are indeed the worst cards that I have seen so far, because they can not do random access within an allocation unit, and they can not write to multiple allocation units alternating (# open AUs linear is "1" in my wiki table), while most cards can do at least two. Andrei, I'm certainly interested in working with you on this. The point you brought up about the toshiba cards being especially bad is certainly vald, even if we do something better in the block layer, we need to have a way to detect the worst-case scenario, so we can work around that. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-09 9:13 ` Arnd Bergmann 0 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-09 9:13 UTC (permalink / raw) To: linux-arm-kernel On Wednesday 09 February 2011 09:37:40 Linus Walleij wrote: > [Quoting in verbatin so the orginal mail hits linux-mmc, this is very > interesting!] > > 2011/2/8 Andrei Warkentin <andreiw@motorola.com>: > > Hi, > > > > I'm not sure if this is the best place to bring this up, but Russel's > > name is on a fair share of drivers/mmc code, and there does seem to be > > quite a bit of MMC-related discussions. Excuse me in advance if this > > isn't the right forum :-). > > > > Certain MMC vendors (maybe even quite a bit of them) use a pretty > > rigid buffering scheme when it comes to handling writes. There is > > usually a buffer A for random accesses, and a buffer B for sequential > > accesses. For certain Toshiba parts, it looks like buffer A is 8KB > > wide, with buffer B being 4MB wide, and all accesses larger than 8KB > > effectively equating to 4MB accesses. Worse, consecutive small (8k) > > writes are treated as one large sequential access, once again ending > > up in buffer B, thus necessitating out-of-order writing to work around > > this. It's more complex, but I now have a pretty good understanding of what the flash media actually do, after doing a lot of benchmarking. Most of my results so far are documented on https://wiki.linaro.org/WorkingGroups/KernelConsolidation/Projects/FlashCardSurvey but I still need to write about the more recent discoveries. What you describe as buffer A is the "page size" of the underlying flash. It depends on the size and brand of the NAND flash chip and can be anywhere between 2 KB and 16 KB for modern cards, depending on how they combine multiple chips and planes within the chips. What you describe as buffer B is sometime called an "erase block group" or an "allocation unit". This is the smallest unit that gets kept in a global lookup table in the medium and can be anywhere between 1 MB and 8 MB for cards larger than 4 GB, or as small as 128 KB (a single erase block) for smaller media, as far as I have seen. When you don't write full aligned allocation units, the card will have to eventually do garbage collection on the allocation unit, which can take a long time (many milliseconds). Most cards have a third size, typically somewhere between 32 and 128 KB, which is the optimimum size for writes. While you can do linear writes to the card in page size units (writing an allocation unit from start to finish), doing random access within the allocation unit will be much faster doing larger writes. > > What this means is decreased life span for the parts, and it also > > means a performance impact on small writes, but the first item is much > > more crucial, especially for smaller parts. > > > > As I've mentioned, probably more vendors are affected. How about a > > generic MMC_BLOCK quirk that splits the requests (and optionally > > reorders) them? The thresholds would then be adjustable as > > module/kernel parameters based on manfid. I'm asking because I have a > > patch now, but its ugly and hardcoded against a specific manufacturer. It's not just MMC specific: USB flash drives, CF cards and even cheap PATA or SATA SSDs have the same patterns. I think this will need to be solved on a higher level, in the block device elevator code and in the file systems. > There is a quirk API so that specific quirks can be flagged for certain > vendors and cards, e.g. some Toshibas in this case. e.g. grep the > kernel source for MMC_QUIRK_BLKSZ_FOR_BYTE_MODE. > > But as Russell says this probably needs to be signalled up to the > block layer to be handled properly. > > Why don't you post the code you have today as an RFC: patch, > I think many will be interested? Yes, I agree, that would be good. Also, I'd be interested to see the output of 'head /sys/block/mmcblk0/device/*' on that card. I'm guessing that the manufacturer ID of 0x0002 is Toshiba, and these are indeed the worst cards that I have seen so far, because they can not do random access within an allocation unit, and they can not write to multiple allocation units alternating (# open AUs linear is "1" in my wiki table), while most cards can do at least two. Andrei, I'm certainly interested in working with you on this. The point you brought up about the toshiba cards being especially bad is certainly vald, even if we do something better in the block layer, we need to have a way to detect the worst-case scenario, so we can work around that. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-09 9:13 ` Arnd Bergmann @ 2011-02-11 22:33 ` Andrei Warkentin -1 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-11 22:33 UTC (permalink / raw) To: Arnd Bergmann; +Cc: Linus Walleij, linux-mmc, linux-arm-kernel On Wed, Feb 9, 2011 at 3:13 AM, Arnd Bergmann <arnd@arndb.de> wrote: > On Wednesday 09 February 2011 09:37:40 Linus Walleij wrote: >> [Quoting in verbatin so the orginal mail hits linux-mmc, this is very >> interesting!] >> >> 2011/2/8 Andrei Warkentin <andreiw@motorola.com>: >> > Hi, >> > >> > I'm not sure if this is the best place to bring this up, but Russel's >> > name is on a fair share of drivers/mmc code, and there does seem to be >> > quite a bit of MMC-related discussions. Excuse me in advance if this >> > isn't the right forum :-). >> > >> > Certain MMC vendors (maybe even quite a bit of them) use a pretty >> > rigid buffering scheme when it comes to handling writes. There is >> > usually a buffer A for random accesses, and a buffer B for sequential >> > accesses. For certain Toshiba parts, it looks like buffer A is 8KB >> > wide, with buffer B being 4MB wide, and all accesses larger than 8KB >> > effectively equating to 4MB accesses. Worse, consecutive small (8k) >> > writes are treated as one large sequential access, once again ending >> > up in buffer B, thus necessitating out-of-order writing to work around >> > this. > > It's more complex, but I now have a pretty good understanding of > what the flash media actually do, after doing a lot of benchmarking. > Most of my results so far are documented on > > https://wiki.linaro.org/WorkingGroups/KernelConsolidation/Projects/FlashCardSurvey > > but I still need to write about the more recent discoveries. > > What you describe as buffer A is the "page size" of the underlying > flash. It depends on the size and brand of the NAND flash chip and > can be anywhere between 2 KB and 16 KB for modern cards, depending > on how they combine multiple chips and planes within the chips. > > What you describe as buffer B is sometime called an "erase block > group" or an "allocation unit". This is the smallest unit that > gets kept in a global lookup table in the medium and can be anywhere > between 1 MB and 8 MB for cards larger than 4 GB, or as small as > 128 KB (a single erase block) for smaller media, as far as I have > seen. When you don't write full aligned allocation units, the > card will have to eventually do garbage collection on the allocation > unit, which can take a long time (many milliseconds). > > Most cards have a third size, typically somewhere between 32 and 128 KB, > which is the optimimum size for writes. While you can do linear > writes to the card in page size units (writing an allocation unit > from start to finish), doing random access within the allocation unit > will be much faster doing larger writes. > >> > What this means is decreased life span for the parts, and it also >> > means a performance impact on small writes, but the first item is much >> > more crucial, especially for smaller parts. >> > >> > As I've mentioned, probably more vendors are affected. How about a >> > generic MMC_BLOCK quirk that splits the requests (and optionally >> > reorders) them? The thresholds would then be adjustable as >> > module/kernel parameters based on manfid. I'm asking because I have a >> > patch now, but its ugly and hardcoded against a specific manufacturer. > > It's not just MMC specific: USB flash drives, CF cards and even cheap > PATA or SATA SSDs have the same patterns. I think this will need > to be solved on a higher level, in the block device elevator code > and in the file systems. > >> There is a quirk API so that specific quirks can be flagged for certain >> vendors and cards, e.g. some Toshibas in this case. e.g. grep the >> kernel source for MMC_QUIRK_BLKSZ_FOR_BYTE_MODE. >> >> But as Russell says this probably needs to be signalled up to the >> block layer to be handled properly. >> >> Why don't you post the code you have today as an RFC: patch, >> I think many will be interested? > > Yes, I agree, that would be good. Also, I'd be interested to see the > output of 'head /sys/block/mmcblk0/device/*' on that card. I'm guessing > that the manufacturer ID of 0x0002 is Toshiba, and these are indeed > the worst cards that I have seen so far, because they can not do > random access within an allocation unit, and they can not write to > multiple allocation units alternating (# open AUs linear is "1" in > my wiki table), while most cards can do at least two. > > Andrei, I'm certainly interested in working with you on this. > The point you brought up about the toshiba cards being especially > bad is certainly vald, even if we do something better in the block > layer, we need to have a way to detect the worst-case scenario, > so we can work around that. > > Arnd > Arnd, Yes, this is a Toshiba card. I've sent the patch as a reply to Linus' email. cid - 02010053454d3332479070cc51451d00 csd - d00f00320f5903ffffffffff92404000 erase_size - 524288 fwrev - 0x0 hwrev - 0x0 manfid - 0x000002 name - SEM32G oemid - 0x0100 preferred_erase_size - 2097152 ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-11 22:33 ` Andrei Warkentin 0 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-11 22:33 UTC (permalink / raw) To: linux-arm-kernel On Wed, Feb 9, 2011 at 3:13 AM, Arnd Bergmann <arnd@arndb.de> wrote: > On Wednesday 09 February 2011 09:37:40 Linus Walleij wrote: >> [Quoting in verbatin so the orginal mail hits linux-mmc, this is very >> interesting!] >> >> 2011/2/8 Andrei Warkentin <andreiw@motorola.com>: >> > Hi, >> > >> > I'm not sure if this is the best place to bring this up, but Russel's >> > name is on a fair share of drivers/mmc code, and there does seem to be >> > quite a bit of MMC-related discussions. Excuse me in advance if this >> > isn't the right forum :-). >> > >> > Certain MMC vendors (maybe even quite a bit of them) use a pretty >> > rigid buffering scheme when it comes to handling writes. There is >> > usually a buffer A for random accesses, and a buffer B for sequential >> > accesses. For certain Toshiba parts, it looks like buffer A is 8KB >> > wide, with buffer B being 4MB wide, and all accesses larger than 8KB >> > effectively equating to 4MB accesses. Worse, consecutive small (8k) >> > writes are treated as one large sequential access, once again ending >> > up in buffer B, thus necessitating out-of-order writing to work around >> > this. > > It's more complex, but I now have a pretty good understanding of > what the flash media actually do, after doing a lot of benchmarking. > Most of my results so far are documented on > > https://wiki.linaro.org/WorkingGroups/KernelConsolidation/Projects/FlashCardSurvey > > but I still need to write about the more recent discoveries. > > What you describe as buffer A is the "page size" of the underlying > flash. It depends on the size and brand of the NAND flash chip and > can be anywhere between 2 KB and 16 KB for modern cards, depending > on how they combine multiple chips and planes within the chips. > > What you describe as buffer B is sometime called an "erase block > group" or an "allocation unit". This is the smallest unit that > gets kept in a global lookup table in the medium and can be anywhere > between 1 MB and 8 MB for cards larger than 4 GB, or as small as > 128 KB (a single erase block) for smaller media, as far as I have > seen. When you don't write full aligned allocation units, the > card will have to eventually do garbage collection on the allocation > unit, which can take a long time (many milliseconds). > > Most cards have a third size, typically somewhere between 32 and 128 KB, > which is the optimimum size for writes. While you can do linear > writes to the card in page size units (writing an allocation unit > from start to finish), doing random access within the allocation unit > will be much faster doing larger writes. > >> > What this means is decreased life span for the parts, and it also >> > means a performance impact on small writes, but the first item is much >> > more crucial, especially for smaller parts. >> > >> > As I've mentioned, probably more vendors are affected. How about a >> > generic MMC_BLOCK quirk that splits the requests (and optionally >> > reorders) them? The thresholds would then be adjustable as >> > module/kernel parameters based on manfid. I'm asking because I have a >> > patch now, but its ugly and hardcoded against a specific manufacturer. > > It's not just MMC specific: USB flash drives, CF cards and even cheap > PATA or SATA SSDs have the same patterns. I think this will need > to be solved on a higher level, in the block device elevator code > and in the file systems. > >> There is a quirk API so that specific quirks can be flagged for certain >> vendors and cards, e.g. some Toshibas in this case. e.g. grep the >> kernel source for MMC_QUIRK_BLKSZ_FOR_BYTE_MODE. >> >> But as Russell says this probably needs to be signalled up to the >> block layer to be handled properly. >> >> Why don't you post the code you have today as an RFC: patch, >> I think many will be interested? > > Yes, I agree, that would be good. Also, I'd be interested to see the > output of 'head /sys/block/mmcblk0/device/*' on that card. I'm guessing > that the manufacturer ID of 0x0002 is Toshiba, and these are indeed > the worst cards that I have seen so far, because they can not do > random access within an allocation unit, and they can not write to > multiple allocation units alternating (# open AUs linear is "1" in > my wiki table), while most cards can do at least two. > > Andrei, I'm certainly interested in working with you on this. > The point you brought up about the toshiba cards being especially > bad is certainly vald, even if we do something better in the block > layer, we need to have a way to detect the worst-case scenario, > so we can work around that. > > ? ? ? ?Arnd > Arnd, Yes, this is a Toshiba card. I've sent the patch as a reply to Linus' email. cid - 02010053454d3332479070cc51451d00 csd - d00f00320f5903ffffffffff92404000 erase_size - 524288 fwrev - 0x0 hwrev - 0x0 manfid - 0x000002 name - SEM32G oemid - 0x0100 preferred_erase_size - 2097152 ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-11 22:33 ` Andrei Warkentin @ 2011-02-12 17:05 ` Arnd Bergmann -1 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-12 17:05 UTC (permalink / raw) To: Andrei Warkentin; +Cc: linux-arm-kernel, Linus Walleij, linux-mmc On Friday 11 February 2011 23:33:42 Andrei Warkentin wrote: > On Wed, Feb 9, 2011 at 3:13 AM, Arnd Bergmann <arnd@arndb.de> wrote: > Yes, this is a Toshiba card. I've sent the patch as a reply to Linus' email. > > cid - 02010053454d3332479070cc51451d00 > csd - d00f00320f5903ffffffffff92404000 > erase_size - 524288 > fwrev - 0x0 > hwrev - 0x0 > manfid - 0x000002 > name - SEM32G > oemid - 0x0100 > preferred_erase_size - 2097152 Very interesting. So the manfid is the same as on most Kingston cards, but the oemid is different. Most cards have a two-letter ASCII code in there, 0x544d ("TM") on Kingston cards, and I always assumed that this stood for "Toshiba Memory". What is even stranger is the size value (among other fields) in the CSD, the card claims a size of exactly 32GB, which I find hard to believe, given that there are always some bad and reserved blocks. Are you sure that the card you have is authentic? I've heard a lot about fake USB sticks advertising a size that is much larger than the actual flash inside of them. Also this is the first card that I see advertise an allocation unit size of 2MB (preferred_erase_size), all other cards seem to advertise 4 MB these days, even if they actually have 2 or 8 MB. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-12 17:05 ` Arnd Bergmann 0 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-12 17:05 UTC (permalink / raw) To: linux-arm-kernel On Friday 11 February 2011 23:33:42 Andrei Warkentin wrote: > On Wed, Feb 9, 2011 at 3:13 AM, Arnd Bergmann <arnd@arndb.de> wrote: > Yes, this is a Toshiba card. I've sent the patch as a reply to Linus' email. > > cid - 02010053454d3332479070cc51451d00 > csd - d00f00320f5903ffffffffff92404000 > erase_size - 524288 > fwrev - 0x0 > hwrev - 0x0 > manfid - 0x000002 > name - SEM32G > oemid - 0x0100 > preferred_erase_size - 2097152 Very interesting. So the manfid is the same as on most Kingston cards, but the oemid is different. Most cards have a two-letter ASCII code in there, 0x544d ("TM") on Kingston cards, and I always assumed that this stood for "Toshiba Memory". What is even stranger is the size value (among other fields) in the CSD, the card claims a size of exactly 32GB, which I find hard to believe, given that there are always some bad and reserved blocks. Are you sure that the card you have is authentic? I've heard a lot about fake USB sticks advertising a size that is much larger than the actual flash inside of them. Also this is the first card that I see advertise an allocation unit size of 2MB (preferred_erase_size), all other cards seem to advertise 4 MB these days, even if they actually have 2 or 8 MB. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-12 17:05 ` Arnd Bergmann @ 2011-02-12 17:33 ` Andrei Warkentin -1 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-12 17:33 UTC (permalink / raw) To: Arnd Bergmann; +Cc: linux-arm-kernel, Linus Walleij, linux-mmc On Sat, Feb 12, 2011 at 11:05 AM, Arnd Bergmann <arnd@arndb.de> wrote: > On Friday 11 February 2011 23:33:42 Andrei Warkentin wrote: >> On Wed, Feb 9, 2011 at 3:13 AM, Arnd Bergmann <arnd@arndb.de> wrote: > >> Yes, this is a Toshiba card. I've sent the patch as a reply to Linus' email. >> >> cid - 02010053454d3332479070cc51451d00 >> csd - d00f00320f5903ffffffffff92404000 >> erase_size - 524288 >> fwrev - 0x0 >> hwrev - 0x0 >> manfid - 0x000002 >> name - SEM32G >> oemid - 0x0100 >> preferred_erase_size - 2097152 > > Very interesting. So the manfid is the same as on most Kingston cards, > but the oemid is different. Most cards have a two-letter ASCII code > in there, 0x544d ("TM") on Kingston cards, and I always assumed that > this stood for "Toshiba Memory". > > What is even stranger is the size value (among other fields) in the CSD, > the card claims a size of exactly 32GB, which I find hard to believe, > given that there are always some bad and reserved blocks. > > Are you sure that the card you have is authentic? I've heard a lot about > fake USB sticks advertising a size that is much larger than the actual > flash inside of them. > > Also this is the first card that I see advertise an allocation unit > size of 2MB (preferred_erase_size), all other cards seem to advertise > 4 MB these days, even if they actually have 2 or 8 MB. > > Arnd > This is a Toshiba eMMC part. It is 32GB as far as the OS can see and access. ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-12 17:33 ` Andrei Warkentin 0 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-12 17:33 UTC (permalink / raw) To: linux-arm-kernel On Sat, Feb 12, 2011 at 11:05 AM, Arnd Bergmann <arnd@arndb.de> wrote: > On Friday 11 February 2011 23:33:42 Andrei Warkentin wrote: >> On Wed, Feb 9, 2011 at 3:13 AM, Arnd Bergmann <arnd@arndb.de> wrote: > >> Yes, this is a Toshiba card. I've sent the patch as a reply to Linus' email. >> >> cid - 02010053454d3332479070cc51451d00 >> csd - d00f00320f5903ffffffffff92404000 >> erase_size - 524288 >> fwrev - 0x0 >> hwrev - 0x0 >> manfid - 0x000002 >> name - SEM32G >> oemid - 0x0100 >> preferred_erase_size - 2097152 > > Very interesting. So the manfid is the same as on most Kingston cards, > but the oemid is different. Most cards have a two-letter ASCII code > in there, 0x544d ("TM") on Kingston cards, and I always assumed that > this stood for "Toshiba Memory". > > What is even stranger is the size value (among other fields) in the CSD, > the card claims a size of exactly 32GB, which I find hard to believe, > given that there are always some bad and reserved blocks. > > Are you sure that the card you have is authentic? I've heard a lot about > fake USB sticks advertising a size that is much larger than the actual > flash inside of them. > > Also this is the first card that I see advertise an allocation unit > size of 2MB (preferred_erase_size), all other cards seem to advertise > 4 MB these days, even if they actually have 2 or 8 MB. > > ? ? ? ?Arnd > This is a Toshiba eMMC part. It is 32GB as far as the OS can see and access. ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-12 17:33 ` Andrei Warkentin @ 2011-02-12 18:22 ` Arnd Bergmann -1 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-12 18:22 UTC (permalink / raw) To: Andrei Warkentin; +Cc: linux-arm-kernel, Linus Walleij, linux-mmc On Saturday 12 February 2011 18:33:10 Andrei Warkentin wrote: > On Sat, Feb 12, 2011 at 11:05 AM, Arnd Bergmann <arnd@arndb.de> wrote: > > On Friday 11 February 2011 23:33:42 Andrei Warkentin wrote: > >> On Wed, Feb 9, 2011 at 3:13 AM, Arnd Bergmann <arnd@arndb.de> wrote: > > > >> Yes, this is a Toshiba card. I've sent the patch as a reply to Linus' email. > >> > >> cid - 02010053454d3332479070cc51451d00 > >> csd - d00f 0032 0f59 03ff ffffffff92404000 > >> erase_size - 524288 > >> fwrev - 0x0 > >> hwrev - 0x0 > >> manfid - 0x000002 > >> name - SEM32G > >> oemid - 0x0100 > >> preferred_erase_size - 2097152 > > > > This is a Toshiba eMMC part. It is 32GB as far as the OS can see and access. Ah, right, that explains all the values, which make sense for eMMC4 but not for SDHC ;-) Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-12 18:22 ` Arnd Bergmann 0 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-12 18:22 UTC (permalink / raw) To: linux-arm-kernel On Saturday 12 February 2011 18:33:10 Andrei Warkentin wrote: > On Sat, Feb 12, 2011 at 11:05 AM, Arnd Bergmann <arnd@arndb.de> wrote: > > On Friday 11 February 2011 23:33:42 Andrei Warkentin wrote: > >> On Wed, Feb 9, 2011 at 3:13 AM, Arnd Bergmann <arnd@arndb.de> wrote: > > > >> Yes, this is a Toshiba card. I've sent the patch as a reply to Linus' email. > >> > >> cid - 02010053454d3332479070cc51451d00 > >> csd - d00f 0032 0f59 03ff ffffffff92404000 > >> erase_size - 524288 > >> fwrev - 0x0 > >> hwrev - 0x0 > >> manfid - 0x000002 > >> name - SEM32G > >> oemid - 0x0100 > >> preferred_erase_size - 2097152 > > > > This is a Toshiba eMMC part. It is 32GB as far as the OS can see and access. Ah, right, that explains all the values, which make sense for eMMC4 but not for SDHC ;-) Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-11 22:33 ` Andrei Warkentin @ 2011-02-18 1:10 ` Andrei Warkentin -1 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-18 1:10 UTC (permalink / raw) To: Arnd Bergmann; +Cc: linux-arm-kernel, Linus Walleij, linux-mmc On Fri, Feb 11, 2011 at 4:33 PM, Andrei Warkentin <andreiw@motorola.com> wrote: > Arnd, > > Yes, this is a Toshiba card. I've sent the patch as a reply to Linus' email. > > cid - 02010053454d3332479070cc51451d00 > csd - d00f00320f5903ffffffffff92404000 > erase_size - 524288 > fwrev - 0x0 > hwrev - 0x0 > manfid - 0x000002 > name - SEM32G > oemid - 0x0100 > preferred_erase_size - 2097152 > Ok. Big mistake. Sorry about that. This card is Sandisk card. I got confused over all the manfids changing. Here is the Toshiba card: cid - 1101004d4d4333324703101a17746d00 csd - 900e00320f5903ffffffffe796400000 erase_size - 524288 fwrev - 0x0 hwrev - 0x0 manfid - 0x000011 name - MMC32G oemid - 0x0100 preferred_erase_size - 4194304 I'll get you the flashbench timings for both. ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-18 1:10 ` Andrei Warkentin 0 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-18 1:10 UTC (permalink / raw) To: linux-arm-kernel On Fri, Feb 11, 2011 at 4:33 PM, Andrei Warkentin <andreiw@motorola.com> wrote: > Arnd, > > Yes, this is a Toshiba card. I've sent the patch as a reply to Linus' email. > > cid - 02010053454d3332479070cc51451d00 > csd - d00f00320f5903ffffffffff92404000 > erase_size - 524288 > fwrev - 0x0 > hwrev - 0x0 > manfid - 0x000002 > name - SEM32G > oemid - 0x0100 > preferred_erase_size - 2097152 > Ok. Big mistake. Sorry about that. This card is Sandisk card. I got confused over all the manfids changing. Here is the Toshiba card: cid - 1101004d4d4333324703101a17746d00 csd - 900e00320f5903ffffffffe796400000 erase_size - 524288 fwrev - 0x0 hwrev - 0x0 manfid - 0x000011 name - MMC32G oemid - 0x0100 preferred_erase_size - 4194304 I'll get you the flashbench timings for both. ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-18 1:10 ` Andrei Warkentin @ 2011-02-18 13:44 ` Arnd Bergmann -1 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-18 13:44 UTC (permalink / raw) To: linux-arm-kernel; +Cc: Andrei Warkentin, Linus Walleij, linux-mmc On Friday 18 February 2011, Andrei Warkentin wrote: > On Fri, Feb 11, 2011 at 4:33 PM, Andrei Warkentin <andreiw@motorola.com> wrote: > > Arnd, > > > > Yes, this is a Toshiba card. I've sent the patch as a reply to Linus' email. > > > > cid - 02010053454d3332479070cc51451d00 > > csd - d00f00320f5903ffffffffff92404000 > > erase_size - 524288 > > fwrev - 0x0 > > hwrev - 0x0 > > manfid - 0x000002 > > name - SEM32G > > oemid - 0x0100 > > preferred_erase_size - 2097152 > > > > Ok. Big mistake. Sorry about that. This card is Sandisk card. I got > confused over all the manfids changing. > > Here is the Toshiba card: > > cid - 1101004d4d4333324703101a17746d00 > csd - 900e00320f5903ffffffffe796400000 > erase_size - 524288 > fwrev - 0x0 > hwrev - 0x0 > manfid - 0x000011 > name - MMC32G > oemid - 0x0100 > preferred_erase_size - 4194304 > > I'll get you the flashbench timings for both. I'm curious. Neither the manfid nor the oemid fields of either card match what I have seen on SD cards, I would expect them to be Sandisk: manfid 0x000003, oemid 0x5344 Toshiba: manfid 0x000002, oemid 0x544d I have not actually seen any Toshiba SD cards, but I assume that they use the same controllers as Kingston. Does anyone know if the IDs have any correlation between MMC and SD controllers? Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-18 13:44 ` Arnd Bergmann 0 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-18 13:44 UTC (permalink / raw) To: linux-arm-kernel On Friday 18 February 2011, Andrei Warkentin wrote: > On Fri, Feb 11, 2011 at 4:33 PM, Andrei Warkentin <andreiw@motorola.com> wrote: > > Arnd, > > > > Yes, this is a Toshiba card. I've sent the patch as a reply to Linus' email. > > > > cid - 02010053454d3332479070cc51451d00 > > csd - d00f00320f5903ffffffffff92404000 > > erase_size - 524288 > > fwrev - 0x0 > > hwrev - 0x0 > > manfid - 0x000002 > > name - SEM32G > > oemid - 0x0100 > > preferred_erase_size - 2097152 > > > > Ok. Big mistake. Sorry about that. This card is Sandisk card. I got > confused over all the manfids changing. > > Here is the Toshiba card: > > cid - 1101004d4d4333324703101a17746d00 > csd - 900e00320f5903ffffffffe796400000 > erase_size - 524288 > fwrev - 0x0 > hwrev - 0x0 > manfid - 0x000011 > name - MMC32G > oemid - 0x0100 > preferred_erase_size - 4194304 > > I'll get you the flashbench timings for both. I'm curious. Neither the manfid nor the oemid fields of either card match what I have seen on SD cards, I would expect them to be Sandisk: manfid 0x000003, oemid 0x5344 Toshiba: manfid 0x000002, oemid 0x544d I have not actually seen any Toshiba SD cards, but I assume that they use the same controllers as Kingston. Does anyone know if the IDs have any correlation between MMC and SD controllers? Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-18 13:44 ` Arnd Bergmann @ 2011-02-18 19:47 ` Andrei Warkentin -1 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-18 19:47 UTC (permalink / raw) To: Arnd Bergmann; +Cc: linux-arm-kernel, Linus Walleij, linux-mmc On Fri, Feb 18, 2011 at 7:44 AM, Arnd Bergmann <arnd@arndb.de> wrote: > I'm curious. Neither the manfid nor the oemid fields of either card > match what I have seen on SD cards, I would expect them to be > > Sandisk: manfid 0x000003, oemid 0x5344 > Toshiba: manfid 0x000002, oemid 0x544d > > I have not actually seen any Toshiba SD cards, but I assume that they > use the same controllers as Kingston. > > Does anyone know if the IDs have any correlation between MMC and SD > controllers? > > Arnd > I'm unsure about the older scheme (assigned by MMCA), but ever since MMC is now JEDEC-controlled, the IDs have changed. Sandisk's new id will be 0x45, and Toshiba I guess will be 0x11. ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-18 19:47 ` Andrei Warkentin 0 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-18 19:47 UTC (permalink / raw) To: linux-arm-kernel On Fri, Feb 18, 2011 at 7:44 AM, Arnd Bergmann <arnd@arndb.de> wrote: > I'm curious. Neither the manfid nor the oemid fields of either card > match what I have seen on SD cards, I would expect them to be > > Sandisk: manfid 0x000003, oemid 0x5344 > Toshiba: manfid 0x000002, oemid 0x544d > > I have not actually seen any Toshiba SD cards, but I assume that they > use the same controllers as Kingston. > > Does anyone know if the IDs have any correlation between MMC and SD > controllers? > > ? ? ? ?Arnd > I'm unsure about the older scheme (assigned by MMCA), but ever since MMC is now JEDEC-controlled, the IDs have changed. Sandisk's new id will be 0x45, and Toshiba I guess will be 0x11. ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-18 19:47 ` Andrei Warkentin @ 2011-02-18 22:40 ` Andrei Warkentin -1 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-18 22:40 UTC (permalink / raw) To: Arnd Bergmann; +Cc: linux-arm-kernel, Linus Walleij, linux-mmc [-- Attachment #1: Type: text/plain, Size: 2014 bytes --] On Fri, Feb 18, 2011 at 1:47 PM, Andrei Warkentin <andreiw@motorola.com> wrote: > On Fri, Feb 18, 2011 at 7:44 AM, Arnd Bergmann <arnd@arndb.de> wrote: >> I'm curious. Neither the manfid nor the oemid fields of either card >> match what I have seen on SD cards, I would expect them to be >> >> Sandisk: manfid 0x000003, oemid 0x5344 >> Toshiba: manfid 0x000002, oemid 0x544d >> >> I have not actually seen any Toshiba SD cards, but I assume that they >> use the same controllers as Kingston. >> >> Does anyone know if the IDs have any correlation between MMC and SD >> controllers? >> >> Arnd >> > > I'm unsure about the older scheme (assigned by MMCA), but ever since > MMC is now JEDEC-controlled, the IDs have changed. Sandisk's new id > will be 0x45, and Toshiba I guess will be 0x11. > Flashbench timings for both Sandisk and Toshiba cards. Attaching due to size. Some interesting things that I don't understand. For the align test, I extended it to do a write align test (-A). I tried two partitions that I could write over, and both read and writes behaved differently for the two partitions on same device. Odd. They are both 4MB aligned. On the sandisk it was the write align that made the page size stand out. The read align had pretty constant results. On the toshiba the results varied wildly for the two partitions. For partition 6, there was a clear pattern in the diff values for read align. For 9, it was all over the place. For 9 with the write align, 8K and 16K the crossing writes took ~115ms!! Look in attached files for all the data. The AU tests were interesting too, especially how with several open AUs the throughput is higher for certain smaller sizes on sandisk, but if I interpret it correctly both cards have at least 4 AUs, as I didn't see yet a significant drop for small sizes. The larger ones I am running now on mmcblk0p9 which is sufficiently larger for these tests... (mmcblk0p6 is only 40mb, p9 is 314 mb) Thanks, A [-- Attachment #2: toshiba.txt --] [-- Type: text/plain, Size: 5447 bytes --] /data # cat /sys/block/mmcblk0/device/block/mmcblk0/mmcblk0p9/start 643072 /data # cat /sys/block/mmcblk0/device/block/mmcblk0/mmcblk0p9/size 346112 /data # cat /sys/block/mmcblk0/device/block/mmcblk0/mmcblk0p6/start 77824 /data # cat /sys/block/mmcblk0/device/block/mmcblk0/mmcblk0p6/size 24576 # ./flashbench -a -b 1024 /dev/block/mmcblk0p6 align 524288 pre 613µs on 801µs post 570µs diff 210µs align 262144 pre 739µs on 988µs post 767µs diff 235µs align 131072 pre 740µs on 990µs post 767µs diff 236µs align 65536 pre 749µs on 998µs post 767µs diff 240µs align 32768 pre 761µs on 992µs post 746µs diff 238µs align 16384 pre 755µs on 982µs post 755µs diff 227µs align 8192 pre 748µs on 750µs post 748µs diff 1.94µs align 4096 pre 747µs on 749µs post 747µs diff 1.41µs align 2048 pre 747µs on 747µs post 748µs diff -93ns # ./flashbench -a -b 1024 /dev/block/mmcblk0p9 align 8388608 pre 527µs on 743µs post 476µs diff 242µs align 4194304 pre 544µs on 730µs post 543µs diff 187µs align 2097152 pre 551µs on 714µs post 485µs diff 196µs align 1048576 pre 742µs on 864µs post 745µs diff 120µs align 524288 pre 760µs on 822µs post 789µs diff 47.9µs align 262144 pre 760µs on 816µs post 789µs diff 42µs align 131072 pre 760µs on 822µs post 789µs diff 47.8µs align 65536 pre 758µs on 821µs post 789µs diff 48µs align 32768 pre 771µs on 828µs post 760µs diff 62.7µs align 16384 pre 672µs on 939µs post 771µs diff 217µs align 8192 pre 668µs on 806µs post 671µs diff 136µs align 4096 pre 671µs on 672µs post 670µs diff 1.5µs align 2048 pre 671µs on 670µs post 671µs diff -859ns # ./flashbench -A -b 1024 /dev/block/mmcblk0p6 write align 524288 pre 3.59ms on 6.74ms post 3.73ms diff 3.08ms write align 262144 pre 3.69ms on 7.11ms post 3.69ms diff 3.42ms write align 131072 pre 3.71ms on 17.4ms post 3.72ms diff 13.7ms write align 65536 pre 3.72ms on 7.18ms post 3.52ms diff 3.56ms write align 32768 pre 3.73ms on 11.9ms post 3.7ms diff 8.24ms write align 16384 pre 3.93ms on 5.01ms post 4.6ms diff 745µs write align 8192 pre 4.9ms on 4.89ms post 4.87ms diff 4.77µs write align 4096 pre 5.03ms on 5.02ms post 5.01ms diff -437ns write align 2048 pre 5.08ms on 5.08ms post 5.06ms diff 12.3µs # ./flashbench -A -b 1024 /dev/block/mmcblk0p9 write align 8388608 pre 3.76ms on 7.07ms post 4.05ms diff 3.16ms write align 4194304 pre 3.62ms on 6.5ms post 3.63ms diff 2.88ms write align 2097152 pre 3.91ms on 6.84ms post 3.7ms diff 3.04ms write align 1048576 pre 3.88ms on 6.96ms post 3.96ms diff 3.04ms write align 524288 pre 3.93ms on 7.07ms post 4.05ms diff 3.08ms write align 262144 pre 3.94ms on 7.07ms post 4.05ms diff 3.07ms write align 131072 pre 3.95ms on 7.05ms post 4.05ms diff 3.05ms write align 65536 pre 3.94ms on 7.07ms post 4.05ms diff 3.07ms write align 32768 pre 3.95ms on 7.07ms post 4.04ms diff 3.07ms write align 16384 pre 4.48ms on 117ms post 3.81ms diff 113ms write align 8192 pre 3.61ms on 114ms post 3.58ms diff 110ms write align 4096 pre 3.88ms on 3.87ms post 3.86ms diff 1.87µs write align 2048 pre 3.88ms on 3.89ms post 3.89ms diff 3.11µs ./flashbench -O -0 1 -b 512 /dev/block/mmcblk0p6 4MiB 7.17M/s 2MiB 7.91M/s 1MiB 9.23M/s 512KiB 10.3M/s 256KiB 10.5M/s 128KiB 10.4M/s 64KiB 9.81M/s 32KiB 9.09M/s 16KiB 3.71M/s 8KiB 1.73M/s 4KiB 845K/s 2KiB 418K/s 1KiB 208K/s 512B 103K/s ./flashbench -O -0 1 -r -b 512 /dev/block/mmcblk0p6 4MiB 6.58M/s 2MiB 7.98M/s 1MiB 9.33M/s 512KiB 10.4M/s 256KiB 10.9M/s 128KiB 10.5M/s 64KiB 9.94M/s 32KiB 9.11M/s 16KiB 3.72M/s 8KiB 1.75M/s 4KiB 853K/s 2KiB 419K/s 1KiB 207K/s 512B 102K/s ./flashbench -O -0 2 -b 512 /dev/block/mmcblk0p6 4MiB 8.95M/s 2MiB 9.44M/s 1MiB 10.3M/s 512KiB 10.9M/s 256KiB 10.8M/s 128KiB 10.5M/s 64KiB 9.91M/s 32KiB 8.79M/s 16KiB 3.65M/s 8KiB 1.75M/s 4KiB 851K/s 2KiB 419K/s 1KiB 208K/s 512B 103K/s ./flashbench -O -0 2 -r -b 512 /dev/block/mmcblk0p6 4MiB 9.06M/s 2MiB 9.68M/s 1MiB 10.3M/s 512KiB 10.5M/s 256KiB 9.94M/s 128KiB 10.1M/s 64KiB 9.41M/s 32KiB 7.99M/s 16KiB 3.5M/s 8KiB 1.64M/s 4KiB 798K/s 2KiB 393K/s 1KiB 196K/s 512B 96.5K/s ./flashbench -O -0 3 -b 512 /dev/block/mmcblk0p6 4MiB 8.07M/s 2MiB 9.07M/s 1MiB 9.88M/s 512KiB 10.1M/s 256KiB 10M/s 128KiB 9.83M/s 64KiB 8.68M/s 32KiB 7.1M/s 16KiB 3.09M/s 8KiB 1.49M/s 4KiB 726K/s 2KiB 357K/s 1KiB 178K/s 512B 88.5K/s ./flashbench -O -0 3 -r -b 512 /dev/block/mmcblk0p6 4MiB 8.12M/s 2MiB 9.28M/s 1MiB 9.83M/s 512KiB 10M/s 256KiB 9.97M/s 128KiB 9.91M/s 64KiB 8.9M/s 32KiB 7.3M/s 16KiB 3.2M/s 8KiB 1.54M/s 4KiB 751K/s 2KiB 367K/s 1KiB 183K/s 512B 90.3K/s ./flashbench -O -0 4 -b 512 /dev/block/mmcblk0p6 4MiB 5.87M/s 2MiB 8.71M/s 1MiB 9.11M/s 512KiB 10.3M/s 256KiB 10.5M/s 128KiB 10M/s 64KiB 9.09M/s 32KiB 7.5M/s 16KiB 3.28M/s 8KiB 1.56M/s 4KiB 758K/s 2KiB 372K/s 1KiB 185K/s 512B 92.3K/s ./flashbench -O -0 4 -r -b 512 /dev/block/mmcblk0p6 4MiB 7.57M/s 2MiB 7.23M/s 1MiB 9.71M/s 512KiB 10M/s 256KiB 9.98M/s 128KiB 9.82M/s 64KiB 9.07M/s 32KiB 7.62M/s 16KiB 3.34M/s 8KiB 1.58M/s 4KiB 776K/s 2KiB 379K/s 1KiB 188K/s 512B 92.7K/s [-- Attachment #3: sandisk.txt --] [-- Type: text/plain, Size: 5529 bytes --] /data # cat /sys/block/mmcblk0/device/block/mmcblk0/mmcblk0p9/start 647168 /data # cat /sys/block/mmcblk0/device/block/mmcblk0/mmcblk0p9/size 346112 /data # cat /sys/block/mmcblk0/device/block/mmcblk0/mmcblk0p6/start 81920 /data # cat /sys/block/mmcblk0/device/block/mmcblk0/mmcblk0p6/size 24576 /data # ./flashbench -a -b 1024 /dev/block/mmcblk0p6 align 524288 pre 1.01ms on 1.03ms post 858µs diff 93.5µs align 262144 pre 1.16ms on 1.2ms post 926µs diff 153µs align 131072 pre 1.16ms on 1.2ms post 924µs diff 151µs align 65536 pre 1.15ms on 1.12ms post 919µs diff 84.9µs align 32768 pre 1.16ms on 1.2ms post 923µs diff 154µs align 16384 pre 1.16ms on 1.21ms post 941µs diff 162µs align 8192 pre 1.15ms on 1.09ms post 874µs diff 80.2µs align 4096 pre 1.16ms on 1.17ms post 902µs diff 138µs align 2048 pre 1.16ms on 1.17ms post 903µs diff 135µs /data # ./flashbench -a -b 1024 /dev/block/mmcblk0p9 align 8388608 pre 1.07ms on 1.1ms post 933µs diff 92.9µs align 4194304 pre 1.28ms on 1.29ms post 1.05ms diff 129µs align 2097152 pre 1.28ms on 1.31ms post 1.07ms diff 132µs align 1048576 pre 1.27ms on 1.32ms post 1.07ms diff 147µs align 524288 pre 1.38ms on 1.38ms post 1.12ms diff 135µs align 262144 pre 1.27ms on 1.3ms post 1.04ms diff 140µs align 131072 pre 1.28ms on 1.31ms post 1.02ms diff 164µs align 65536 pre 1.38ms on 1.38ms post 1.12ms diff 135µs align 32768 pre 1.38ms on 1.38ms post 1.12ms diff 134µs align 16384 pre 1.38ms on 1.38ms post 1.11ms diff 135µs align 8192 pre 1.38ms on 1.38ms post 1.11ms diff 134µs align 4096 pre 1.38ms on 1.38ms post 1.11ms diff 136µs align 2048 pre 1.38ms on 1.38ms post 1.11ms diff 134µs /data # ./flashbench -A -b 1024 /dev/block/mmcblk0p6 write align 524288 pre 1.69ms on 2.38ms post 1.78ms diff 653µs write align 262144 pre 1.87ms on 2.59ms post 1.86ms diff 723µs write align 131072 pre 1.88ms on 2.61ms post 1.89ms diff 729µs write align 65536 pre 1.86ms on 2.65ms post 1.83ms diff 805µs write align 32768 pre 1.88ms on 2.61ms post 1.92ms diff 710µs write align 16384 pre 1.8ms on 2.57ms post 1.95ms diff 701µs write align 8192 pre 1.66ms on 1.71ms post 1.64ms diff 55µs write align 4096 pre 1.67ms on 1.71ms post 1.64ms diff 51.9µs write align 2048 pre 1.67ms on 1.71ms post 1.61ms diff 68.7µs /data # ./flashbench -A -b 1024 /dev/block/mmcblk0p9 write align 8388608 pre 1.83ms on 2.62ms post 1.91ms diff 750µs write align 4194304 pre 1.89ms on 2.87ms post 2.06ms diff 892µs write align 2097152 pre 2.08ms on 2.86ms post 2.13ms diff 751µs write align 1048576 pre 2.06ms on 2.93ms post 2.17ms diff 818µs write align 524288 pre 2.07ms on 2.85ms post 2.18ms diff 724µs write align 262144 pre 2.07ms on 2.85ms post 2.15ms diff 741µs write align 131072 pre 2.05ms on 2.93ms post 2.19ms diff 809µs write align 65536 pre 1.86ms on 2.77ms post 1.9ms diff 888µs write align 32768 pre 2.06ms on 2.91ms post 2.19ms diff 783µs write align 16384 pre 2.05ms on 2.76ms post 1.8ms diff 835µs write align 8192 pre 1.83ms on 1.89ms post 1.8ms diff 72.9µs write align 4096 pre 1.84ms on 1.9ms post 1.8ms diff 75µs write align 2048 pre 1.84ms on 1.89ms post 1.8ms diff 70.8µs /data # ./flashbench -O -0 1 -b 512 /dev/block/mmcblk0p6 4MiB 10.5M/s 2MiB 10.1M/s 1MiB 10.6M/s 512KiB 10.5M/s 256KiB 8.94M/s 128KiB 7.74M/s 64KiB 6.04M/s 32KiB 4.13M/s 16KiB 3.2M/s 8KiB 3.87M/s 4KiB 1.86M/s 2KiB 1.16M/s 1KiB 667K/s 512B 396K/s /data # ./flashbench -O -0 1 -r -b 512 /dev/block/mmcblk0p6 4MiB 10.7M/s 2MiB 10.3M/s 1MiB 10.4M/s 512KiB 16.3M/s 256KiB 16.6M/s 128KiB 16.1M/s 64KiB 14M/s 32KiB 11.1M/s 16KiB 6.77M/s 8KiB 3.15M/s 4KiB 1.77M/s 2KiB 1.01M/s 1KiB 523K/s 512B 296K/s /data # ./flashbench -O -0 2 -b 512 /dev/block/mmcblk0p6 4MiB 11.5M/s 2MiB 11.3M/s 1MiB 11.5M/s 512KiB 11.6M/s 256KiB 10.8M/s 128KiB 9.84M/s 64KiB 7.88M/s 32KiB 5.65M/s 16KiB 4.14M/s 8KiB 1.99M/s 4KiB 1.42M/s 2KiB 760K/s 1KiB 392K/s 512B 213K/s /data # ./flashbench -O -0 2 -r -b 512 /dev/block/mmcblk0p6 4MiB 10.3M/s 2MiB 10.2M/s 1MiB 10.1M/s 512KiB 16M/s 256KiB 15.8M/s 128KiB 14.6M/s 64KiB 11.4M/s 32KiB 8.07M/s 16KiB 5.12M/s 8KiB 2.65M/s 4KiB 1.43M/s 2KiB 768K/s 1KiB 395K/s 512B 212K/s /data # ./flashbench -O -0 3 -b 512 /dev/block/mmcblk0p6 4MiB 11.3M/s 2MiB 11.5M/s 1MiB 11.5M/s 512KiB 11.5M/s 256KiB 10.4M/s 128KiB 9.1M/s 64KiB 7.3M/s 32KiB 5.21M/s 16KiB 3.78M/s 8KiB 2.08M/s 4KiB 1.42M/s 2KiB 792K/s 1KiB 418K/s 512B 217K/s /data/flashbench -O -0 3 -r -b 512 /dev/block/mmcblk0p6 4MiB 10.7M/s 2MiB 10.5M/s 1MiB 10.2M/s 512KiB 17.3M/s 256KiB 16.3M/s 128KiB 14.5M/s 64KiB 11.4M/s 32KiB 8.12M/s 16KiB 4.98M/s 8KiB 2.62M/s 4KiB 1.4M/s 2KiB 768K/s 1KiB 390K/s 512B 212K/s ./flashbench -O -0 4 -b 512 /dev/block/mmcblk0p6 4MiB 14.4M/s 2MiB 14M/s 1MiB 13.9M/s 512KiB 14.2M/s 256KiB 13.5M/s 128KiB 11.9M/s 64KiB 9.8M/s 32KiB 7.35M/s 16KiB 5.1M/s 8KiB 2.69M/s 4KiB 1.58M/s 2KiB 877K/s 1KiB 476K/s 512B 268K/s ./flashbench -O -0 4 -r -b 512 /dev/block/mmcblk0p6 4MiB 10.4M/s 2MiB 10.5M/s 1MiB 14.3M/s 512KiB 17.7M/s 256KiB 16.9M/s 128KiB 15.5M/s 64KiB 12.4M/s 32KiB 9.36M/s 16KiB 5.62M/s 8KiB 3M/s 4KiB 1.62M/s 2KiB 880K/s 1KiB 462K/s 512B 261K/s ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-18 22:40 ` Andrei Warkentin 0 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-18 22:40 UTC (permalink / raw) To: linux-arm-kernel On Fri, Feb 18, 2011 at 1:47 PM, Andrei Warkentin <andreiw@motorola.com> wrote: > On Fri, Feb 18, 2011 at 7:44 AM, Arnd Bergmann <arnd@arndb.de> wrote: >> I'm curious. Neither the manfid nor the oemid fields of either card >> match what I have seen on SD cards, I would expect them to be >> >> Sandisk: manfid 0x000003, oemid 0x5344 >> Toshiba: manfid 0x000002, oemid 0x544d >> >> I have not actually seen any Toshiba SD cards, but I assume that they >> use the same controllers as Kingston. >> >> Does anyone know if the IDs have any correlation between MMC and SD >> controllers? >> >> ? ? ? ?Arnd >> > > I'm unsure about the older scheme (assigned by MMCA), but ever since > MMC is now JEDEC-controlled, the IDs have changed. Sandisk's new id > will be 0x45, and Toshiba I guess will be 0x11. > Flashbench timings for both Sandisk and Toshiba cards. Attaching due to size. Some interesting things that I don't understand. For the align test, I extended it to do a write align test (-A). I tried two partitions that I could write over, and both read and writes behaved differently for the two partitions on same device. Odd. They are both 4MB aligned. On the sandisk it was the write align that made the page size stand out. The read align had pretty constant results. On the toshiba the results varied wildly for the two partitions. For partition 6, there was a clear pattern in the diff values for read align. For 9, it was all over the place. For 9 with the write align, 8K and 16K the crossing writes took ~115ms!! Look in attached files for all the data. The AU tests were interesting too, especially how with several open AUs the throughput is higher for certain smaller sizes on sandisk, but if I interpret it correctly both cards have at least 4 AUs, as I didn't see yet a significant drop for small sizes. The larger ones I am running now on mmcblk0p9 which is sufficiently larger for these tests... (mmcblk0p6 is only 40mb, p9 is 314 mb) Thanks, A -------------- next part -------------- An embedded and charset-unspecified text was scrubbed... Name: toshiba.txt URL: <http://lists.infradead.org/pipermail/linux-arm-kernel/attachments/20110218/3e560d5a/attachment.txt> -------------- next part -------------- An embedded and charset-unspecified text was scrubbed... Name: sandisk.txt URL: <http://lists.infradead.org/pipermail/linux-arm-kernel/attachments/20110218/3e560d5a/attachment-0001.txt> ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-18 22:40 ` Andrei Warkentin @ 2011-02-18 23:17 ` Andrei Warkentin -1 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-18 23:17 UTC (permalink / raw) To: Arnd Bergmann; +Cc: linux-arm-kernel, Linus Walleij, linux-mmc [-- Attachment #1: Type: text/plain, Size: 4240 bytes --] 2011/2/18 Andrei Warkentin <andreiw@motorola.com>: > On Fri, Feb 18, 2011 at 1:47 PM, Andrei Warkentin <andreiw@motorola.com> wrote: >> On Fri, Feb 18, 2011 at 7:44 AM, Arnd Bergmann <arnd@arndb.de> wrote: >>> I'm curious. Neither the manfid nor the oemid fields of either card >>> match what I have seen on SD cards, I would expect them to be >>> >>> Sandisk: manfid 0x000003, oemid 0x5344 >>> Toshiba: manfid 0x000002, oemid 0x544d >>> >>> I have not actually seen any Toshiba SD cards, but I assume that they >>> use the same controllers as Kingston. >>> >>> Does anyone know if the IDs have any correlation between MMC and SD >>> controllers? >>> >>> Arnd >>> >> >> I'm unsure about the older scheme (assigned by MMCA), but ever since >> MMC is now JEDEC-controlled, the IDs have changed. Sandisk's new id >> will be 0x45, and Toshiba I guess will be 0x11. >> > > Flashbench timings for both Sandisk and Toshiba cards. Attaching due to size. > > Some interesting things that I don't understand. For the align test, I > extended it to do a write align test (-A). I tried two partitions that > I could write over, and both read and writes behaved differently for > the two partitions on same device. Odd. They are both 4MB aligned. > > On the sandisk it was the write align that made the page size stand > out. The read align had pretty constant results. > > On the toshiba the results varied wildly for the two partitions. For > partition 6, there was a clear pattern in the diff values for read > align. For 9, it was all over the place. For 9 with the write align, > 8K and 16K the crossing writes took ~115ms!! Look in attached files > for all the data. > > The AU tests were interesting too, especially how with several open > AUs the throughput is higher for certain smaller sizes on sandisk, but > if I interpret it correctly both cards have at least 4 AUs, as I > didn't see yet a significant drop for small sizes. The larger ones I > am running now on mmcblk0p9 which is sufficiently larger for these > tests... (mmcblk0p6 is only 40mb, p9 is 314 mb) > > Thanks, > A > I thought this was pretty interesting - # echo 0 > /sys/block/mmcblk0/device/page_size # ./flashbench -A -b 1024 /dev/block/mmcblk0p9 write align 8388608 pre 3.59ms on 6.54ms post 3.65ms diff 2.92ms write align 4194304 pre 4.13ms on 7.37ms post 4.27ms diff 3.17ms write align 2097152 pre 3.62ms on 6.81ms post 3.94ms diff 3.03ms write align 1048576 pre 3.62ms on 6.53ms post 3.55ms diff 2.95ms write align 524288 pre 3.62ms on 6.51ms post 3.63ms diff 2.88ms write align 262144 pre 3.62ms on 6.51ms post 3.63ms diff 2.89ms write align 131072 pre 3.62ms on 6.5ms post 3.63ms diff 2.88ms write align 65536 pre 3.61ms on 6.49ms post 3.62ms diff 2.88ms write align 32768 pre 3.61ms on 6.49ms post 3.61ms diff 2.88ms write align 16384 pre 3.68ms on 107ms post 3.51ms diff 103ms write align 8192 pre 3.74ms on 121ms post 3.91ms diff 117ms write align 4096 pre 3.88ms on 3.87ms post 3.87ms diff -2937ns write align 2048 pre 3.89ms on 3.88ms post 3.88ms diff -8734ns # fjnh84@fjnh84-desktop:~/src/n/src/flash$ adb -s 17006185428011d7 shell # echo 8192 > /sys/block/mmcblk0/device/page_size # cd data # ./flashbench -A -b 1024 /dev/block/mmcblk0p9 write align 8388608 pre 3.33ms on 6.8ms post 3.65ms diff 3.31ms write align 4194304 pre 4.34ms on 8.14ms post 4.53ms diff 3.71ms write align 2097152 pre 3.64ms on 7.31ms post 4.09ms diff 3.44ms write align 1048576 pre 3.65ms on 7.52ms post 3.65ms diff 3.87ms write align 524288 pre 3.62ms on 6.8ms post 3.63ms diff 3.17ms write align 262144 pre 3.62ms on 6.84ms post 3.63ms diff 3.22ms write align 131072 pre 3.62ms on 6.85ms post 3.44ms diff 3.32ms write align 65536 pre 3.39ms on 6.8ms post 3.66ms diff 3.28ms write align 32768 pre 3.64ms on 6.86ms post 3.66ms diff 3.21ms write align 16384 pre 3.67ms on 6.86ms post 3.65ms diff 3.2ms write align 8192 pre 3.66ms on 6.84ms post 3.64ms diff 3.19ms write align 4096 pre 3.71ms on 3.71ms post 3.64ms diff 38.6µs write align 2048 pre 3.71ms on 3.71ms post 3.72ms diff -656ns This was with the split unaligned accesses patch... Which I am attaching for comments. Thanks, A [-- Attachment #2: 0001-MMC-Split-non-page-size-aligned-accesses.patch --] [-- Type: text/x-diff, Size: 5196 bytes --] From b3e6a556a716e7cec86071342197e798b38c3cbf Mon Sep 17 00:00:00 2001 From: Andrei Warkentin <andreiw@motorola.com> Date: Fri, 18 Feb 2011 17:46:00 -0600 Subject: [PATCH] MMC: Split non-page-size aligned accesses. If the card page size is known, splits the access into an unaligned and an aligned portion, which helps with the performance. Change-Id: I4ad7588d613d775212fac87436e418577909a22b Signed-off-by: Andrei Warkentin <andreiw@motorola.com> --- drivers/mmc/card/block.c | 111 ++++++++++++++++++++++++++++++++++++++++++++++ include/linux/mmc/card.h | 1 + 2 files changed, 112 insertions(+), 0 deletions(-) diff --git a/drivers/mmc/card/block.c b/drivers/mmc/card/block.c index 7054fd5..be7d739 100644 --- a/drivers/mmc/card/block.c +++ b/drivers/mmc/card/block.c @@ -22,6 +22,7 @@ #include <linux/init.h> #include <linux/kernel.h> +#include <linux/ctype.h> #include <linux/fs.h> #include <linux/slab.h> #include <linux/errno.h> @@ -67,6 +68,74 @@ struct mmc_blk_data { static DEFINE_MUTEX(open_lock); +static ssize_t +show_block_attr(struct device *dev, struct device_attribute *attr, + char *buf); + +static ssize_t +set_block_attr(struct device *dev, struct device_attribute *attr, + const char *buf, size_t count); + +static DEVICE_ATTR(page_size, S_IRUGO | S_IWUSR, show_block_attr, set_block_attr); + +static ssize_t +show_block_attr(struct device *dev, struct device_attribute *attr, + char *buf) +{ + unsigned int val; + ssize_t ret = 0; + struct mmc_card *card = container_of(dev, struct mmc_card, dev); + mmc_claim_host(card->host); + if (attr == &dev_attr_page_size) + val = card->page_size; + else + ret = -EINVAL; + + mmc_release_host(card->host); + if (!ret) + ret = sprintf(buf, "%u\n", val); + return ret; +} + +static ssize_t +set_block_attr(struct device *dev, struct device_attribute *attr, + const char *buf, size_t count) +{ + ssize_t ret; + char *after; + unsigned int val, *dest = NULL; + struct mmc_card *card = container_of(dev, struct mmc_card, dev); + val = simple_strtoul(buf, &after, 10); + ret = after - buf; + + while (isspace(*after++)) + ret++; + + if (ret != count) + return -EINVAL; + + if (attr == &dev_attr_page_size) + dest = &card->page_size; + else + return -EINVAL; + + if (dest) { + mmc_claim_host(card->host); + *dest = val; + mmc_release_host(card->host); + } + return ret; +} + +static struct attribute *capability_attrs[] = { + &dev_attr_page_size.attr, + NULL, +}; + +static struct attribute_group attr_group = { + .attrs = capability_attrs, +}; + static struct mmc_blk_data *mmc_blk_get(struct gendisk *disk) { struct mmc_blk_data *md; @@ -312,6 +381,38 @@ out: return err ? 0 : 1; } + +/* + * If the request is not aligned, split it into an unaligned + * and an aligned portion. Here we can adjust + * the size of the MMC request and let the block layer request handle + * deal with generating another MMC request. + */ +static bool mmc_adjust_write(struct mmc_card *card, + struct mmc_request *mrq) +{ + unsigned int left_in_page; + unsigned int page_size_blocks; + + if (!card->page_size) + return false; + + page_size_blocks = card->page_size / mrq->data->blksz; + left_in_page = page_size_blocks - + (mrq->cmd->arg % page_size_blocks); + + /* Aligned access. */ + if (left_in_page == page_size_blocks) + return false; + + /* Not straddling page boundary. */ + if (mrq->data->blocks <= left_in_page) + return false; + + mrq->data->blocks = left_in_page; + return true; +} + static int mmc_blk_issue_rw_rq(struct mmc_queue *mq, struct request *req) { struct mmc_blk_data *md = mq->data; @@ -339,6 +440,10 @@ static int mmc_blk_issue_rw_rq(struct mmc_queue *mq, struct request *req) brq.stop.flags = MMC_RSP_SPI_R1B | MMC_RSP_R1B | MMC_CMD_AC; brq.data.blocks = blk_rq_sectors(req); + /* Check for unaligned accesses straddling pages. */ + if (rq_data_dir(req) == WRITE) + mmc_adjust_write(card, &brq.mrq); + /* * The block layer doesn't support all sector count * restrictions, so we need to be prepared for too big @@ -707,6 +812,10 @@ static int mmc_blk_probe(struct mmc_card *card) if (err) goto out; + err = sysfs_create_group(&card->dev.kobj, &attr_group); + if (err) + goto out; + string_get_size((u64)get_capacity(md->disk) << 9, STRING_UNITS_2, cap_str, sizeof(cap_str)); printk(KERN_INFO "%s: %s %s %s %s\n", @@ -735,6 +844,8 @@ static void mmc_blk_remove(struct mmc_card *card) /* Stop new requests from getting into the queue */ del_gendisk(md->disk); + sysfs_remove_group(&card->dev.kobj, &attr_group); + /* Then flush out any already in there */ mmc_cleanup_queue(&md->queue); diff --git a/include/linux/mmc/card.h b/include/linux/mmc/card.h index 6b75250..d52768a 100644 --- a/include/linux/mmc/card.h +++ b/include/linux/mmc/card.h @@ -123,7 +123,7 @@ struct mmc_card { unsigned int erase_size; /* erase size in sectors */ unsigned int erase_shift; /* if erase unit is power 2 */ unsigned int pref_erase; /* in sectors */ + unsigned int page_size; /* page size in bytes */ u8 erased_byte; /* value of erased bytes */ u32 raw_cid[4]; /* raw card CID */ -- 1.7.0.4 ^ permalink raw reply related [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-18 23:17 ` Andrei Warkentin 0 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-18 23:17 UTC (permalink / raw) To: linux-arm-kernel 2011/2/18 Andrei Warkentin <andreiw@motorola.com>: > On Fri, Feb 18, 2011 at 1:47 PM, Andrei Warkentin <andreiw@motorola.com> wrote: >> On Fri, Feb 18, 2011 at 7:44 AM, Arnd Bergmann <arnd@arndb.de> wrote: >>> I'm curious. Neither the manfid nor the oemid fields of either card >>> match what I have seen on SD cards, I would expect them to be >>> >>> Sandisk: manfid 0x000003, oemid 0x5344 >>> Toshiba: manfid 0x000002, oemid 0x544d >>> >>> I have not actually seen any Toshiba SD cards, but I assume that they >>> use the same controllers as Kingston. >>> >>> Does anyone know if the IDs have any correlation between MMC and SD >>> controllers? >>> >>> ? ? ? ?Arnd >>> >> >> I'm unsure about the older scheme (assigned by MMCA), but ever since >> MMC is now JEDEC-controlled, the IDs have changed. Sandisk's new id >> will be 0x45, and Toshiba I guess will be 0x11. >> > > Flashbench timings for both Sandisk and Toshiba cards. Attaching due to size. > > Some interesting things that I don't understand. For the align test, I > extended it to do a write align test (-A). I tried two partitions that > I could write over, and both read and writes behaved differently for > the two partitions on same device. Odd. They are both 4MB aligned. > > On the sandisk it was the write align that made the page size stand > out. ?The read align had pretty constant results. > > On the toshiba the results varied wildly for the two partitions. For > partition 6, there was a clear pattern in the diff values for read > align. For 9, it was all over the place. For 9 with the write align, > 8K and 16K the crossing writes took ~115ms!! Look in attached files > for all the data. > > The AU tests were interesting too, especially how with several open > AUs the throughput is higher for certain smaller sizes on sandisk, but > if I interpret it correctly both cards have at least 4 AUs, as I > didn't see yet a significant drop for small sizes. The larger ones I > am running now on mmcblk0p9 which is sufficiently larger for these > tests... (mmcblk0p6 is only 40mb, p9 is 314 mb) > > Thanks, > A > I thought this was pretty interesting - # echo 0 > /sys/block/mmcblk0/device/page_size # ./flashbench -A -b 1024 /dev/block/mmcblk0p9 write align 8388608 pre 3.59ms on 6.54ms post 3.65ms diff 2.92ms write align 4194304 pre 4.13ms on 7.37ms post 4.27ms diff 3.17ms write align 2097152 pre 3.62ms on 6.81ms post 3.94ms diff 3.03ms write align 1048576 pre 3.62ms on 6.53ms post 3.55ms diff 2.95ms write align 524288 pre 3.62ms on 6.51ms post 3.63ms diff 2.88ms write align 262144 pre 3.62ms on 6.51ms post 3.63ms diff 2.89ms write align 131072 pre 3.62ms on 6.5ms post 3.63ms diff 2.88ms write align 65536 pre 3.61ms on 6.49ms post 3.62ms diff 2.88ms write align 32768 pre 3.61ms on 6.49ms post 3.61ms diff 2.88ms write align 16384 pre 3.68ms on 107ms post 3.51ms diff 103ms write align 8192 pre 3.74ms on 121ms post 3.91ms diff 117ms write align 4096 pre 3.88ms on 3.87ms post 3.87ms diff -2937ns write align 2048 pre 3.89ms on 3.88ms post 3.88ms diff -8734ns # fjnh84 at fjnh84-desktop:~/src/n/src/flash$ adb -s 17006185428011d7 shell # echo 8192 > /sys/block/mmcblk0/device/page_size # cd data # ./flashbench -A -b 1024 /dev/block/mmcblk0p9 write align 8388608 pre 3.33ms on 6.8ms post 3.65ms diff 3.31ms write align 4194304 pre 4.34ms on 8.14ms post 4.53ms diff 3.71ms write align 2097152 pre 3.64ms on 7.31ms post 4.09ms diff 3.44ms write align 1048576 pre 3.65ms on 7.52ms post 3.65ms diff 3.87ms write align 524288 pre 3.62ms on 6.8ms post 3.63ms diff 3.17ms write align 262144 pre 3.62ms on 6.84ms post 3.63ms diff 3.22ms write align 131072 pre 3.62ms on 6.85ms post 3.44ms diff 3.32ms write align 65536 pre 3.39ms on 6.8ms post 3.66ms diff 3.28ms write align 32768 pre 3.64ms on 6.86ms post 3.66ms diff 3.21ms write align 16384 pre 3.67ms on 6.86ms post 3.65ms diff 3.2ms write align 8192 pre 3.66ms on 6.84ms post 3.64ms diff 3.19ms write align 4096 pre 3.71ms on 3.71ms post 3.64ms diff 38.6?s write align 2048 pre 3.71ms on 3.71ms post 3.72ms diff -656ns This was with the split unaligned accesses patch... Which I am attaching for comments. Thanks, A -------------- next part -------------- A non-text attachment was scrubbed... Name: 0001-MMC-Split-non-page-size-aligned-accesses.patch Type: text/x-diff Size: 5195 bytes Desc: not available URL: <http://lists.infradead.org/pipermail/linux-arm-kernel/attachments/20110218/333fe63e/attachment-0001.bin> ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-18 23:17 ` Andrei Warkentin @ 2011-02-19 11:20 ` Arnd Bergmann -1 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-19 11:20 UTC (permalink / raw) To: Andrei Warkentin; +Cc: linux-arm-kernel, Linus Walleij, linux-mmc On Saturday 19 February 2011 00:17:51 Andrei Warkentin wrote: > # echo 0 > /sys/block/mmcblk0/device/page_size > # ./flashbench -A -b 1024 /dev/block/mmcblk0p9 > write align 8388608 pre 3.59ms on 6.54ms post 3.65ms diff 2.92ms > write align 4194304 pre 4.13ms on 7.37ms post 4.27ms diff 3.17ms > write align 2097152 pre 3.62ms on 6.81ms post 3.94ms diff 3.03ms > write align 1048576 pre 3.62ms on 6.53ms post 3.55ms diff 2.95ms > write align 524288 pre 3.62ms on 6.51ms post 3.63ms diff 2.88ms > write align 262144 pre 3.62ms on 6.51ms post 3.63ms diff 2.89ms > write align 131072 pre 3.62ms on 6.5ms post 3.63ms diff 2.88ms > write align 65536 pre 3.61ms on 6.49ms post 3.62ms diff 2.88ms > write align 32768 pre 3.61ms on 6.49ms post 3.61ms diff 2.88ms > write align 16384 pre 3.68ms on 107ms post 3.51ms diff 103ms > write align 8192 pre 3.74ms on 121ms post 3.91ms diff 117ms > write align 4096 pre 3.88ms on 3.87ms post 3.87ms diff -2937ns > write align 2048 pre 3.89ms on 3.88ms post 3.88ms diff -8734ns > # fjnh84@fjnh84-desktop:~/src/n/src/flash$ adb -s 17006185428011d7 shell > # echo 8192 > /sys/block/mmcblk0/device/page_size > # cd data > # ./flashbench -A -b 1024 /dev/block/mmcblk0p9 > write align 8388608 pre 3.33ms on 6.8ms post 3.65ms diff 3.31ms > write align 4194304 pre 4.34ms on 8.14ms post 4.53ms diff 3.71ms > write align 2097152 pre 3.64ms on 7.31ms post 4.09ms diff 3.44ms > write align 1048576 pre 3.65ms on 7.52ms post 3.65ms diff 3.87ms > write align 524288 pre 3.62ms on 6.8ms post 3.63ms diff 3.17ms > write align 262144 pre 3.62ms on 6.84ms post 3.63ms diff 3.22ms > write align 131072 pre 3.62ms on 6.85ms post 3.44ms diff 3.32ms > write align 65536 pre 3.39ms on 6.8ms post 3.66ms diff 3.28ms > write align 32768 pre 3.64ms on 6.86ms post 3.66ms diff 3.21ms > write align 16384 pre 3.67ms on 6.86ms post 3.65ms diff 3.2ms > write align 8192 pre 3.66ms on 6.84ms post 3.64ms diff 3.19ms > write align 4096 pre 3.71ms on 3.71ms post 3.64ms diff 38.6µs > write align 2048 pre 3.71ms on 3.71ms post 3.72ms diff -656ns > > This was with the split unaligned accesses patch... Which I am > attaching for comments. I agree, this is very fascinating behavior. 100ms second latency for a single 2KB access is definitely something we should try to avoid, and I wonder why the drive decides to do that. It must get into a state where it requires an extra garbage collection (you mentioned that earlier). The numbers you see here are taken over multiple runs. Do you see a lot of fluctuation when doing this with --count=1? Also, does the same happen with other blocksizes, e.g. 4096 or 8192, passed to flashbench? Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-19 11:20 ` Arnd Bergmann 0 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-19 11:20 UTC (permalink / raw) To: linux-arm-kernel On Saturday 19 February 2011 00:17:51 Andrei Warkentin wrote: > # echo 0 > /sys/block/mmcblk0/device/page_size > # ./flashbench -A -b 1024 /dev/block/mmcblk0p9 > write align 8388608 pre 3.59ms on 6.54ms post 3.65ms diff 2.92ms > write align 4194304 pre 4.13ms on 7.37ms post 4.27ms diff 3.17ms > write align 2097152 pre 3.62ms on 6.81ms post 3.94ms diff 3.03ms > write align 1048576 pre 3.62ms on 6.53ms post 3.55ms diff 2.95ms > write align 524288 pre 3.62ms on 6.51ms post 3.63ms diff 2.88ms > write align 262144 pre 3.62ms on 6.51ms post 3.63ms diff 2.89ms > write align 131072 pre 3.62ms on 6.5ms post 3.63ms diff 2.88ms > write align 65536 pre 3.61ms on 6.49ms post 3.62ms diff 2.88ms > write align 32768 pre 3.61ms on 6.49ms post 3.61ms diff 2.88ms > write align 16384 pre 3.68ms on 107ms post 3.51ms diff 103ms > write align 8192 pre 3.74ms on 121ms post 3.91ms diff 117ms > write align 4096 pre 3.88ms on 3.87ms post 3.87ms diff -2937ns > write align 2048 pre 3.89ms on 3.88ms post 3.88ms diff -8734ns > # fjnh84 at fjnh84-desktop:~/src/n/src/flash$ adb -s 17006185428011d7 shell > # echo 8192 > /sys/block/mmcblk0/device/page_size > # cd data > # ./flashbench -A -b 1024 /dev/block/mmcblk0p9 > write align 8388608 pre 3.33ms on 6.8ms post 3.65ms diff 3.31ms > write align 4194304 pre 4.34ms on 8.14ms post 4.53ms diff 3.71ms > write align 2097152 pre 3.64ms on 7.31ms post 4.09ms diff 3.44ms > write align 1048576 pre 3.65ms on 7.52ms post 3.65ms diff 3.87ms > write align 524288 pre 3.62ms on 6.8ms post 3.63ms diff 3.17ms > write align 262144 pre 3.62ms on 6.84ms post 3.63ms diff 3.22ms > write align 131072 pre 3.62ms on 6.85ms post 3.44ms diff 3.32ms > write align 65536 pre 3.39ms on 6.8ms post 3.66ms diff 3.28ms > write align 32768 pre 3.64ms on 6.86ms post 3.66ms diff 3.21ms > write align 16384 pre 3.67ms on 6.86ms post 3.65ms diff 3.2ms > write align 8192 pre 3.66ms on 6.84ms post 3.64ms diff 3.19ms > write align 4096 pre 3.71ms on 3.71ms post 3.64ms diff 38.6?s > write align 2048 pre 3.71ms on 3.71ms post 3.72ms diff -656ns > > This was with the split unaligned accesses patch... Which I am > attaching for comments. I agree, this is very fascinating behavior. 100ms second latency for a single 2KB access is definitely something we should try to avoid, and I wonder why the drive decides to do that. It must get into a state where it requires an extra garbage collection (you mentioned that earlier). The numbers you see here are taken over multiple runs. Do you see a lot of fluctuation when doing this with --count=1? Also, does the same happen with other blocksizes, e.g. 4096 or 8192, passed to flashbench? Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-19 11:20 ` Arnd Bergmann @ 2011-02-20 5:56 ` Andrei Warkentin -1 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-20 5:56 UTC (permalink / raw) To: Arnd Bergmann; +Cc: linux-arm-kernel, Linus Walleij, linux-mmc On Sat, Feb 19, 2011 at 5:20 AM, Arnd Bergmann <arnd@arndb.de> wrote: > On Saturday 19 February 2011 00:17:51 Andrei Warkentin wrote: >> # echo 0 > /sys/block/mmcblk0/device/page_size >> # ./flashbench -A -b 1024 /dev/block/mmcblk0p9 >> write align 8388608 pre 3.59ms on 6.54ms post 3.65ms diff 2.92ms >> write align 4194304 pre 4.13ms on 7.37ms post 4.27ms diff 3.17ms >> write align 2097152 pre 3.62ms on 6.81ms post 3.94ms diff 3.03ms >> write align 1048576 pre 3.62ms on 6.53ms post 3.55ms diff 2.95ms >> write align 524288 pre 3.62ms on 6.51ms post 3.63ms diff 2.88ms >> write align 262144 pre 3.62ms on 6.51ms post 3.63ms diff 2.89ms >> write align 131072 pre 3.62ms on 6.5ms post 3.63ms diff 2.88ms >> write align 65536 pre 3.61ms on 6.49ms post 3.62ms diff 2.88ms >> write align 32768 pre 3.61ms on 6.49ms post 3.61ms diff 2.88ms >> write align 16384 pre 3.68ms on 107ms post 3.51ms diff 103ms >> write align 8192 pre 3.74ms on 121ms post 3.91ms diff 117ms >> write align 4096 pre 3.88ms on 3.87ms post 3.87ms diff -2937ns >> write align 2048 pre 3.89ms on 3.88ms post 3.88ms diff -8734ns >> # fjnh84@fjnh84-desktop:~/src/n/src/flash$ adb -s 17006185428011d7 shell >> # echo 8192 > /sys/block/mmcblk0/device/page_size >> # cd data >> # ./flashbench -A -b 1024 /dev/block/mmcblk0p9 >> write align 8388608 pre 3.33ms on 6.8ms post 3.65ms diff 3.31ms >> write align 4194304 pre 4.34ms on 8.14ms post 4.53ms diff 3.71ms >> write align 2097152 pre 3.64ms on 7.31ms post 4.09ms diff 3.44ms >> write align 1048576 pre 3.65ms on 7.52ms post 3.65ms diff 3.87ms >> write align 524288 pre 3.62ms on 6.8ms post 3.63ms diff 3.17ms >> write align 262144 pre 3.62ms on 6.84ms post 3.63ms diff 3.22ms >> write align 131072 pre 3.62ms on 6.85ms post 3.44ms diff 3.32ms >> write align 65536 pre 3.39ms on 6.8ms post 3.66ms diff 3.28ms >> write align 32768 pre 3.64ms on 6.86ms post 3.66ms diff 3.21ms >> write align 16384 pre 3.67ms on 6.86ms post 3.65ms diff 3.2ms >> write align 8192 pre 3.66ms on 6.84ms post 3.64ms diff 3.19ms >> write align 4096 pre 3.71ms on 3.71ms post 3.64ms diff 38.6µs >> write align 2048 pre 3.71ms on 3.71ms post 3.72ms diff -656ns >> >> This was with the split unaligned accesses patch... Which I am >> attaching for comments. > > I agree, this is very fascinating behavior. 100ms second latency for a > single 2KB access is definitely something we should try to avoid, and I > wonder why the drive decides to do that. It must get into a state where > it requires an extra garbage collection (you mentioned that earlier). > > The numbers you see here are taken over multiple runs. Do you see a lot > of fluctuation when doing this with --count=1? > Yep. Quite a bit. # ./flashbench -c 1 -A -b 1024 /dev/block/mmcblk0p9 write align 8388608 pre 4.52ms on 7.58ms post 3.93ms diff 3.36ms write align 4194304 pre 5.97ms on 8.69ms post 4.36ms diff 3.53ms write align 2097152 pre 3.57ms on 7.96ms post 4.6ms diff 3.88ms write align 1048576 pre 5.33ms on 27.4ms post 4.88ms diff 22.3ms write align 524288 pre 49.3ms on 31.4ms post 14.9ms diff -679265 write align 262144 pre 39.7ms on 38.3ms post 5.27ms diff 15.8ms write align 131072 pre 33.8ms on 45.4ms post 5.26ms diff 25.9ms write align 65536 pre 34.4ms on 40.9ms post 3.3ms diff 22.1ms write align 32768 pre 30.2ms on 44.8ms post 5.13ms diff 27.1ms write align 16384 pre 44.5ms on 5.05ms post 33.3ms diff -338542 write align 8192 pre 25.5ms on 70.6ms post 25.3ms diff 45.2ms write align 4096 pre 4.89ms on 4.47ms post 5.29ms diff -623390 write align 2048 pre 4.88ms on 4.89ms post 5.2ms diff -155781 # ./flashbench -c 1 -A -b 1024 /dev/block/mmcblk0p9 write align 8388608 pre 4.68ms on 9.06ms post 5.14ms diff 4.15ms write align 4194304 pre 4.37ms on 7.49ms post 4.59ms diff 3.01ms write align 2097152 pre 23.7ms on 1.9ms post 14.8ms diff -173218 write align 1048576 pre 14.8ms on 19.9ms post 4.75ms diff 10.2ms write align 524288 pre 20.2ms on 24.9ms post 10.7ms diff 9.46ms write align 262144 pre 20.2ms on 3.01ms post 20.1ms diff -171062 write align 131072 pre 25.9ms on 24.9ms post 9.85ms diff 7.06ms write align 65536 pre 15.5ms on 30.3ms post 2.95ms diff 21.1ms write align 32768 pre 27.3ms on 19.1ms post 5.86ms diff 2.5ms write align 16384 pre 25.4ms on 55.9ms post 12.7ms diff 36.9ms write align 8192 pre 4.8ms on 102ms post 9.47ms diff 94.8ms write align 4096 pre 4.92ms on 5.16ms post 4.98ms diff 207µs write align 2048 pre 4.64ms on 4.92ms post 5.45ms diff -121860 # ./flashbench -c 1 -A -b 1024 /dev/block/mmcblk0p9 write align 8388608 pre 15.8ms on 9.39ms post 4.68ms diff -854295 write align 4194304 pre 4.76ms on 7.54ms post 3.82ms diff 3.24ms write align 2097152 pre 19.9ms on 9.73ms post 4.44ms diff -244517 write align 1048576 pre 14.5ms on 19.1ms post 5.21ms diff 9.23ms write align 524288 pre 24.9ms on 29ms post 5.89ms diff 13.6ms write align 262144 pre 24.9ms on 2.41ms post 20.8ms diff -204328 write align 131072 pre 25.6ms on 30ms post 4.84ms diff 14.8ms write align 65536 pre 26.4ms on 24.4ms post 6.16ms diff 8.12ms write align 32768 pre 15ms on 30.6ms post 15.4ms diff 15.4ms write align 16384 pre 16.1ms on 45.4ms post 16.5ms diff 29.1ms write align 8192 pre 5.88ms on 107ms post 5.45ms diff 101ms write align 4096 pre 5.17ms on 5.78ms post 4.83ms diff 778µs write align 2048 pre 3.99ms on 5.27ms post 3.97ms diff 1.29ms # ./flashbench -c 1 -A -b 1024 /dev/block/mmcblk0p9 write align 8388608 pre 16.1ms on 8.37ms post 5.44ms diff -241222 write align 4194304 pre 4.07ms on 7.27ms post 3.89ms diff 3.29ms write align 2097152 pre 24.2ms on 18.5ms post 5.63ms diff 3.59ms write align 1048576 pre 4.08ms on 18.9ms post 5.46ms diff 14.1ms write align 524288 pre 25.1ms on 28ms post 14.6ms diff 8.13ms write align 262144 pre 15.8ms on 30ms post 5.4ms diff 19.4ms write align 131072 pre 24.7ms on 30.8ms post 4.43ms diff 16.2ms write align 65536 pre 5ms on 40.5ms post 5.95ms diff 35.1ms write align 32768 pre 24.7ms on 30.6ms post 4.92ms diff 15.8ms write align 16384 pre 25.2ms on 132ms post 10.2ms diff 114ms write align 8192 pre 7.64ms on 111ms post 9.18ms diff 102ms write align 4096 pre 5.11ms on 3.92ms post 5.4ms diff -134159 write align 2048 pre 3.92ms on 4.41ms post 4.51ms diff 196µs > Also, does the same happen with other blocksizes, e.g. 4096 or 8192, passed > to flashbench? > # echo 0 > /sys/block/mmcblk0/device/page_size # ./flashbench -A -b 1024 /dev/block/mmcblk0p9 write align 8388608 pre 3.63ms on 6.51ms post 3.66ms diff 2.86ms write align 4194304 pre 3.61ms on 6.51ms post 3.62ms diff 2.89ms write align 2097152 pre 3.61ms on 6.49ms post 3.62ms diff 2.87ms write align 1048576 pre 3.64ms on 6.55ms post 3.62ms diff 2.92ms write align 524288 pre 3.64ms on 6.57ms post 3.66ms diff 2.92ms write align 262144 pre 3.44ms on 6.45ms post 3.66ms diff 2.9ms write align 131072 pre 3.64ms on 6.56ms post 3.67ms diff 2.91ms write align 65536 pre 3.33ms on 6.57ms post 3.65ms diff 3.08ms write align 32768 pre 3.68ms on 6.6ms post 3.7ms diff 2.91ms write align 16384 pre 3.64ms on 97.6ms post 3.26ms diff 94.2ms write align 8192 pre 3.49ms on 115ms post 3.62ms diff 112ms write align 4096 pre 3.91ms on 3.91ms post 3.9ms diff 360ns write align 2048 pre 3.92ms on 3.92ms post 3.92ms diff -1374ns # ./flashbench -A -b 2048 /dev/block/mmcblk0p9 write align 8388608 pre 3.76ms on 7.23ms post 4.18ms diff 3.27ms write align 4194304 pre 3.65ms on 6.56ms post 3.66ms diff 2.9ms write align 2097152 pre 3.9ms on 6.99ms post 3.67ms diff 3.2ms write align 1048576 pre 4.03ms on 7.09ms post 4.07ms diff 3.04ms write align 524288 pre 4.04ms on 7.26ms post 4.16ms diff 3.16ms write align 262144 pre 3.8ms on 7.26ms post 4.06ms diff 3.33ms write align 131072 pre 4.05ms on 7.25ms post 4.18ms diff 3.14ms write align 65536 pre 4.02ms on 7.22ms post 4.14ms diff 3.14ms write align 32768 pre 4ms on 7.07ms post 3.95ms diff 3.1ms write align 16384 pre 3.66ms on 106ms post 3.4ms diff 102ms write align 8192 pre 3.56ms on 106ms post 3.36ms diff 103ms write align 4096 pre 3.61ms on 4.1ms post 4.35ms diff 117µs # ./flashbench -A -b 4096 /dev/block/mmcblk0p9 write align 8388608 pre 3.64ms on 6.95ms post 3.96ms diff 3.15ms write align 4194304 pre 3.65ms on 6.56ms post 3.66ms diff 2.9ms write align 2097152 pre 3.89ms on 6.79ms post 3.66ms diff 3.01ms write align 1048576 pre 3.88ms on 6.88ms post 3.95ms diff 2.97ms write align 524288 pre 3.72ms on 6.97ms post 3.93ms diff 3.15ms write align 262144 pre 3.89ms on 6.93ms post 3.95ms diff 3.01ms write align 131072 pre 3.9ms on 6.98ms post 3.96ms diff 3.05ms write align 65536 pre 3.89ms on 6.97ms post 3.96ms diff 3.04ms write align 32768 pre 3.89ms on 6.97ms post 3.96ms diff 3.04ms write align 16384 pre 3.74ms on 114ms post 4.05ms diff 110ms write align 8192 pre 4.25ms on 115ms post 4.8ms diff 110ms # ./flashbench -A -b 8192 /dev/block/mmcblk0p9 write align 8388608 pre 3.84ms on 7.53ms post 4.29ms diff 3.47ms write align 4194304 pre 3.58ms on 6.54ms post 3.6ms diff 2.95ms write align 2097152 pre 4.12ms on 7.27ms post 3.87ms diff 3.28ms write align 1048576 pre 4.14ms on 7.49ms post 4.24ms diff 3.3ms write align 524288 pre 4.12ms on 7.46ms post 4.23ms diff 3.29ms write align 262144 pre 4.14ms on 7.45ms post 3.97ms diff 3.4ms write align 131072 pre 3.89ms on 7.43ms post 4.24ms diff 3.37ms write align 65536 pre 4.11ms on 7.46ms post 4.24ms diff 3.29ms write align 32768 pre 4.15ms on 7.45ms post 4.25ms diff 3.25ms write align 16384 pre 4.24ms on 96.1ms post 3.83ms diff 92.1ms The following I thought this was interesting. I did it to see the big time go away, since it would end up being a 16K write straddling an 8K boundary, but the pre and post results I don't understand at all. # ./flashbench -A -b 16384 /dev/block/mmcblk0p9 write align 8388608 pre 121ms on 7.76ms post 116ms diff -110845 write align 4194304 pre 129ms on 7.57ms post 115ms diff -114863 write align 2097152 pre 121ms on 7.78ms post 123ms diff -114318 write align 1048576 pre 131ms on 7.74ms post 106ms diff -110856 write align 524288 pre 131ms on 7.58ms post 116ms diff -115926 write align 262144 pre 131ms on 7.55ms post 115ms diff -115591 write align 131072 pre 131ms on 7.54ms post 116ms diff -115617 write align 65536 pre 131ms on 7.54ms post 115ms diff -115579 write align 32768 pre 125ms on 6.89ms post 116ms diff -113408 ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-20 5:56 ` Andrei Warkentin 0 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-20 5:56 UTC (permalink / raw) To: linux-arm-kernel On Sat, Feb 19, 2011 at 5:20 AM, Arnd Bergmann <arnd@arndb.de> wrote: > On Saturday 19 February 2011 00:17:51 Andrei Warkentin wrote: >> # echo 0 > /sys/block/mmcblk0/device/page_size >> # ./flashbench -A -b 1024 /dev/block/mmcblk0p9 >> write align 8388608 ? ? pre 3.59ms ? ? ?on 6.54ms ? ? ? post 3.65ms ? ? diff 2.92ms >> write align 4194304 ? ? pre 4.13ms ? ? ?on 7.37ms ? ? ? post 4.27ms ? ? diff 3.17ms >> write align 2097152 ? ? pre 3.62ms ? ? ?on 6.81ms ? ? ? post 3.94ms ? ? diff 3.03ms >> write align 1048576 ? ? pre 3.62ms ? ? ?on 6.53ms ? ? ? post 3.55ms ? ? diff 2.95ms >> write align 524288 ? ? ?pre 3.62ms ? ? ?on 6.51ms ? ? ? post 3.63ms ? ? diff 2.88ms >> write align 262144 ? ? ?pre 3.62ms ? ? ?on 6.51ms ? ? ? post 3.63ms ? ? diff 2.89ms >> write align 131072 ? ? ?pre 3.62ms ? ? ?on 6.5ms ? ? ? ?post 3.63ms ? ? diff 2.88ms >> write align 65536 ? ? ? pre 3.61ms ? ? ?on 6.49ms ? ? ? post 3.62ms ? ? diff 2.88ms >> write align 32768 ? ? ? pre 3.61ms ? ? ?on 6.49ms ? ? ? post 3.61ms ? ? diff 2.88ms >> write align 16384 ? ? ? pre 3.68ms ? ? ?on 107ms ? ? ? ?post 3.51ms ? ? diff 103ms >> write align 8192 ? ? ? ?pre 3.74ms ? ? ?on 121ms ? ? ? ?post 3.91ms ? ? diff 117ms >> write align 4096 ? ? ? ?pre 3.88ms ? ? ?on 3.87ms ? ? ? post 3.87ms ? ? diff -2937ns >> write align 2048 ? ? ? ?pre 3.89ms ? ? ?on 3.88ms ? ? ? post 3.88ms ? ? diff -8734ns >> # fjnh84 at fjnh84-desktop:~/src/n/src/flash$ adb -s 17006185428011d7 shell >> # echo 8192 > /sys/block/mmcblk0/device/page_size >> # cd data >> # ./flashbench -A -b 1024 /dev/block/mmcblk0p9 >> write align 8388608 ? ? pre 3.33ms ? ? ?on 6.8ms ? ? ? ?post 3.65ms ? ? diff 3.31ms >> write align 4194304 ? ? pre 4.34ms ? ? ?on 8.14ms ? ? ? post 4.53ms ? ? diff 3.71ms >> write align 2097152 ? ? pre 3.64ms ? ? ?on 7.31ms ? ? ? post 4.09ms ? ? diff 3.44ms >> write align 1048576 ? ? pre 3.65ms ? ? ?on 7.52ms ? ? ? post 3.65ms ? ? diff 3.87ms >> write align 524288 ? ? ?pre 3.62ms ? ? ?on 6.8ms ? ? ? ?post 3.63ms ? ? diff 3.17ms >> write align 262144 ? ? ?pre 3.62ms ? ? ?on 6.84ms ? ? ? post 3.63ms ? ? diff 3.22ms >> write align 131072 ? ? ?pre 3.62ms ? ? ?on 6.85ms ? ? ? post 3.44ms ? ? diff 3.32ms >> write align 65536 ? ? ? pre 3.39ms ? ? ?on 6.8ms ? ? ? ?post 3.66ms ? ? diff 3.28ms >> write align 32768 ? ? ? pre 3.64ms ? ? ?on 6.86ms ? ? ? post 3.66ms ? ? diff 3.21ms >> write align 16384 ? ? ? pre 3.67ms ? ? ?on 6.86ms ? ? ? post 3.65ms ? ? diff 3.2ms >> write align 8192 ? ? ? ?pre 3.66ms ? ? ?on 6.84ms ? ? ? post 3.64ms ? ? diff 3.19ms >> write align 4096 ? ? ? ?pre 3.71ms ? ? ?on 3.71ms ? ? ? post 3.64ms ? ? diff 38.6?s >> write align 2048 ? ? ? ?pre 3.71ms ? ? ?on 3.71ms ? ? ? post 3.72ms ? ? diff -656ns >> >> This was with the split unaligned accesses patch... Which I am >> attaching for comments. > > I agree, this is very fascinating behavior. 100ms second latency for a > single 2KB access is definitely something we should try to avoid, and I > wonder why the drive decides to do that. It must get into a state where > it requires an extra garbage collection (you mentioned that earlier). > > The numbers you see here are taken over multiple runs. Do you see a lot > of fluctuation when doing this with --count=1? > Yep. Quite a bit. # ./flashbench -c 1 -A -b 1024 /dev/block/mmcblk0p9 write align 8388608 pre 4.52ms on 7.58ms post 3.93ms diff 3.36ms write align 4194304 pre 5.97ms on 8.69ms post 4.36ms diff 3.53ms write align 2097152 pre 3.57ms on 7.96ms post 4.6ms diff 3.88ms write align 1048576 pre 5.33ms on 27.4ms post 4.88ms diff 22.3ms write align 524288 pre 49.3ms on 31.4ms post 14.9ms diff -679265 write align 262144 pre 39.7ms on 38.3ms post 5.27ms diff 15.8ms write align 131072 pre 33.8ms on 45.4ms post 5.26ms diff 25.9ms write align 65536 pre 34.4ms on 40.9ms post 3.3ms diff 22.1ms write align 32768 pre 30.2ms on 44.8ms post 5.13ms diff 27.1ms write align 16384 pre 44.5ms on 5.05ms post 33.3ms diff -338542 write align 8192 pre 25.5ms on 70.6ms post 25.3ms diff 45.2ms write align 4096 pre 4.89ms on 4.47ms post 5.29ms diff -623390 write align 2048 pre 4.88ms on 4.89ms post 5.2ms diff -155781 # ./flashbench -c 1 -A -b 1024 /dev/block/mmcblk0p9 write align 8388608 pre 4.68ms on 9.06ms post 5.14ms diff 4.15ms write align 4194304 pre 4.37ms on 7.49ms post 4.59ms diff 3.01ms write align 2097152 pre 23.7ms on 1.9ms post 14.8ms diff -173218 write align 1048576 pre 14.8ms on 19.9ms post 4.75ms diff 10.2ms write align 524288 pre 20.2ms on 24.9ms post 10.7ms diff 9.46ms write align 262144 pre 20.2ms on 3.01ms post 20.1ms diff -171062 write align 131072 pre 25.9ms on 24.9ms post 9.85ms diff 7.06ms write align 65536 pre 15.5ms on 30.3ms post 2.95ms diff 21.1ms write align 32768 pre 27.3ms on 19.1ms post 5.86ms diff 2.5ms write align 16384 pre 25.4ms on 55.9ms post 12.7ms diff 36.9ms write align 8192 pre 4.8ms on 102ms post 9.47ms diff 94.8ms write align 4096 pre 4.92ms on 5.16ms post 4.98ms diff 207?s write align 2048 pre 4.64ms on 4.92ms post 5.45ms diff -121860 # ./flashbench -c 1 -A -b 1024 /dev/block/mmcblk0p9 write align 8388608 pre 15.8ms on 9.39ms post 4.68ms diff -854295 write align 4194304 pre 4.76ms on 7.54ms post 3.82ms diff 3.24ms write align 2097152 pre 19.9ms on 9.73ms post 4.44ms diff -244517 write align 1048576 pre 14.5ms on 19.1ms post 5.21ms diff 9.23ms write align 524288 pre 24.9ms on 29ms post 5.89ms diff 13.6ms write align 262144 pre 24.9ms on 2.41ms post 20.8ms diff -204328 write align 131072 pre 25.6ms on 30ms post 4.84ms diff 14.8ms write align 65536 pre 26.4ms on 24.4ms post 6.16ms diff 8.12ms write align 32768 pre 15ms on 30.6ms post 15.4ms diff 15.4ms write align 16384 pre 16.1ms on 45.4ms post 16.5ms diff 29.1ms write align 8192 pre 5.88ms on 107ms post 5.45ms diff 101ms write align 4096 pre 5.17ms on 5.78ms post 4.83ms diff 778?s write align 2048 pre 3.99ms on 5.27ms post 3.97ms diff 1.29ms # ./flashbench -c 1 -A -b 1024 /dev/block/mmcblk0p9 write align 8388608 pre 16.1ms on 8.37ms post 5.44ms diff -241222 write align 4194304 pre 4.07ms on 7.27ms post 3.89ms diff 3.29ms write align 2097152 pre 24.2ms on 18.5ms post 5.63ms diff 3.59ms write align 1048576 pre 4.08ms on 18.9ms post 5.46ms diff 14.1ms write align 524288 pre 25.1ms on 28ms post 14.6ms diff 8.13ms write align 262144 pre 15.8ms on 30ms post 5.4ms diff 19.4ms write align 131072 pre 24.7ms on 30.8ms post 4.43ms diff 16.2ms write align 65536 pre 5ms on 40.5ms post 5.95ms diff 35.1ms write align 32768 pre 24.7ms on 30.6ms post 4.92ms diff 15.8ms write align 16384 pre 25.2ms on 132ms post 10.2ms diff 114ms write align 8192 pre 7.64ms on 111ms post 9.18ms diff 102ms write align 4096 pre 5.11ms on 3.92ms post 5.4ms diff -134159 write align 2048 pre 3.92ms on 4.41ms post 4.51ms diff 196?s > Also, does the same happen with other blocksizes, e.g. 4096 or 8192, passed > to flashbench? > # echo 0 > /sys/block/mmcblk0/device/page_size # ./flashbench -A -b 1024 /dev/block/mmcblk0p9 write align 8388608 pre 3.63ms on 6.51ms post 3.66ms diff 2.86ms write align 4194304 pre 3.61ms on 6.51ms post 3.62ms diff 2.89ms write align 2097152 pre 3.61ms on 6.49ms post 3.62ms diff 2.87ms write align 1048576 pre 3.64ms on 6.55ms post 3.62ms diff 2.92ms write align 524288 pre 3.64ms on 6.57ms post 3.66ms diff 2.92ms write align 262144 pre 3.44ms on 6.45ms post 3.66ms diff 2.9ms write align 131072 pre 3.64ms on 6.56ms post 3.67ms diff 2.91ms write align 65536 pre 3.33ms on 6.57ms post 3.65ms diff 3.08ms write align 32768 pre 3.68ms on 6.6ms post 3.7ms diff 2.91ms write align 16384 pre 3.64ms on 97.6ms post 3.26ms diff 94.2ms write align 8192 pre 3.49ms on 115ms post 3.62ms diff 112ms write align 4096 pre 3.91ms on 3.91ms post 3.9ms diff 360ns write align 2048 pre 3.92ms on 3.92ms post 3.92ms diff -1374ns # ./flashbench -A -b 2048 /dev/block/mmcblk0p9 write align 8388608 pre 3.76ms on 7.23ms post 4.18ms diff 3.27ms write align 4194304 pre 3.65ms on 6.56ms post 3.66ms diff 2.9ms write align 2097152 pre 3.9ms on 6.99ms post 3.67ms diff 3.2ms write align 1048576 pre 4.03ms on 7.09ms post 4.07ms diff 3.04ms write align 524288 pre 4.04ms on 7.26ms post 4.16ms diff 3.16ms write align 262144 pre 3.8ms on 7.26ms post 4.06ms diff 3.33ms write align 131072 pre 4.05ms on 7.25ms post 4.18ms diff 3.14ms write align 65536 pre 4.02ms on 7.22ms post 4.14ms diff 3.14ms write align 32768 pre 4ms on 7.07ms post 3.95ms diff 3.1ms write align 16384 pre 3.66ms on 106ms post 3.4ms diff 102ms write align 8192 pre 3.56ms on 106ms post 3.36ms diff 103ms write align 4096 pre 3.61ms on 4.1ms post 4.35ms diff 117?s # ./flashbench -A -b 4096 /dev/block/mmcblk0p9 write align 8388608 pre 3.64ms on 6.95ms post 3.96ms diff 3.15ms write align 4194304 pre 3.65ms on 6.56ms post 3.66ms diff 2.9ms write align 2097152 pre 3.89ms on 6.79ms post 3.66ms diff 3.01ms write align 1048576 pre 3.88ms on 6.88ms post 3.95ms diff 2.97ms write align 524288 pre 3.72ms on 6.97ms post 3.93ms diff 3.15ms write align 262144 pre 3.89ms on 6.93ms post 3.95ms diff 3.01ms write align 131072 pre 3.9ms on 6.98ms post 3.96ms diff 3.05ms write align 65536 pre 3.89ms on 6.97ms post 3.96ms diff 3.04ms write align 32768 pre 3.89ms on 6.97ms post 3.96ms diff 3.04ms write align 16384 pre 3.74ms on 114ms post 4.05ms diff 110ms write align 8192 pre 4.25ms on 115ms post 4.8ms diff 110ms # ./flashbench -A -b 8192 /dev/block/mmcblk0p9 write align 8388608 pre 3.84ms on 7.53ms post 4.29ms diff 3.47ms write align 4194304 pre 3.58ms on 6.54ms post 3.6ms diff 2.95ms write align 2097152 pre 4.12ms on 7.27ms post 3.87ms diff 3.28ms write align 1048576 pre 4.14ms on 7.49ms post 4.24ms diff 3.3ms write align 524288 pre 4.12ms on 7.46ms post 4.23ms diff 3.29ms write align 262144 pre 4.14ms on 7.45ms post 3.97ms diff 3.4ms write align 131072 pre 3.89ms on 7.43ms post 4.24ms diff 3.37ms write align 65536 pre 4.11ms on 7.46ms post 4.24ms diff 3.29ms write align 32768 pre 4.15ms on 7.45ms post 4.25ms diff 3.25ms write align 16384 pre 4.24ms on 96.1ms post 3.83ms diff 92.1ms The following I thought this was interesting. I did it to see the big time go away, since it would end up being a 16K write straddling an 8K boundary, but the pre and post results I don't understand at all. # ./flashbench -A -b 16384 /dev/block/mmcblk0p9 write align 8388608 pre 121ms on 7.76ms post 116ms diff -110845 write align 4194304 pre 129ms on 7.57ms post 115ms diff -114863 write align 2097152 pre 121ms on 7.78ms post 123ms diff -114318 write align 1048576 pre 131ms on 7.74ms post 106ms diff -110856 write align 524288 pre 131ms on 7.58ms post 116ms diff -115926 write align 262144 pre 131ms on 7.55ms post 115ms diff -115591 write align 131072 pre 131ms on 7.54ms post 116ms diff -115617 write align 65536 pre 131ms on 7.54ms post 115ms diff -115579 write align 32768 pre 125ms on 6.89ms post 116ms diff -113408 ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-20 5:56 ` Andrei Warkentin @ 2011-02-20 15:23 ` Arnd Bergmann -1 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-20 15:23 UTC (permalink / raw) To: Andrei Warkentin; +Cc: linux-arm-kernel, Linus Walleij, linux-mmc On Sunday 20 February 2011 06:56:39 Andrei Warkentin wrote: > On Sat, Feb 19, 2011 at 5:20 AM, Arnd Bergmann <arnd@arndb.de> wrote: > > The numbers you see here are taken over multiple runs. Do you see a lot > > of fluctuation when doing this with --count=1? > > > > Yep. Quite a bit. > > # ./flashbench -c 1 -A -b 1024 /dev/block/mmcblk0p9 > write align 8388608 pre 4.52ms on 7.58ms post 3.93ms diff 3.36ms > write align 4194304 pre 5.97ms on 8.69ms post 4.36ms diff 3.53ms > write align 2097152 pre 3.57ms on 7.96ms post 4.6ms diff 3.88ms > write align 1048576 pre 5.33ms on 27.4ms post 4.88ms diff 22.3ms > write align 524288 pre 49.3ms on 31.4ms post 14.9ms diff -679265 > write align 262144 pre 39.7ms on 38.3ms post 5.27ms diff 15.8ms > write align 131072 pre 33.8ms on 45.4ms post 5.26ms diff 25.9ms > write align 65536 pre 34.4ms on 40.9ms post 3.3ms diff 22.1ms > write align 32768 pre 30.2ms on 44.8ms post 5.13ms diff 27.1ms > write align 16384 pre 44.5ms on 5.05ms post 33.3ms diff -338542 > write align 8192 pre 25.5ms on 70.6ms post 25.3ms diff 45.2ms > write align 4096 pre 4.89ms on 4.47ms post 5.29ms diff -623390 > write align 2048 pre 4.88ms on 4.89ms post 5.2ms diff -155781 > # ./flashbench -c 1 -A -b 1024 /dev/block/mmcblk0p9 > write align 8388608 pre 4.68ms on 9.06ms post 5.14ms diff 4.15ms > write align 4194304 pre 4.37ms on 7.49ms post 4.59ms diff 3.01ms > write align 2097152 pre 23.7ms on 1.9ms post 14.8ms diff -173218 > write align 1048576 pre 14.8ms on 19.9ms post 4.75ms diff 10.2ms > write align 524288 pre 20.2ms on 24.9ms post 10.7ms diff 9.46ms > write align 262144 pre 20.2ms on 3.01ms post 20.1ms diff -171062 > write align 131072 pre 25.9ms on 24.9ms post 9.85ms diff 7.06ms > write align 65536 pre 15.5ms on 30.3ms post 2.95ms diff 21.1ms > write align 32768 pre 27.3ms on 19.1ms post 5.86ms diff 2.5ms > write align 16384 pre 25.4ms on 55.9ms post 12.7ms diff 36.9ms > write align 8192 pre 4.8ms on 102ms post 9.47ms diff 94.8ms > write align 4096 pre 4.92ms on 5.16ms post 4.98ms diff 207µs > write align 2048 pre 4.64ms on 4.92ms post 5.45ms diff -121860 > # ./flashbench -c 1 -A -b 1024 /dev/block/mmcblk0p9 > write align 8388608 pre 15.8ms on 9.39ms post 4.68ms diff -854295 > write align 4194304 pre 4.76ms on 7.54ms post 3.82ms diff 3.24ms > write align 2097152 pre 19.9ms on 9.73ms post 4.44ms diff -244517 > write align 1048576 pre 14.5ms on 19.1ms post 5.21ms diff 9.23ms > write align 524288 pre 24.9ms on 29ms post 5.89ms diff 13.6ms > write align 262144 pre 24.9ms on 2.41ms post 20.8ms diff -204328 > write align 131072 pre 25.6ms on 30ms post 4.84ms diff 14.8ms > write align 65536 pre 26.4ms on 24.4ms post 6.16ms diff 8.12ms > write align 32768 pre 15ms on 30.6ms post 15.4ms diff 15.4ms > write align 16384 pre 16.1ms on 45.4ms post 16.5ms diff 29.1ms > write align 8192 pre 5.88ms on 107ms post 5.45ms diff 101ms > write align 4096 pre 5.17ms on 5.78ms post 4.83ms diff 778µs > write align 2048 pre 3.99ms on 5.27ms post 3.97ms diff 1.29ms > # ./flashbench -c 1 -A -b 1024 /dev/block/mmcblk0p9 > write align 8388608 pre 16.1ms on 8.37ms post 5.44ms diff -241222 > write align 4194304 pre 4.07ms on 7.27ms post 3.89ms diff 3.29ms > write align 2097152 pre 24.2ms on 18.5ms post 5.63ms diff 3.59ms > write align 1048576 pre 4.08ms on 18.9ms post 5.46ms diff 14.1ms > write align 524288 pre 25.1ms on 28ms post 14.6ms diff 8.13ms > write align 262144 pre 15.8ms on 30ms post 5.4ms diff 19.4ms > write align 131072 pre 24.7ms on 30.8ms post 4.43ms diff 16.2ms > write align 65536 pre 5ms on 40.5ms post 5.95ms diff 35.1ms > write align 32768 pre 24.7ms on 30.6ms post 4.92ms diff 15.8ms > write align 16384 pre 25.2ms on 132ms post 10.2ms diff 114ms > write align 8192 pre 7.64ms on 111ms post 9.18ms diff 102ms > write align 4096 pre 5.11ms on 3.92ms post 5.4ms diff -134159 > write align 2048 pre 3.92ms on 4.41ms post 4.51ms diff 196µs Every value is the average of eight measurements, so there are probably some that include the 100ms garbage collection, and others that don't. I'm more confused about this now than I was before. > > Also, does the same happen with other blocksizes, e.g. 4096 or 8192, passed > > to flashbench? > > # echo 0 > /sys/block/mmcblk0/device/page_size > # ./flashbench -A -b 1024 /dev/block/mmcblk0p9 > write align 65536 pre 3.33ms on 6.57ms post 3.65ms diff 3.08ms > write align 32768 pre 3.68ms on 6.6ms post 3.7ms diff 2.91ms > write align 16384 pre 3.64ms on 97.6ms post 3.26ms diff 94.2ms > write align 8192 pre 3.49ms on 115ms post 3.62ms diff 112ms > write align 4096 pre 3.91ms on 3.91ms post 3.9ms diff 360ns > write align 2048 pre 3.92ms on 3.92ms post 3.92ms diff -1374ns > # ./flashbench -A -b 2048 /dev/block/mmcblk0p9 > write align 65536 pre 4.02ms on 7.22ms post 4.14ms diff 3.14ms > write align 32768 pre 4ms on 7.07ms post 3.95ms diff 3.1ms > write align 16384 pre 3.66ms on 106ms post 3.4ms diff 102ms > write align 8192 pre 3.56ms on 106ms post 3.36ms diff 103ms > write align 4096 pre 3.61ms on 4.1ms post 4.35ms diff 117µs > # ./flashbench -A -b 4096 /dev/block/mmcblk0p9 > write align 65536 pre 3.89ms on 6.97ms post 3.96ms diff 3.04ms > write align 32768 pre 3.89ms on 6.97ms post 3.96ms diff 3.04ms > write align 16384 pre 3.74ms on 114ms post 4.05ms diff 110ms > write align 8192 pre 4.25ms on 115ms post 4.8ms diff 110ms > # ./flashbench -A -b 8192 /dev/block/mmcblk0p9 > write align 65536 pre 4.11ms on 7.46ms post 4.24ms diff 3.29ms > write align 32768 pre 4.15ms on 7.45ms post 4.25ms diff 3.25ms > write align 16384 pre 4.24ms on 96.1ms post 3.83ms diff 92.1ms Ok, that is very consistent then at least. > The following I thought this was interesting. I did it to see the big > time go away, since it would end up being a 16K write straddling an 8K > boundary, but the pre and post results I don't understand at all. > > # ./flashbench -A -b 16384 /dev/block/mmcblk0p9 > write align 8388608 pre 121ms on 7.76ms post 116ms diff -110845 > write align 4194304 pre 129ms on 7.57ms post 115ms diff -114863 > write align 2097152 pre 121ms on 7.78ms post 123ms diff -114318 > write align 1048576 pre 131ms on 7.74ms post 106ms diff -110856 > write align 524288 pre 131ms on 7.58ms post 116ms diff -115926 > write align 262144 pre 131ms on 7.55ms post 115ms diff -115591 > write align 131072 pre 131ms on 7.54ms post 116ms diff -115617 > write align 65536 pre 131ms on 7.54ms post 115ms diff -115579 > write align 32768 pre 125ms on 6.89ms post 116ms diff -113408 The description of the test case is probably suboptimal. What this does is 32 KB accesses, with 32 KB alignment in the pre and post case, but 16 KB alignment in the "on" case. The idea here is that it should never do any access with less than "--blocksize" aligment. This is what I think happens: Since the partition is over 64 MB size and it can have 7 4 MB allocation units open, writing to 8 locations on the drive separated 8 MB causes it to do garbage collection all the time for 32KB accesses and larger. However, the "on" measurement is only 16 KB aligned, so it goes into T's buffer A for small writes, and does not hit the garbage collection all the time, so it ends up being a lot faster. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-20 15:23 ` Arnd Bergmann 0 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-20 15:23 UTC (permalink / raw) To: linux-arm-kernel On Sunday 20 February 2011 06:56:39 Andrei Warkentin wrote: > On Sat, Feb 19, 2011 at 5:20 AM, Arnd Bergmann <arnd@arndb.de> wrote: > > The numbers you see here are taken over multiple runs. Do you see a lot > > of fluctuation when doing this with --count=1? > > > > Yep. Quite a bit. > > # ./flashbench -c 1 -A -b 1024 /dev/block/mmcblk0p9 > write align 8388608 pre 4.52ms on 7.58ms post 3.93ms diff 3.36ms > write align 4194304 pre 5.97ms on 8.69ms post 4.36ms diff 3.53ms > write align 2097152 pre 3.57ms on 7.96ms post 4.6ms diff 3.88ms > write align 1048576 pre 5.33ms on 27.4ms post 4.88ms diff 22.3ms > write align 524288 pre 49.3ms on 31.4ms post 14.9ms diff -679265 > write align 262144 pre 39.7ms on 38.3ms post 5.27ms diff 15.8ms > write align 131072 pre 33.8ms on 45.4ms post 5.26ms diff 25.9ms > write align 65536 pre 34.4ms on 40.9ms post 3.3ms diff 22.1ms > write align 32768 pre 30.2ms on 44.8ms post 5.13ms diff 27.1ms > write align 16384 pre 44.5ms on 5.05ms post 33.3ms diff -338542 > write align 8192 pre 25.5ms on 70.6ms post 25.3ms diff 45.2ms > write align 4096 pre 4.89ms on 4.47ms post 5.29ms diff -623390 > write align 2048 pre 4.88ms on 4.89ms post 5.2ms diff -155781 > # ./flashbench -c 1 -A -b 1024 /dev/block/mmcblk0p9 > write align 8388608 pre 4.68ms on 9.06ms post 5.14ms diff 4.15ms > write align 4194304 pre 4.37ms on 7.49ms post 4.59ms diff 3.01ms > write align 2097152 pre 23.7ms on 1.9ms post 14.8ms diff -173218 > write align 1048576 pre 14.8ms on 19.9ms post 4.75ms diff 10.2ms > write align 524288 pre 20.2ms on 24.9ms post 10.7ms diff 9.46ms > write align 262144 pre 20.2ms on 3.01ms post 20.1ms diff -171062 > write align 131072 pre 25.9ms on 24.9ms post 9.85ms diff 7.06ms > write align 65536 pre 15.5ms on 30.3ms post 2.95ms diff 21.1ms > write align 32768 pre 27.3ms on 19.1ms post 5.86ms diff 2.5ms > write align 16384 pre 25.4ms on 55.9ms post 12.7ms diff 36.9ms > write align 8192 pre 4.8ms on 102ms post 9.47ms diff 94.8ms > write align 4096 pre 4.92ms on 5.16ms post 4.98ms diff 207?s > write align 2048 pre 4.64ms on 4.92ms post 5.45ms diff -121860 > # ./flashbench -c 1 -A -b 1024 /dev/block/mmcblk0p9 > write align 8388608 pre 15.8ms on 9.39ms post 4.68ms diff -854295 > write align 4194304 pre 4.76ms on 7.54ms post 3.82ms diff 3.24ms > write align 2097152 pre 19.9ms on 9.73ms post 4.44ms diff -244517 > write align 1048576 pre 14.5ms on 19.1ms post 5.21ms diff 9.23ms > write align 524288 pre 24.9ms on 29ms post 5.89ms diff 13.6ms > write align 262144 pre 24.9ms on 2.41ms post 20.8ms diff -204328 > write align 131072 pre 25.6ms on 30ms post 4.84ms diff 14.8ms > write align 65536 pre 26.4ms on 24.4ms post 6.16ms diff 8.12ms > write align 32768 pre 15ms on 30.6ms post 15.4ms diff 15.4ms > write align 16384 pre 16.1ms on 45.4ms post 16.5ms diff 29.1ms > write align 8192 pre 5.88ms on 107ms post 5.45ms diff 101ms > write align 4096 pre 5.17ms on 5.78ms post 4.83ms diff 778?s > write align 2048 pre 3.99ms on 5.27ms post 3.97ms diff 1.29ms > # ./flashbench -c 1 -A -b 1024 /dev/block/mmcblk0p9 > write align 8388608 pre 16.1ms on 8.37ms post 5.44ms diff -241222 > write align 4194304 pre 4.07ms on 7.27ms post 3.89ms diff 3.29ms > write align 2097152 pre 24.2ms on 18.5ms post 5.63ms diff 3.59ms > write align 1048576 pre 4.08ms on 18.9ms post 5.46ms diff 14.1ms > write align 524288 pre 25.1ms on 28ms post 14.6ms diff 8.13ms > write align 262144 pre 15.8ms on 30ms post 5.4ms diff 19.4ms > write align 131072 pre 24.7ms on 30.8ms post 4.43ms diff 16.2ms > write align 65536 pre 5ms on 40.5ms post 5.95ms diff 35.1ms > write align 32768 pre 24.7ms on 30.6ms post 4.92ms diff 15.8ms > write align 16384 pre 25.2ms on 132ms post 10.2ms diff 114ms > write align 8192 pre 7.64ms on 111ms post 9.18ms diff 102ms > write align 4096 pre 5.11ms on 3.92ms post 5.4ms diff -134159 > write align 2048 pre 3.92ms on 4.41ms post 4.51ms diff 196?s Every value is the average of eight measurements, so there are probably some that include the 100ms garbage collection, and others that don't. I'm more confused about this now than I was before. > > Also, does the same happen with other blocksizes, e.g. 4096 or 8192, passed > > to flashbench? > > # echo 0 > /sys/block/mmcblk0/device/page_size > # ./flashbench -A -b 1024 /dev/block/mmcblk0p9 > write align 65536 pre 3.33ms on 6.57ms post 3.65ms diff 3.08ms > write align 32768 pre 3.68ms on 6.6ms post 3.7ms diff 2.91ms > write align 16384 pre 3.64ms on 97.6ms post 3.26ms diff 94.2ms > write align 8192 pre 3.49ms on 115ms post 3.62ms diff 112ms > write align 4096 pre 3.91ms on 3.91ms post 3.9ms diff 360ns > write align 2048 pre 3.92ms on 3.92ms post 3.92ms diff -1374ns > # ./flashbench -A -b 2048 /dev/block/mmcblk0p9 > write align 65536 pre 4.02ms on 7.22ms post 4.14ms diff 3.14ms > write align 32768 pre 4ms on 7.07ms post 3.95ms diff 3.1ms > write align 16384 pre 3.66ms on 106ms post 3.4ms diff 102ms > write align 8192 pre 3.56ms on 106ms post 3.36ms diff 103ms > write align 4096 pre 3.61ms on 4.1ms post 4.35ms diff 117?s > # ./flashbench -A -b 4096 /dev/block/mmcblk0p9 > write align 65536 pre 3.89ms on 6.97ms post 3.96ms diff 3.04ms > write align 32768 pre 3.89ms on 6.97ms post 3.96ms diff 3.04ms > write align 16384 pre 3.74ms on 114ms post 4.05ms diff 110ms > write align 8192 pre 4.25ms on 115ms post 4.8ms diff 110ms > # ./flashbench -A -b 8192 /dev/block/mmcblk0p9 > write align 65536 pre 4.11ms on 7.46ms post 4.24ms diff 3.29ms > write align 32768 pre 4.15ms on 7.45ms post 4.25ms diff 3.25ms > write align 16384 pre 4.24ms on 96.1ms post 3.83ms diff 92.1ms Ok, that is very consistent then at least. > The following I thought this was interesting. I did it to see the big > time go away, since it would end up being a 16K write straddling an 8K > boundary, but the pre and post results I don't understand at all. > > # ./flashbench -A -b 16384 /dev/block/mmcblk0p9 > write align 8388608 pre 121ms on 7.76ms post 116ms diff -110845 > write align 4194304 pre 129ms on 7.57ms post 115ms diff -114863 > write align 2097152 pre 121ms on 7.78ms post 123ms diff -114318 > write align 1048576 pre 131ms on 7.74ms post 106ms diff -110856 > write align 524288 pre 131ms on 7.58ms post 116ms diff -115926 > write align 262144 pre 131ms on 7.55ms post 115ms diff -115591 > write align 131072 pre 131ms on 7.54ms post 116ms diff -115617 > write align 65536 pre 131ms on 7.54ms post 115ms diff -115579 > write align 32768 pre 125ms on 6.89ms post 116ms diff -113408 The description of the test case is probably suboptimal. What this does is 32 KB accesses, with 32 KB alignment in the pre and post case, but 16 KB alignment in the "on" case. The idea here is that it should never do any access with less than "--blocksize" aligment. This is what I think happens: Since the partition is over 64 MB size and it can have 7 4 MB allocation units open, writing to 8 locations on the drive separated 8 MB causes it to do garbage collection all the time for 32KB accesses and larger. However, the "on" measurement is only 16 KB aligned, so it goes into T's buffer A for small writes, and does not hit the garbage collection all the time, so it ends up being a lot faster. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-20 15:23 ` Arnd Bergmann @ 2011-02-22 7:05 ` Andrei Warkentin -1 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-22 7:05 UTC (permalink / raw) To: Arnd Bergmann; +Cc: linux-arm-kernel, Linus Walleij, linux-mmc On Sun, Feb 20, 2011 at 9:23 AM, Arnd Bergmann <arnd@arndb.de> wrote: > The description of the test case is probably suboptimal. What this does > is 32 KB accesses, with 32 KB alignment in the pre and post case, but 16 KB > alignment in the "on" case. The idea here is that it should never do > any access with less than "--blocksize" aligment. > Now I feel slightly confused :(. -b 16384 implies blocksize = 16384, maxalign is 8mb due to count 32, ret = time_rw_interval(dev, count, pre, blocksize, align - blocksize, maxalign, do_write); // <----------------- read 16k at align - 16k with 8mb intervals? returnif(ret); ret = time_rw_interval(dev, count, on, blocksize, align - blocksize / 2, maxalign, do_write); // <----------------- read 16k at align - 8k with 8mb intervals? returnif(ret); ret = time_rw_interval(dev, count, post, blocksize, align, maxalign, do_write); // <-------- read 16k at align with 8mb intervals? returnif(ret); I hope I'm not missing something obvious... > This is what I think happens: > Since the partition is over 64 MB size and it can have 7 4 MB allocation units open, > writing to 8 locations on the drive separated 8 MB causes it to do garbage collection > all the time for 32KB accesses and larger. However, the "on" measurement is only > 16 KB aligned, so it goes into T's buffer A for small writes, and does not hit > the garbage collection all the time, so it ends up being a lot faster. > Can't go to A. A is 8KB big. Strange... A ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-22 7:05 ` Andrei Warkentin 0 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-22 7:05 UTC (permalink / raw) To: linux-arm-kernel On Sun, Feb 20, 2011 at 9:23 AM, Arnd Bergmann <arnd@arndb.de> wrote: > The description of the test case is probably suboptimal. What this does > is 32 KB accesses, with 32 KB alignment in the pre and post case, but 16 KB > alignment in the "on" case. The idea here is that it should never do > any access with less than "--blocksize" aligment. > Now I feel slightly confused :(. -b 16384 implies blocksize = 16384, maxalign is 8mb due to count 32, ret = time_rw_interval(dev, count, pre, blocksize, align - blocksize, maxalign, do_write); // <----------------- read 16k at align - 16k with 8mb intervals? returnif(ret); ret = time_rw_interval(dev, count, on, blocksize, align - blocksize / 2, maxalign, do_write); // <----------------- read 16k at align - 8k with 8mb intervals? returnif(ret); ret = time_rw_interval(dev, count, post, blocksize, align, maxalign, do_write); // <-------- read 16k@align with 8mb intervals? returnif(ret); I hope I'm not missing something obvious... > This is what I think happens: > Since the partition is over 64 MB size and it can have 7 4 MB allocation units open, > writing to 8 locations on the drive separated 8 MB causes it to do garbage collection > all the time for 32KB accesses and larger. However, the "on" measurement is only > 16 KB aligned, so it goes into T's buffer A for small writes, and does not hit > the garbage collection all the time, so it ends up being a lot faster. > Can't go to A. A is 8KB big. Strange... A ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-22 7:05 ` Andrei Warkentin @ 2011-02-22 16:49 ` Arnd Bergmann -1 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-22 16:49 UTC (permalink / raw) To: Andrei Warkentin; +Cc: linux-arm-kernel, Linus Walleij, linux-mmc On Tuesday 22 February 2011, Andrei Warkentin wrote: > On Sun, Feb 20, 2011 at 9:23 AM, Arnd Bergmann <arnd@arndb.de> wrote: > > The description of the test case is probably suboptimal. What this does > > is 32 KB accesses, with 32 KB alignment in the pre and post case, but 16 KB > > alignment in the "on" case. The idea here is that it should never do > > any access with less than "--blocksize" aligment. > > > > Now I feel slightly confused :(. > > -b 16384 implies blocksize = 16384, maxalign is 8mb due to count 32, > > ret = time_rw_interval(dev, count, pre, blocksize, > align - blocksize, maxalign, > do_write); // > <----------------- read 16k at align - 16k with 8mb intervals? > returnif(ret); > > ret = time_rw_interval(dev, count, on, blocksize, > align - blocksize / 2, maxalign, > do_write); // > <----------------- read 16k at align - 8k with 8mb intervals? > returnif(ret); > > ret = time_rw_interval(dev, count, post, blocksize, > align, maxalign, do_write); // > <-------- read 16k at align with 8mb intervals? > returnif(ret); > > I hope I'm not missing something obvious... No, you are absolutely right. I think I changed this once and no longer remembered what the final version did. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-22 16:49 ` Arnd Bergmann 0 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-22 16:49 UTC (permalink / raw) To: linux-arm-kernel On Tuesday 22 February 2011, Andrei Warkentin wrote: > On Sun, Feb 20, 2011 at 9:23 AM, Arnd Bergmann <arnd@arndb.de> wrote: > > The description of the test case is probably suboptimal. What this does > > is 32 KB accesses, with 32 KB alignment in the pre and post case, but 16 KB > > alignment in the "on" case. The idea here is that it should never do > > any access with less than "--blocksize" aligment. > > > > Now I feel slightly confused :(. > > -b 16384 implies blocksize = 16384, maxalign is 8mb due to count 32, > > ret = time_rw_interval(dev, count, pre, blocksize, > align - blocksize, maxalign, > do_write); // > <----------------- read 16k@align - 16k with 8mb intervals? > returnif(ret); > > ret = time_rw_interval(dev, count, on, blocksize, > align - blocksize / 2, maxalign, > do_write); // > <----------------- read 16k@align - 8k with 8mb intervals? > returnif(ret); > > ret = time_rw_interval(dev, count, post, blocksize, > align, maxalign, do_write); // > <-------- read 16k@align with 8mb intervals? > returnif(ret); > > I hope I'm not missing something obvious... No, you are absolutely right. I think I changed this once and no longer remembered what the final version did. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-18 22:40 ` Andrei Warkentin @ 2011-02-19 9:54 ` Arnd Bergmann -1 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-19 9:54 UTC (permalink / raw) To: Andrei Warkentin; +Cc: linux-arm-kernel, Linus Walleij, linux-mmc On Friday 18 February 2011 23:40:16 Andrei Warkentin wrote: > On Fri, Feb 18, 2011 at 1:47 PM, Andrei Warkentin <andreiw@motorola.com> wrote: > > Flashbench timings for both Sandisk and Toshiba cards. Attaching due to size. Very nice, thanks for the measurement! I don't think having the results inline in the mail is a problem, it would even make it easier to quote. > Some interesting things that I don't understand. For the align test, I > extended it to do a write align test (-A). I tried two partitions that > I could write over, and both read and writes behaved differently for > the two partitions on same device. Odd. They are both 4MB aligned. I never did a write align test because the results will be highly unreliable as soon as you get into thrashing. Your results seem to be meaningful still, so maybe we should have it after all, but I'll put a big warning on it. > On the sandisk it was the write align that made the page size stand > out. The read align had pretty constant results. I've noticed on other Sandisk media that the read align test is sometimes useless. It may help to do a full erase of the partition, or to fill it with data before running the test. > On the toshiba the results varied wildly for the two partitions. For > partition 6, there was a clear pattern in the diff values for read > align. For 9, it was all over the place. For 9 with the write align, > 8K and 16K the crossing writes took ~115ms!! Look in attached files > for all the data. Partition 6 is a lot smaller, so you have the accesses less than a segment apart, so it shows other effects. > The AU tests were interesting too, especially how with several open > AUs the throughput is higher for certain smaller sizes on sandisk, but > if I interpret it correctly both cards have at least 4 AUs, as I > didn't see yet a significant drop for small sizes. The larger ones I > am running now on mmcblk0p9 which is sufficiently larger for these > tests... (mmcblk0p6 is only 40mb, p9 is 314 mb) Right, you should try larger values for --open-au-nr here. It's at least a good sign that the drive can do random access inside a segment and that it can have at least 4 segments open. This is much better than I expected from your descriptions at first. However, the drop from 32 KB to 16 KB in performance is horrifying for the Toshiba drive, it's clear that this one does not like to be accessed smaller than 32 KB at a time, an obvious optimization for FAT32 with 32 KB clusters. How does this change with your kernel patches? For the sandisk drive, it's funny how it is consistently faster doing random access than linear access. I don't think I've seem that before. It does seem to have some cache for linear access using smaller than 16 KB, and can probably combine them when it's only writing to a single segment. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-19 9:54 ` Arnd Bergmann 0 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-19 9:54 UTC (permalink / raw) To: linux-arm-kernel On Friday 18 February 2011 23:40:16 Andrei Warkentin wrote: > On Fri, Feb 18, 2011 at 1:47 PM, Andrei Warkentin <andreiw@motorola.com> wrote: > > Flashbench timings for both Sandisk and Toshiba cards. Attaching due to size. Very nice, thanks for the measurement! I don't think having the results inline in the mail is a problem, it would even make it easier to quote. > Some interesting things that I don't understand. For the align test, I > extended it to do a write align test (-A). I tried two partitions that > I could write over, and both read and writes behaved differently for > the two partitions on same device. Odd. They are both 4MB aligned. I never did a write align test because the results will be highly unreliable as soon as you get into thrashing. Your results seem to be meaningful still, so maybe we should have it after all, but I'll put a big warning on it. > On the sandisk it was the write align that made the page size stand > out. The read align had pretty constant results. I've noticed on other Sandisk media that the read align test is sometimes useless. It may help to do a full erase of the partition, or to fill it with data before running the test. > On the toshiba the results varied wildly for the two partitions. For > partition 6, there was a clear pattern in the diff values for read > align. For 9, it was all over the place. For 9 with the write align, > 8K and 16K the crossing writes took ~115ms!! Look in attached files > for all the data. Partition 6 is a lot smaller, so you have the accesses less than a segment apart, so it shows other effects. > The AU tests were interesting too, especially how with several open > AUs the throughput is higher for certain smaller sizes on sandisk, but > if I interpret it correctly both cards have at least 4 AUs, as I > didn't see yet a significant drop for small sizes. The larger ones I > am running now on mmcblk0p9 which is sufficiently larger for these > tests... (mmcblk0p6 is only 40mb, p9 is 314 mb) Right, you should try larger values for --open-au-nr here. It's at least a good sign that the drive can do random access inside a segment and that it can have at least 4 segments open. This is much better than I expected from your descriptions at first. However, the drop from 32 KB to 16 KB in performance is horrifying for the Toshiba drive, it's clear that this one does not like to be accessed smaller than 32 KB at a time, an obvious optimization for FAT32 with 32 KB clusters. How does this change with your kernel patches? For the sandisk drive, it's funny how it is consistently faster doing random access than linear access. I don't think I've seem that before. It does seem to have some cache for linear access using smaller than 16 KB, and can probably combine them when it's only writing to a single segment. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-19 9:54 ` Arnd Bergmann @ 2011-02-20 4:39 ` Andrei Warkentin -1 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-20 4:39 UTC (permalink / raw) To: Arnd Bergmann; +Cc: linux-arm-kernel, Linus Walleij, linux-mmc On Sat, Feb 19, 2011 at 3:54 AM, Arnd Bergmann <arnd@arndb.de> wrote: > On Friday 18 February 2011 23:40:16 Andrei Warkentin wrote: >> On Fri, Feb 18, 2011 at 1:47 PM, Andrei Warkentin <andreiw@motorola.com> wrote: >> >> Flashbench timings for both Sandisk and Toshiba cards. Attaching due to size. > > Very nice, thanks for the measurement! > > I don't think having the results inline in the mail is a problem, > it would even make it easier to quote. > >> Some interesting things that I don't understand. For the align test, I >> extended it to do a write align test (-A). I tried two partitions that >> I could write over, and both read and writes behaved differently for >> the two partitions on same device. Odd. They are both 4MB aligned. > > I never did a write align test because the results will be highly > unreliable as soon as you get into thrashing. Your results seem > to be meaningful still, so maybe we should have it after all, but > I'll put a big warning on it. > Actually it would be a good idea to also bail/warn if you do the au test with more open au's than the size of the passed device allows, since it'll just wrap around and skew the results. >> On the sandisk it was the write align that made the page size stand >> out. The read align had pretty constant results. > > I've noticed on other Sandisk media that the read align test is > sometimes useless. It may help to do a full erase of the partition, > or to fill it with data before running the test. > >> On the toshiba the results varied wildly for the two partitions. For >> partition 6, there was a clear pattern in the diff values for read >> align. For 9, it was all over the place. For 9 with the write align, >> 8K and 16K the crossing writes took ~115ms!! Look in attached files >> for all the data. > > Partition 6 is a lot smaller, so you have the accesses less than a > segment apart, so it shows other effects. > >> The AU tests were interesting too, especially how with several open >> AUs the throughput is higher for certain smaller sizes on sandisk, but >> if I interpret it correctly both cards have at least 4 AUs, as I >> didn't see yet a significant drop for small sizes. The larger ones I >> am running now on mmcblk0p9 which is sufficiently larger for these >> tests... (mmcblk0p6 is only 40mb, p9 is 314 mb) > > Right, you should try larger values for --open-au-nr here. It's at > least a good sign that the drive can do random access inside a segment > and that it can have at least 4 segments open. This is much better > than I expected from your descriptions at first. Actually the Toshiba one seems to have 7 AUs if I interpret this correctly. ^C # ./flashbench -O -0 6 -b 512 /dev/block/mmcblk0p9 4MiB 5.91M/s 2MiB 8.84M/s 1MiB 10.8M/s 512KiB 13M/s 256KiB 13.6M/s ^C # ./flashbench -O -0 7 -b 512 /dev/block/mmcblk0p9 4MiB 6.32M/s 2MiB 8.63M/s 1MiB 10.5M/s 512KiB 13.2M/s 256KiB 13M/s ^[[A^[[D^[[A128KiB 12.3M/s ^C # ./flashbench -O -0 8 -b 512 /dev/block/mmcblk0p9 4MiB 6.65M/s 2MiB 7.02M/s 1MiB 6.36M/s 512KiB 3.17M/s 256KiB 1.53M/s The Sandisk one has 20 AUs. # ./flashbench -O -0 20 -b 512 /dev/block/mmcblk0p9 4MiB 11.3M/s 2MiB 12.8M/s 1MiB 9.87M/s 512KiB 9.97M/s 256KiB 9.13M/s 128KiB 8.05M/s ^C # ./flashbench -O -0 50 -b 512 /dev/block/mmcblk0p9 4MiB 7.19M/s ^C # ./flashbench -O -0 2 -b 512 /dev/block/mmcblk0p9 ^C # ./flashbench -O -0 22 -b 512 /dev/block/mmcblk0p9 4MiB 11.6M/s 2MiB 12.3M/s 1MiB 5.13M/s 512KiB 2.57M/s 256KiB 1.59M/s 128KiB 1.16M/s 64KiB 776K/s ^C # ./flashbench -O -0 21 -b 512 /dev/block/mmcblk0p9 4MiB 11.2M/s 2MiB 12.4M/s 1MiB 4.65M/s 512KiB 1.95M/s 256KiB 955K/s > > However, the drop from 32 KB to 16 KB in performance is horrifying > for the Toshiba drive, it's clear that this one does not like > to be accessed smaller than 32 KB at a time, an obvious optimization > for FAT32 with 32 KB clusters. How does this change with your > kernel patches? Since the only performance-increasing patch here would be just the one that splits unaligned accesses, I wouldn't expect any improvements for page-aligned accesses < 32KB. As you can see here... # cat /sys/block/mmcblk0/device/page_size 8192 # ./flashbench -O -0 1 -b 512 /dev/block/mmcblk0p9 4MiB 6.81M/s 2MiB 7.73M/s 1MiB 9.21M/s 512KiB 9.98M/s 256KiB 10.3M/s 128KiB 10.2M/s 64KiB 9.76M/s 32KiB 8.52M/s 16KiB 3.68M/s 8KiB 1.72M/s 4KiB 837K/s ^C # echo 0 > /sys/block/mmcblk0/device/page_size # ./flashbench -O -0 1 -b 512 /dev/block/mmcblk0p9 4MiB 6.42M/s 2MiB 7.79M/s 1MiB 9.22M/s 512KiB 10M/s 256KiB 9.94M/s 128KiB 10.1M/s 64KiB 9.68M/s 32KiB 8.5M/s 16KiB 3.65M/s 8KiB 1.73M/s 4KiB 838K/s 2KiB 417K/s ^C # > > For the sandisk drive, it's funny how it is consistently faster > doing random access than linear access. I don't think I've seem that > before. It does seem to have some cache for linear access using > smaller than 16 KB, and can probably combine them when it's only > writing to a single segment. Yes, that is pretty interesting. Smaller than 16K? Not smaller than 32K? I wonder what it is doing... ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-20 4:39 ` Andrei Warkentin 0 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-20 4:39 UTC (permalink / raw) To: linux-arm-kernel On Sat, Feb 19, 2011 at 3:54 AM, Arnd Bergmann <arnd@arndb.de> wrote: > On Friday 18 February 2011 23:40:16 Andrei Warkentin wrote: >> On Fri, Feb 18, 2011 at 1:47 PM, Andrei Warkentin <andreiw@motorola.com> wrote: >> >> Flashbench timings for both Sandisk and Toshiba cards. Attaching due to size. > > Very nice, thanks for the measurement! > > I don't think having the results inline in the mail is a problem, > it would even make it easier to quote. > >> Some interesting things that I don't understand. For the align test, I >> extended it to do a write align test (-A). I tried two partitions that >> I could write over, and both read and writes behaved differently for >> the two partitions on same device. Odd. They are both 4MB aligned. > > I never did a write align test because the results will be highly > unreliable as soon as you get into thrashing. Your results seem > to be meaningful still, so maybe we should have it after all, but > I'll put a big warning on it. > Actually it would be a good idea to also bail/warn if you do the au test with more open au's than the size of the passed device allows, since it'll just wrap around and skew the results. >> On the sandisk it was the write align that made the page size stand >> out. ?The read align had pretty constant results. > > I've noticed on other Sandisk media that the read align test is > sometimes useless. It may help to do a full erase of the partition, > or to fill it with data before running the test. > >> On the toshiba the results varied wildly for the two partitions. For >> partition 6, there was a clear pattern in the diff values for read >> align. For 9, it was all over the place. For 9 with the write align, >> 8K and 16K the crossing writes took ~115ms!! Look in attached files >> for all the data. > > Partition 6 is a lot smaller, so you have the accesses less than a > segment apart, so it shows other effects. > >> The AU tests were interesting too, especially how with several open >> AUs the throughput is higher for certain smaller sizes on sandisk, but >> if I interpret it correctly both cards have at least 4 AUs, as I >> didn't see yet a significant drop for small sizes. The larger ones I >> am running now on mmcblk0p9 which is sufficiently larger for these >> tests... (mmcblk0p6 is only 40mb, p9 is 314 mb) > > Right, you should try larger values for --open-au-nr here. It's at > least a good sign that the drive can do random access inside a segment > and that it can have at least 4 segments open. This is much better > than I expected from your descriptions at first. Actually the Toshiba one seems to have 7 AUs if I interpret this correctly. ^C # ./flashbench -O -0 6 -b 512 /dev/block/mmcblk0p9 4MiB 5.91M/s 2MiB 8.84M/s 1MiB 10.8M/s 512KiB 13M/s 256KiB 13.6M/s ^C # ./flashbench -O -0 7 -b 512 /dev/block/mmcblk0p9 4MiB 6.32M/s 2MiB 8.63M/s 1MiB 10.5M/s 512KiB 13.2M/s 256KiB 13M/s ^[[A^[[D^[[A128KiB 12.3M/s ^C # ./flashbench -O -0 8 -b 512 /dev/block/mmcblk0p9 4MiB 6.65M/s 2MiB 7.02M/s 1MiB 6.36M/s 512KiB 3.17M/s 256KiB 1.53M/s The Sandisk one has 20 AUs. # ./flashbench -O -0 20 -b 512 /dev/block/mmcblk0p9 4MiB 11.3M/s 2MiB 12.8M/s 1MiB 9.87M/s 512KiB 9.97M/s 256KiB 9.13M/s 128KiB 8.05M/s ^C # ./flashbench -O -0 50 -b 512 /dev/block/mmcblk0p9 4MiB 7.19M/s ^C # ./flashbench -O -0 2 -b 512 /dev/block/mmcblk0p9 ^C # ./flashbench -O -0 22 -b 512 /dev/block/mmcblk0p9 4MiB 11.6M/s 2MiB 12.3M/s 1MiB 5.13M/s 512KiB 2.57M/s 256KiB 1.59M/s 128KiB 1.16M/s 64KiB 776K/s ^C # ./flashbench -O -0 21 -b 512 /dev/block/mmcblk0p9 4MiB 11.2M/s 2MiB 12.4M/s 1MiB 4.65M/s 512KiB 1.95M/s 256KiB 955K/s > > However, the drop from 32 KB to 16 KB in performance is horrifying > for the Toshiba drive, it's clear that this one does not like > to be accessed smaller than 32 KB at a time, an obvious optimization > for FAT32 with 32 KB clusters. How does this change with your > kernel patches? Since the only performance-increasing patch here would be just the one that splits unaligned accesses, I wouldn't expect any improvements for page-aligned accesses < 32KB. As you can see here... # cat /sys/block/mmcblk0/device/page_size 8192 # ./flashbench -O -0 1 -b 512 /dev/block/mmcblk0p9 4MiB 6.81M/s 2MiB 7.73M/s 1MiB 9.21M/s 512KiB 9.98M/s 256KiB 10.3M/s 128KiB 10.2M/s 64KiB 9.76M/s 32KiB 8.52M/s 16KiB 3.68M/s 8KiB 1.72M/s 4KiB 837K/s ^C # echo 0 > /sys/block/mmcblk0/device/page_size # ./flashbench -O -0 1 -b 512 /dev/block/mmcblk0p9 4MiB 6.42M/s 2MiB 7.79M/s 1MiB 9.22M/s 512KiB 10M/s 256KiB 9.94M/s 128KiB 10.1M/s 64KiB 9.68M/s 32KiB 8.5M/s 16KiB 3.65M/s 8KiB 1.73M/s 4KiB 838K/s 2KiB 417K/s ^C # > > For the sandisk drive, it's funny how it is consistently faster > doing random access than linear access. I don't think I've seem that > before. It does seem to have some cache for linear access using > smaller than 16 KB, and can probably combine them when it's only > writing to a single segment. Yes, that is pretty interesting. Smaller than 16K? Not smaller than 32K? I wonder what it is doing... ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-20 4:39 ` Andrei Warkentin @ 2011-02-20 15:03 ` Arnd Bergmann -1 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-20 15:03 UTC (permalink / raw) To: linux-arm-kernel; +Cc: Andrei Warkentin, Linus Walleij, linux-mmc On Sunday 20 February 2011 05:39:06 Andrei Warkentin wrote: > Actually it would be a good idea to also bail/warn if you do the au > test with more open au's than the size of the passed device allows, > since it'll just wrap around and skew the results. Yes, that's a bug. I never noticed because all the devices I tested have much more space than the test can possibly exercise. I'll fix it tomorrow. > > Right, you should try larger values for --open-au-nr here. It's at > > least a good sign that the drive can do random access inside a segment > > and that it can have at least 4 segments open. This is much better > > than I expected from your descriptions at first. > > Actually the Toshiba one seems to have 7 AUs if I interpret this correctly. > ^C > # ./flashbench -O -0 6 -b 512 /dev/block/mmcblk0p9 > 4MiB 5.91M/s > 2MiB 8.84M/s > 1MiB 10.8M/s > 512KiB 13M/s > 256KiB 13.6M/s > > ^C > # ./flashbench -O -0 7 -b 512 /dev/block/mmcblk0p9 > 4MiB 6.32M/s > 2MiB 8.63M/s > 1MiB 10.5M/s > 512KiB 13.2M/s > 256KiB 13M/s > ^[[A^[[D^[[A128KiB 12.3M/s > ^C > # ./flashbench -O -0 8 -b 512 /dev/block/mmcblk0p9 > 4MiB 6.65M/s > 2MiB 7.02M/s > 1MiB 6.36M/s > 512KiB 3.17M/s > 256KiB 1.53M/s Yes, very good. I've never seen 7, but I've seen all other numbers betwen 1 and 8 ;-). > The Sandisk one has 20 AUs. > > # ./flashbench -O -0 20 -b 512 /dev/block/mmcblk0p9 > 4MiB 11.3M/s > 2MiB 12.8M/s > 1MiB 9.87M/s > 512KiB 9.97M/s > 256KiB 9.13M/s > 128KiB 8.05M/s > ^C > # ./flashbench -O -0 50 -b 512 /dev/block/mmcblk0p9 > 4MiB 7.19M/s > ^C > # ./flashbench -O -0 2 -b 512 /dev/block/mmcblk0p9 > ^C > # ./flashbench -O -0 22 -b 512 /dev/block/mmcblk0p9 > 4MiB 11.6M/s > 2MiB 12.3M/s > 1MiB 5.13M/s > 512KiB 2.57M/s > 256KiB 1.59M/s > 128KiB 1.16M/s > 64KiB 776K/s > ^C > # ./flashbench -O -0 21 -b 512 /dev/block/mmcblk0p9 > 4MiB 11.2M/s > 2MiB 12.4M/s > 1MiB 4.65M/s > 512KiB 1.95M/s > 256KiB 955K/s 20 is a lot, more than any other device I've tested, but that's good. Sandisk keeps impressing me ;-) Are you sure you have the allocation unit size correctly for this device and you don't get into the wrap-around bug you mention above? If it indeed uses 4 MB allocation units, flashbench will show only 10 open segments when run with --erasesize=$[8*1024*1024], but 20 open segments when run with --erasesize=$[2*1024*1024]. >From your flashbench -a run, I would guess that it uses 8 MB allocation units, although the data is not 100% conclusive there. > > However, the drop from 32 KB to 16 KB in performance is horrifying > > for the Toshiba drive, it's clear that this one does not like > > to be accessed smaller than 32 KB at a time, an obvious optimization > > for FAT32 with 32 KB clusters. How does this change with your > > kernel patches? > > Since the only performance-increasing patch here would be just the one > that splits unaligned accesses, I wouldn't expect any improvements for > page-aligned accesses < 32KB. As you can see here... Ok. > > For the sandisk drive, it's funny how it is consistently faster > > doing random access than linear access. I don't think I've seem that > > before. It does seem to have some cache for linear access using > > smaller than 16 KB, and can probably combine them when it's only > > writing to a single segment. > > Yes, that is pretty interesting. Smaller than 16K? Not smaller than > 32K? I wonder what it is doing... My interpretation is that it uses 16 KB pages, but can do two page-sized writes in a single access (multi-plane write). Anything smaller than a page goes to a temporary buffer first (like the Toshiba chip), but gets flushed when the next one is not contiguous. If you manage to fill the entire 16 KB page using small contiguous writes, it can do a single efficient write access instead. To confirm that 16 KB is the page size, you can try flashbench -s --scatter-span=1 --scatter-order=10 -o plot.data \ /dev/mmcblk1 -c 32 --blocksize=16384 gnuplot -p -e 'plot "plot.data" ' On most MLC flashes, this will show a pattern alternating between slow and fast pages like the one from https://lwn.net/Articles/428836/ Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-20 15:03 ` Arnd Bergmann 0 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-20 15:03 UTC (permalink / raw) To: linux-arm-kernel On Sunday 20 February 2011 05:39:06 Andrei Warkentin wrote: > Actually it would be a good idea to also bail/warn if you do the au > test with more open au's than the size of the passed device allows, > since it'll just wrap around and skew the results. Yes, that's a bug. I never noticed because all the devices I tested have much more space than the test can possibly exercise. I'll fix it tomorrow. > > Right, you should try larger values for --open-au-nr here. It's at > > least a good sign that the drive can do random access inside a segment > > and that it can have at least 4 segments open. This is much better > > than I expected from your descriptions at first. > > Actually the Toshiba one seems to have 7 AUs if I interpret this correctly. > ^C > # ./flashbench -O -0 6 -b 512 /dev/block/mmcblk0p9 > 4MiB 5.91M/s > 2MiB 8.84M/s > 1MiB 10.8M/s > 512KiB 13M/s > 256KiB 13.6M/s > > ^C > # ./flashbench -O -0 7 -b 512 /dev/block/mmcblk0p9 > 4MiB 6.32M/s > 2MiB 8.63M/s > 1MiB 10.5M/s > 512KiB 13.2M/s > 256KiB 13M/s > ^[[A^[[D^[[A128KiB 12.3M/s > ^C > # ./flashbench -O -0 8 -b 512 /dev/block/mmcblk0p9 > 4MiB 6.65M/s > 2MiB 7.02M/s > 1MiB 6.36M/s > 512KiB 3.17M/s > 256KiB 1.53M/s Yes, very good. I've never seen 7, but I've seen all other numbers betwen 1 and 8 ;-). > The Sandisk one has 20 AUs. > > # ./flashbench -O -0 20 -b 512 /dev/block/mmcblk0p9 > 4MiB 11.3M/s > 2MiB 12.8M/s > 1MiB 9.87M/s > 512KiB 9.97M/s > 256KiB 9.13M/s > 128KiB 8.05M/s > ^C > # ./flashbench -O -0 50 -b 512 /dev/block/mmcblk0p9 > 4MiB 7.19M/s > ^C > # ./flashbench -O -0 2 -b 512 /dev/block/mmcblk0p9 > ^C > # ./flashbench -O -0 22 -b 512 /dev/block/mmcblk0p9 > 4MiB 11.6M/s > 2MiB 12.3M/s > 1MiB 5.13M/s > 512KiB 2.57M/s > 256KiB 1.59M/s > 128KiB 1.16M/s > 64KiB 776K/s > ^C > # ./flashbench -O -0 21 -b 512 /dev/block/mmcblk0p9 > 4MiB 11.2M/s > 2MiB 12.4M/s > 1MiB 4.65M/s > 512KiB 1.95M/s > 256KiB 955K/s 20 is a lot, more than any other device I've tested, but that's good. Sandisk keeps impressing me ;-) Are you sure you have the allocation unit size correctly for this device and you don't get into the wrap-around bug you mention above? If it indeed uses 4 MB allocation units, flashbench will show only 10 open segments when run with --erasesize=$[8*1024*1024], but 20 open segments when run with --erasesize=$[2*1024*1024]. >From your flashbench -a run, I would guess that it uses 8 MB allocation units, although the data is not 100% conclusive there. > > However, the drop from 32 KB to 16 KB in performance is horrifying > > for the Toshiba drive, it's clear that this one does not like > > to be accessed smaller than 32 KB at a time, an obvious optimization > > for FAT32 with 32 KB clusters. How does this change with your > > kernel patches? > > Since the only performance-increasing patch here would be just the one > that splits unaligned accesses, I wouldn't expect any improvements for > page-aligned accesses < 32KB. As you can see here... Ok. > > For the sandisk drive, it's funny how it is consistently faster > > doing random access than linear access. I don't think I've seem that > > before. It does seem to have some cache for linear access using > > smaller than 16 KB, and can probably combine them when it's only > > writing to a single segment. > > Yes, that is pretty interesting. Smaller than 16K? Not smaller than > 32K? I wonder what it is doing... My interpretation is that it uses 16 KB pages, but can do two page-sized writes in a single access (multi-plane write). Anything smaller than a page goes to a temporary buffer first (like the Toshiba chip), but gets flushed when the next one is not contiguous. If you manage to fill the entire 16 KB page using small contiguous writes, it can do a single efficient write access instead. To confirm that 16 KB is the page size, you can try flashbench -s --scatter-span=1 --scatter-order=10 -o plot.data \ /dev/mmcblk1 -c 32 --blocksize=16384 gnuplot -p -e 'plot "plot.data" ' On most MLC flashes, this will show a pattern alternating between slow and fast pages like the one from https://lwn.net/Articles/428836/ Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-20 15:03 ` Arnd Bergmann @ 2011-02-22 6:42 ` Andrei Warkentin -1 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-22 6:42 UTC (permalink / raw) To: Arnd Bergmann; +Cc: linux-arm-kernel, Linus Walleij, linux-mmc [-- Attachment #1: Type: text/plain, Size: 1409 bytes --] On Sun, Feb 20, 2011 at 9:03 AM, Arnd Bergmann <arnd@arndb.de> wrote: > > From your flashbench -a run, I would guess that it uses > 8 MB allocation units, although the data is not 100% conclusive > there. > Because the 8MB aligned write time is significantly faster, right? > > My interpretation is that it uses 16 KB pages, but can do two page-sized > writes in a single access (multi-plane write). Anything smaller than > a page goes to a temporary buffer first (like the Toshiba chip), but > gets flushed when the next one is not contiguous. If you manage to fill > the entire 16 KB page using small contiguous writes, it can do a single > efficient write access instead. > > To confirm that 16 KB is the page size, you can try > > flashbench -s --scatter-span=1 --scatter-order=10 -o plot.data \ > /dev/mmcblk1 -c 32 --blocksize=16384 > gnuplot -p -e 'plot "plot.data" ' > > On most MLC flashes, this will show a pattern alternating between slow > and fast pages like the one from https://lwn.net/Articles/428836/ Cool. I am attaching some graphs. The 16k sandisk shows the slow and fast page parallel lines, as does the 8k toshiba (but we knew it for the toshiba case), but the boundaries are strange for the sandisk case, and there an interesting 2mb variation in the toshiba 8k graph. What is the correct way to interpret graphs with other block sizes? A [-- Attachment #2: scatter_8k_read_ts.png --] [-- Type: image/png, Size: 11238 bytes --] [-- Attachment #3: scatter_8k_sandisk.png --] [-- Type: image/png, Size: 8964 bytes --] [-- Attachment #4: scatter_16k_sandisk.png --] [-- Type: image/png, Size: 6853 bytes --] [-- Attachment #5: scatter_32k_read_ts.png --] [-- Type: image/png, Size: 9471 bytes --] [-- Attachment #6: scatter_32k_sandisk.png --] [-- Type: image/png, Size: 6790 bytes --] [-- Attachment #7: scatter_16k_read_ts.png --] [-- Type: image/png, Size: 9040 bytes --] ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-22 6:42 ` Andrei Warkentin 0 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-22 6:42 UTC (permalink / raw) To: linux-arm-kernel On Sun, Feb 20, 2011 at 9:03 AM, Arnd Bergmann <arnd@arndb.de> wrote: > > From your flashbench -a run, I would guess that it uses > 8 MB allocation units, although the data is not 100% conclusive > there. > Because the 8MB aligned write time is significantly faster, right? > > My interpretation is that it uses 16 KB pages, but can do two page-sized > writes in a single access (multi-plane write). Anything smaller than > a page goes to a temporary buffer first (like the Toshiba chip), but > gets flushed when the next one is not contiguous. If you manage to fill > the entire 16 KB page using small contiguous writes, it can do a single > efficient write access instead. > > To confirm that 16 KB is the page size, you can try > > flashbench -s --scatter-span=1 --scatter-order=10 -o plot.data \ > ? ? ? ?/dev/mmcblk1 -c 32 --blocksize=16384 > gnuplot -p -e 'plot "plot.data" ' > > On most MLC flashes, this will show a pattern alternating between slow > and fast pages like the one from https://lwn.net/Articles/428836/ Cool. I am attaching some graphs. The 16k sandisk shows the slow and fast page parallel lines, as does the 8k toshiba (but we knew it for the toshiba case), but the boundaries are strange for the sandisk case, and there an interesting 2mb variation in the toshiba 8k graph. What is the correct way to interpret graphs with other block sizes? A -------------- next part -------------- A non-text attachment was scrubbed... Name: scatter_8k_read_ts.png Type: image/png Size: 11238 bytes Desc: not available URL: <http://lists.infradead.org/pipermail/linux-arm-kernel/attachments/20110222/220679a1/attachment-0006.png> -------------- next part -------------- A non-text attachment was scrubbed... Name: scatter_8k_sandisk.png Type: image/png Size: 8964 bytes Desc: not available URL: <http://lists.infradead.org/pipermail/linux-arm-kernel/attachments/20110222/220679a1/attachment-0007.png> -------------- next part -------------- A non-text attachment was scrubbed... Name: scatter_16k_sandisk.png Type: image/png Size: 6853 bytes Desc: not available URL: <http://lists.infradead.org/pipermail/linux-arm-kernel/attachments/20110222/220679a1/attachment-0008.png> -------------- next part -------------- A non-text attachment was scrubbed... Name: scatter_32k_read_ts.png Type: image/png Size: 9471 bytes Desc: not available URL: <http://lists.infradead.org/pipermail/linux-arm-kernel/attachments/20110222/220679a1/attachment-0009.png> -------------- next part -------------- A non-text attachment was scrubbed... Name: scatter_32k_sandisk.png Type: image/png Size: 6790 bytes Desc: not available URL: <http://lists.infradead.org/pipermail/linux-arm-kernel/attachments/20110222/220679a1/attachment-0010.png> -------------- next part -------------- A non-text attachment was scrubbed... Name: scatter_16k_read_ts.png Type: image/png Size: 9040 bytes Desc: not available URL: <http://lists.infradead.org/pipermail/linux-arm-kernel/attachments/20110222/220679a1/attachment-0011.png> ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-22 6:42 ` Andrei Warkentin @ 2011-02-22 16:42 ` Arnd Bergmann -1 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-22 16:42 UTC (permalink / raw) To: Andrei Warkentin; +Cc: linux-arm-kernel, Linus Walleij, linux-mmc On Tuesday 22 February 2011, Andrei Warkentin wrote: > On Sun, Feb 20, 2011 at 9:03 AM, Arnd Bergmann <arnd@arndb.de> wrote: > > > > From your flashbench -a run, I would guess that it uses > > 8 MB allocation units, although the data is not 100% conclusive > > there. > > > > Because the 8MB aligned write time is significantly faster, right? I mean because a read spanning an 8 MB boundary is noticably slower than one spanning a 4 MB boundary (diff 242µs instead of 187µs), while everything below the numbers for the 4 and 2 MB boundaries are quite similar. > I am attaching some graphs. The 16k sandisk shows the slow and fast > page parallel lines, as does the 8k toshiba (but we knew it for the > toshiba case), but the boundaries are strange for the sandisk case, > and there an interesting 2mb variation in the toshiba 8k graph. What > is the correct way to interpret graphs with other block sizes? Not sure if it's correct, but my interpretation of your output is this: In the Toshiba graph, you see parallel lines that show measurements 30µs apart, e.g. 1.06ms and 1.09 ms in the first one. I assume what you see here are fast and slow pages, respectively. It's a bit hard to tell in the resolution you have, and it would make sense to zoom into the picture to see if they are alternating or just random. The three groups of double lines are probably just some jitter from the timing of the interrupt controller. If you run with a larger --count= value, these should become less visible. The sandisk plot shows some sector ranges taht are slower than others, I'd assume that those are the ones that have been recently written. The 16KB page plot has parallel lines (again, I'd have to see a finer resolution plot to see if they are alternating), which the 32KB page plot does not have. I see this as an indication that the pages are indeed 16KB, and in the 32KB plot the results are just averaged out. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-22 16:42 ` Arnd Bergmann 0 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-22 16:42 UTC (permalink / raw) To: linux-arm-kernel On Tuesday 22 February 2011, Andrei Warkentin wrote: > On Sun, Feb 20, 2011 at 9:03 AM, Arnd Bergmann <arnd@arndb.de> wrote: > > > > From your flashbench -a run, I would guess that it uses > > 8 MB allocation units, although the data is not 100% conclusive > > there. > > > > Because the 8MB aligned write time is significantly faster, right? I mean because a read spanning an 8 MB boundary is noticably slower than one spanning a 4 MB boundary (diff 242?s instead of 187?s), while everything below the numbers for the 4 and 2 MB boundaries are quite similar. > I am attaching some graphs. The 16k sandisk shows the slow and fast > page parallel lines, as does the 8k toshiba (but we knew it for the > toshiba case), but the boundaries are strange for the sandisk case, > and there an interesting 2mb variation in the toshiba 8k graph. What > is the correct way to interpret graphs with other block sizes? Not sure if it's correct, but my interpretation of your output is this: In the Toshiba graph, you see parallel lines that show measurements 30?s apart, e.g. 1.06ms and 1.09 ms in the first one. I assume what you see here are fast and slow pages, respectively. It's a bit hard to tell in the resolution you have, and it would make sense to zoom into the picture to see if they are alternating or just random. The three groups of double lines are probably just some jitter from the timing of the interrupt controller. If you run with a larger --count= value, these should become less visible. The sandisk plot shows some sector ranges taht are slower than others, I'd assume that those are the ones that have been recently written. The 16KB page plot has parallel lines (again, I'd have to see a finer resolution plot to see if they are alternating), which the 32KB page plot does not have. I see this as an indication that the pages are indeed 16KB, and in the 32KB plot the results are just averaged out. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-09 9:13 ` Arnd Bergmann @ 2011-02-11 23:23 ` Linus Walleij -1 siblings, 0 replies; 117+ messages in thread From: Linus Walleij @ 2011-02-11 23:23 UTC (permalink / raw) To: Arnd Bergmann Cc: linux-arm-kernel, Andrei Warkentin, linux-mmc, Sebastian Rasmussen, Ulf Hansson 2011/2/9 Arnd Bergmann <arnd@arndb.de>: > Most of my results so far are documented on > https://wiki.linaro.org/WorkingGroups/KernelConsolidation/Projects/FlashCardSurvey H'm! That's an interesting resource indeed. When you write "From measurements, it appears that the size in which data is managed is typically 64 kb on SD cards" and "the size of the medium is always a multiple of entire allocation groups, and the most common size today is 4 MB" and then list Size, Allocation Unit, Write Size, Page Size, FAT Location, open AUs linear, open AUs random, Algorithm. How exactly do you measure that? I'm sort of smelling a card-probe.git with this tool that you can run on your device and get out data like that listed in your table. We have a rather large stash of cards we can probe for you to get that kind of data out if it is useful, and I believe other Linaro members may have such stuff too, if empirical data is usefult to your work. Yours, Linus Walleij ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-11 23:23 ` Linus Walleij 0 siblings, 0 replies; 117+ messages in thread From: Linus Walleij @ 2011-02-11 23:23 UTC (permalink / raw) To: linux-arm-kernel 2011/2/9 Arnd Bergmann <arnd@arndb.de>: > Most of my results so far are documented on > https://wiki.linaro.org/WorkingGroups/KernelConsolidation/Projects/FlashCardSurvey H'm! That's an interesting resource indeed. When you write "From measurements, it appears that the size in which data is managed is typically 64 kb on SD cards" and "the size of the medium is always a multiple of entire allocation groups, and the most common size today is 4 MB" and then list Size, Allocation Unit, Write Size, Page Size, FAT Location, open AUs linear, open AUs random, Algorithm. How exactly do you measure that? I'm sort of smelling a card-probe.git with this tool that you can run on your device and get out data like that listed in your table. We have a rather large stash of cards we can probe for you to get that kind of data out if it is useful, and I believe other Linaro members may have such stuff too, if empirical data is usefult to your work. Yours, Linus Walleij ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-11 23:23 ` Linus Walleij @ 2011-02-12 10:45 ` Arnd Bergmann -1 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-12 10:45 UTC (permalink / raw) To: Linus Walleij Cc: linux-arm-kernel, Andrei Warkentin, linux-mmc, Sebastian Rasmussen, Ulf Hansson On Saturday 12 February 2011 00:23:37 Linus Walleij wrote: > H'm! That's an interesting resource indeed. When you write > "From measurements, it appears that the size in which data is > managed is typically 64 kb on SD cards" and "the size of the > medium is always a multiple of entire allocation groups, and > the most common size today is 4 MB" and then list > Size, Allocation Unit, Write Size, Page Size, FAT Location, > open AUs linear, open AUs random, Algorithm. > > How exactly do you measure that? It's not an exact science, but for most cards I have found reasonably good ways to identify these numbers: * the allocation unit size can almost always be found using read-only tests: reading 2kb across an allocation unit boundary is slightly slower than reading 2kb just before or just after the boundary. For a few cards where this doesn't work, I do write tests. After finding out how many allocation units can be open, it's trivial to find out the size. * Finding the number of open allocation units means I write to the start of a few AUs alternating. Up to a certain number, the throughput is constant, above that, it drops sharply, sometimes by one or two orders of magnitude. * The page size can also be found doing read-only tests, with varying block sizes. Smaller reads always give lower throughput than larger reads, but getting smaller than page size drops down significantly more than the difference between multi-page reads. This effect is more prominent in write tests. * Finding the algorithm basically means I write an allocation unit using varying block sizes two times, using both linear access and random access. Cards that are optimized for linear access can be unbelievably slow in the random access tests. Sometimes the performance is the same above a specific block size, but slower for random access below that size. This is the write block size. * Finding the write block size in cases where this is not the case can be harder. Most cards have a noticable performance drop in writes of less than a few pages, so that's the size I put in the table. * The FAT location is clearly visible in a number of tests done inside of an allocation unit. It's normally slower for linear access, but faster for random access. Sometimes reading the FAT is also slower than reading elsewhere. > I'm sort of smelling a card-probe.git with this tool that you > can run on your device and get out data like that listed > in your table. We have a rather large stash of cards we can > probe for you to get that kind of data out if it is useful, and > I believe other Linaro members may have such stuff too, > if empirical data is usefult to your work. The tool I'm using is on http://git.linaro.org/gitweb?p=people/arnd/flashbench.git Unfortunately, it's not yet in the state that I'm recommending anyone besides me to run it. I'm still rewriting the source for every new card I get to nail down the specific properties. I will make an announcement when I have the tool in a state of general usefulness, and at that point I would really appreciate people to run it, but just not yet. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-12 10:45 ` Arnd Bergmann 0 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-12 10:45 UTC (permalink / raw) To: linux-arm-kernel On Saturday 12 February 2011 00:23:37 Linus Walleij wrote: > H'm! That's an interesting resource indeed. When you write > "From measurements, it appears that the size in which data is > managed is typically 64 kb on SD cards" and "the size of the > medium is always a multiple of entire allocation groups, and > the most common size today is 4 MB" and then list > Size, Allocation Unit, Write Size, Page Size, FAT Location, > open AUs linear, open AUs random, Algorithm. > > How exactly do you measure that? It's not an exact science, but for most cards I have found reasonably good ways to identify these numbers: * the allocation unit size can almost always be found using read-only tests: reading 2kb across an allocation unit boundary is slightly slower than reading 2kb just before or just after the boundary. For a few cards where this doesn't work, I do write tests. After finding out how many allocation units can be open, it's trivial to find out the size. * Finding the number of open allocation units means I write to the start of a few AUs alternating. Up to a certain number, the throughput is constant, above that, it drops sharply, sometimes by one or two orders of magnitude. * The page size can also be found doing read-only tests, with varying block sizes. Smaller reads always give lower throughput than larger reads, but getting smaller than page size drops down significantly more than the difference between multi-page reads. This effect is more prominent in write tests. * Finding the algorithm basically means I write an allocation unit using varying block sizes two times, using both linear access and random access. Cards that are optimized for linear access can be unbelievably slow in the random access tests. Sometimes the performance is the same above a specific block size, but slower for random access below that size. This is the write block size. * Finding the write block size in cases where this is not the case can be harder. Most cards have a noticable performance drop in writes of less than a few pages, so that's the size I put in the table. * The FAT location is clearly visible in a number of tests done inside of an allocation unit. It's normally slower for linear access, but faster for random access. Sometimes reading the FAT is also slower than reading elsewhere. > I'm sort of smelling a card-probe.git with this tool that you > can run on your device and get out data like that listed > in your table. We have a rather large stash of cards we can > probe for you to get that kind of data out if it is useful, and > I believe other Linaro members may have such stuff too, > if empirical data is usefult to your work. The tool I'm using is on http://git.linaro.org/gitweb?p=people/arnd/flashbench.git Unfortunately, it's not yet in the state that I'm recommending anyone besides me to run it. I'm still rewriting the source for every new card I get to nail down the specific properties. I will make an announcement when I have the tool in a state of general usefulness, and at that point I would really appreciate people to run it, but just not yet. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-12 10:45 ` Arnd Bergmann @ 2011-02-12 10:59 ` Russell King - ARM Linux -1 siblings, 0 replies; 117+ messages in thread From: Russell King - ARM Linux @ 2011-02-12 10:59 UTC (permalink / raw) To: Arnd Bergmann Cc: Linus Walleij, Ulf Hansson, linux-mmc, Andrei Warkentin, linux-arm-kernel, Sebastian Rasmussen On Sat, Feb 12, 2011 at 11:45:41AM +0100, Arnd Bergmann wrote: > * The FAT location is clearly visible in a number of tests > done inside of an allocation unit. It's normally slower for > linear access, but faster for random access. Sometimes > reading the FAT is also slower than reading elsewhere. I wouldn't also be surprised if there's some cards out there which parse the FAT being written, and start activities (such as erasing clusters) based upon changes therein. Such cards would be unsuitable for use with non-FAT filesystems. It might be worth devising some sort of check for this kind of behaviour. Unrelated, I have a USB based device which provides an emulated FAT filesystem - all files except one on this filesystem are read-only. The writable file is a textual configuration file. It can be reliably updated by Windows based systems, but updates from Linux based systems are ignored - presumably because updates to the FAT/directory/data clusters are occuring in a different order. ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-12 10:59 ` Russell King - ARM Linux 0 siblings, 0 replies; 117+ messages in thread From: Russell King - ARM Linux @ 2011-02-12 10:59 UTC (permalink / raw) To: linux-arm-kernel On Sat, Feb 12, 2011 at 11:45:41AM +0100, Arnd Bergmann wrote: > * The FAT location is clearly visible in a number of tests > done inside of an allocation unit. It's normally slower for > linear access, but faster for random access. Sometimes > reading the FAT is also slower than reading elsewhere. I wouldn't also be surprised if there's some cards out there which parse the FAT being written, and start activities (such as erasing clusters) based upon changes therein. Such cards would be unsuitable for use with non-FAT filesystems. It might be worth devising some sort of check for this kind of behaviour. Unrelated, I have a USB based device which provides an emulated FAT filesystem - all files except one on this filesystem are read-only. The writable file is a textual configuration file. It can be reliably updated by Windows based systems, but updates from Linux based systems are ignored - presumably because updates to the FAT/directory/data clusters are occuring in a different order. ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-12 10:59 ` Russell King - ARM Linux @ 2011-02-12 16:28 ` Arnd Bergmann -1 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-12 16:28 UTC (permalink / raw) To: Russell King - ARM Linux Cc: Linus Walleij, Ulf Hansson, linux-mmc, Andrei Warkentin, linux-arm-kernel, Sebastian Rasmussen On Saturday 12 February 2011 11:59:18 Russell King - ARM Linux wrote: > On Sat, Feb 12, 2011 at 11:45:41AM +0100, Arnd Bergmann wrote: > > * The FAT location is clearly visible in a number of tests > > done inside of an allocation unit. It's normally slower for > > linear access, but faster for random access. Sometimes > > reading the FAT is also slower than reading elsewhere. > > I wouldn't also be surprised if there's some cards out there which parse > the FAT being written, and start activities (such as erasing clusters) > based upon changes therein. Such cards would be unsuitable for use with > non-FAT filesystems. > > It might be worth devising some sort of check for this kind of behaviour. Possible, but doesn't seem to happen with any of the cards I have tested, the controllers in there appear to be too simplistic. Also, the recommendations for SD cards are to issue explicit erase requests, which would make this unnecessary. OTOH, SD cards do specify exactly where the FAT should be stored on the medium, so it would be possible to make this kind of assumption. USB sticks and CF cards might be smart enough to actually do it, some of them have more sophisticated logic than SD cards (most do not), and there is no usb mass storage command for erase. > Unrelated, I have a USB based device which provides an emulated FAT > filesystem - all files except one on this filesystem are read-only. > The writable file is a textual configuration file. It can be reliably > updated by Windows based systems, but updates from Linux based systems > are ignored - presumably because updates to the FAT/directory/data > clusters are occuring in a different order. Fun. I think qemu also comes with one of these FAT emulation layers, as do some mp3 players, but from what I have heard, they are not as broken. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-12 16:28 ` Arnd Bergmann 0 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-12 16:28 UTC (permalink / raw) To: linux-arm-kernel On Saturday 12 February 2011 11:59:18 Russell King - ARM Linux wrote: > On Sat, Feb 12, 2011 at 11:45:41AM +0100, Arnd Bergmann wrote: > > * The FAT location is clearly visible in a number of tests > > done inside of an allocation unit. It's normally slower for > > linear access, but faster for random access. Sometimes > > reading the FAT is also slower than reading elsewhere. > > I wouldn't also be surprised if there's some cards out there which parse > the FAT being written, and start activities (such as erasing clusters) > based upon changes therein. Such cards would be unsuitable for use with > non-FAT filesystems. > > It might be worth devising some sort of check for this kind of behaviour. Possible, but doesn't seem to happen with any of the cards I have tested, the controllers in there appear to be too simplistic. Also, the recommendations for SD cards are to issue explicit erase requests, which would make this unnecessary. OTOH, SD cards do specify exactly where the FAT should be stored on the medium, so it would be possible to make this kind of assumption. USB sticks and CF cards might be smart enough to actually do it, some of them have more sophisticated logic than SD cards (most do not), and there is no usb mass storage command for erase. > Unrelated, I have a USB based device which provides an emulated FAT > filesystem - all files except one on this filesystem are read-only. > The writable file is a textual configuration file. It can be reliably > updated by Windows based systems, but updates from Linux based systems > are ignored - presumably because updates to the FAT/directory/data > clusters are occuring in a different order. Fun. I think qemu also comes with one of these FAT emulation layers, as do some mp3 players, but from what I have heard, they are not as broken. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-12 16:28 ` Arnd Bergmann @ 2011-02-12 16:37 ` Russell King - ARM Linux -1 siblings, 0 replies; 117+ messages in thread From: Russell King - ARM Linux @ 2011-02-12 16:37 UTC (permalink / raw) To: Arnd Bergmann Cc: Linus Walleij, Ulf Hansson, linux-mmc, Andrei Warkentin, linux-arm-kernel, Sebastian Rasmussen On Sat, Feb 12, 2011 at 05:28:32PM +0100, Arnd Bergmann wrote: > On Saturday 12 February 2011 11:59:18 Russell King - ARM Linux wrote: > > Unrelated, I have a USB based device which provides an emulated FAT > > filesystem - all files except one on this filesystem are read-only. > > The writable file is a textual configuration file. It can be reliably > > updated by Windows based systems, but updates from Linux based systems > > are ignored - presumably because updates to the FAT/directory/data > > clusters are occuring in a different order. > > Fun. I think qemu also comes with one of these FAT emulation layers, > as do some mp3 players, but from what I have heard, they are not as > broken. Given that it is a secure GPS/barographic flight logger which has approval for ratifing world record flight claims, you may understand why it has to be extremely picky about how it interfaces with the external world. Especially restricting updates to modification of the configuration file, while not allowing any of the logged data files to be changed in any way. ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-12 16:37 ` Russell King - ARM Linux 0 siblings, 0 replies; 117+ messages in thread From: Russell King - ARM Linux @ 2011-02-12 16:37 UTC (permalink / raw) To: linux-arm-kernel On Sat, Feb 12, 2011 at 05:28:32PM +0100, Arnd Bergmann wrote: > On Saturday 12 February 2011 11:59:18 Russell King - ARM Linux wrote: > > Unrelated, I have a USB based device which provides an emulated FAT > > filesystem - all files except one on this filesystem are read-only. > > The writable file is a textual configuration file. It can be reliably > > updated by Windows based systems, but updates from Linux based systems > > are ignored - presumably because updates to the FAT/directory/data > > clusters are occuring in a different order. > > Fun. I think qemu also comes with one of these FAT emulation layers, > as do some mp3 players, but from what I have heard, they are not as > broken. Given that it is a secure GPS/barographic flight logger which has approval for ratifing world record flight claims, you may understand why it has to be extremely picky about how it interfaces with the external world. Especially restricting updates to modification of the configuration file, while not allowing any of the logged data files to be changed in any way. ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-09 8:37 ` Linus Walleij @ 2011-02-11 22:27 ` Andrei Warkentin -1 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-11 22:27 UTC (permalink / raw) To: Linus Walleij; +Cc: linux-mmc, linux-arm-kernel [-- Attachment #1: Type: text/plain, Size: 2350 bytes --] On Wed, Feb 9, 2011 at 2:37 AM, Linus Walleij <linus.walleij@linaro.org> wrote: > [Quoting in verbatin so the orginal mail hits linux-mmc, this is very > interesting!] > > 2011/2/8 Andrei Warkentin <andreiw@motorola.com>: >> Hi, >> >> I'm not sure if this is the best place to bring this up, but Russel's >> name is on a fair share of drivers/mmc code, and there does seem to be >> quite a bit of MMC-related discussions. Excuse me in advance if this >> isn't the right forum :-). >> >> Certain MMC vendors (maybe even quite a bit of them) use a pretty >> rigid buffering scheme when it comes to handling writes. There is >> usually a buffer A for random accesses, and a buffer B for sequential >> accesses. For certain Toshiba parts, it looks like buffer A is 8KB >> wide, with buffer B being 4MB wide, and all accesses larger than 8KB >> effectively equating to 4MB accesses. Worse, consecutive small (8k) >> writes are treated as one large sequential access, once again ending >> up in buffer B, thus necessitating out-of-order writing to work around >> this. >> >> What this means is decreased life span for the parts, and it also >> means a performance impact on small writes, but the first item is much >> more crucial, especially for smaller parts. >> >> As I've mentioned, probably more vendors are affected. How about a >> generic MMC_BLOCK quirk that splits the requests (and optionally >> reorders) them? The thresholds would then be adjustable as >> module/kernel parameters based on manfid. I'm asking because I have a >> patch now, but its ugly and hardcoded against a specific manufacturer. > > There is a quirk API so that specific quirks can be flagged for certain > vendors and cards, e.g. some Toshibas in this case. e.g. grep the > kernel source for MMC_QUIRK_BLKSZ_FOR_BYTE_MODE. > > But as Russell says this probably needs to be signalled up to the > block layer to be handled properly. > > Why don't you post the code you have today as an RFC: patch, > I think many will be interested? > > Yours, > Linus Walleij > I think it's worthwhile to make make the upper block layers aware of MMC (and apparently other flash memory) limitations, but I think as a first step it could make sense (for me) to reformat the patch I am attaching into something that looks better. Don't take the attached patch too seriously :-). Thanks, A [-- Attachment #2: toshiba_emmc_opt.patch --] [-- Type: text/x-diff, Size: 8738 bytes --] diff --git a/drivers/mmc/card/block.c b/drivers/mmc/card/block.c index 7054fd5..3b32329 100644 --- a/drivers/mmc/card/block.c +++ b/drivers/mmc/card/block.c @@ -60,6 +60,7 @@ struct mmc_blk_data { spinlock_t lock; struct gendisk *disk; struct mmc_queue queue; + char *bounce; unsigned int usage; unsigned int read_only; @@ -93,6 +94,9 @@ static void mmc_blk_put(struct mmc_blk_data *md) __clear_bit(devidx, dev_use); + if (md->bounce) + kfree(md->bounce); + put_disk(md->disk); kfree(md); } @@ -312,6 +316,157 @@ out: return err ? 0 : 1; } +/* + * Workaround for Toshiba eMMC performance. If the request is less than two + * flash pages in size, then we want to split the write into one or two + * page-aligned writes to take advantage of faster buffering. Here we can + * adjust the size of the MMC request and let the block layer request handler + * deal with generating another MMC request. + */ +#define TOSHIBA_MANFID 0x11 +#define TOSHIBA_PAGE_SIZE 16 /* sectors */ +#define TOSHIBA_ADJUST_THRESHOLD 24 /* sectors */ +static bool mmc_adjust_toshiba_write(struct mmc_card *card, + struct mmc_request *mrq) +{ + if (mmc_card_mmc(card) && card->cid.manfid == TOSHIBA_MANFID && + mrq->data->blocks <= TOSHIBA_ADJUST_THRESHOLD) { + int sectors_in_page = TOSHIBA_PAGE_SIZE - + (mrq->cmd->arg % TOSHIBA_PAGE_SIZE); + if (mrq->data->blocks > sectors_in_page) { + mrq->data->blocks = sectors_in_page; + return true; + } + } + + return false; +} + +/* + * This is another strange workaround to try to close the gap on Toshiba eMMC + * performance when compared to other vendors. In order to take advantage + * of certain optimizations and assumptions in those cards, we will look for + * multiblock write transfers below a certain size and we do the following: + * + * - Break them up into seperate page-aligned (8k flash pages) transfers. + * - Execute the transfers in reverse order. + * - Use "reliable write" transfer mode. + * + * Neither the block I/O layer nor the scatterlist design seem to lend them- + * selves well to executing a block request out of order. So instead we let + * mmc_blk_issue_rq() setup the MMC request for the entire transfer and then + * break it up and reorder it here. This also requires that we put the data + * into a bounce buffer and send it as individual sg's. + */ +#define TOSHIBA_LOW_THRESHOLD 48 /* sectors */ +#define TOSHIBA_HIGH_THRESHOLD 64 /* sectors */ +static bool mmc_handle_toshiba_write(struct mmc_queue *mq, + struct mmc_card *card, + struct mmc_request *mrq) +{ + struct mmc_blk_data *md = mq->data; + unsigned int first_page, last_page, page; + unsigned long flags; + + if (!md->bounce || + mrq->data->blocks > TOSHIBA_HIGH_THRESHOLD || + mrq->data->blocks < TOSHIBA_LOW_THRESHOLD) + return false; + + first_page = mrq->cmd->arg / TOSHIBA_PAGE_SIZE; + last_page = (mrq->cmd->arg + mrq->data->blocks - 1) / TOSHIBA_PAGE_SIZE; + + /* Single page write: just do it the normal way */ + if (first_page == last_page) + return false; + + local_irq_save(flags); + sg_copy_to_buffer(mrq->data->sg, mrq->data->sg_len, + md->bounce, mrq->data->blocks * 512); + local_irq_restore(flags); + + for (page = last_page; page >= first_page; page--) { + unsigned long offset, length; + struct mmc_blk_request brq; + struct mmc_command cmd; + struct scatterlist sg; + + memset(&brq, 0, sizeof(struct mmc_blk_request)); + brq.mrq.cmd = &brq.cmd; + brq.mrq.data = &brq.data; + + brq.cmd.arg = page * TOSHIBA_PAGE_SIZE; + brq.data.blksz = 512; + if (page == first_page) { + brq.cmd.arg = mrq->cmd->arg; + brq.data.blocks = TOSHIBA_PAGE_SIZE - + (mrq->cmd->arg % TOSHIBA_PAGE_SIZE); + } else if (page == last_page) + brq.data.blocks = (mrq->cmd->arg + mrq->data->blocks) % + TOSHIBA_PAGE_SIZE; + if (brq.data.blocks == 0) + brq.data.blocks = TOSHIBA_PAGE_SIZE; + + if (!mmc_card_blockaddr(card)) + brq.cmd.arg <<= 9; + brq.cmd.flags = MMC_RSP_SPI_R1 | MMC_RSP_R1 | MMC_CMD_ADTC; + brq.stop.opcode = MMC_STOP_TRANSMISSION; + brq.stop.arg = 0; + brq.stop.flags = MMC_RSP_SPI_R1B | MMC_RSP_R1B | MMC_CMD_AC; + + brq.data.flags |= MMC_DATA_WRITE; + if (brq.data.blocks > 1) { + if (!mmc_host_is_spi(card->host)) + brq.mrq.stop = &brq.stop; + brq.cmd.opcode = MMC_WRITE_MULTIPLE_BLOCK; + } else { + brq.mrq.stop = NULL; + brq.cmd.opcode = MMC_WRITE_BLOCK; + } + + if (brq.cmd.opcode == MMC_WRITE_MULTIPLE_BLOCK && + brq.data.blocks <= card->ext_csd.rel_wr_sec_c) { + int err; + + cmd.opcode = MMC_SET_BLOCK_COUNT; + cmd.arg = brq.data.blocks | (1 << 31); + cmd.flags = MMC_RSP_R1 | MMC_CMD_AC; + err = mmc_wait_for_cmd(card->host, &cmd, 0); + if (!err) + brq.mrq.stop = NULL; + } + + mmc_set_data_timeout(&brq.data, card); + + offset = (brq.cmd.arg - mrq->cmd->arg) * 512; + length = brq.data.blocks * 512; + sg_init_one(&sg, md->bounce + offset, length); + brq.data.sg = &sg; + brq.data.sg_len = 1; + + mmc_wait_for_req(card->host, &brq.mrq); + + mrq->data->bytes_xfered += brq.data.bytes_xfered; + + if (brq.cmd.error || brq.data.error || brq.stop.error) { + mrq->cmd->error = brq.cmd.error; + mrq->data->error = brq.data.error; + mrq->stop->error = brq.stop.error; + + /* + * We're executing the request backwards, so don't let + * the block layer think some part of it has succeeded. + * It will get it wrong. Since the failure will cause + * us to fall back on single block writes, we're better + * off reporting that none of the data was written. + */ + mrq->data->bytes_xfered = 0; + break; + } + } + + return true; +} static int mmc_blk_issue_rw_rq(struct mmc_queue *mq, struct request *req) { struct mmc_blk_data *md = mq->data; @@ -378,6 +533,9 @@ static int mmc_blk_issue_rw_rq(struct mmc_queue *mq, struct request *req) brq.data.flags |= MMC_DATA_WRITE; } + if (rq_data_dir(req) == WRITE) + mmc_adjust_toshiba_write(card, &brq.mrq); + mmc_set_data_timeout(&brq.data, card); brq.data.sg = mq->sg; @@ -402,9 +560,14 @@ static int mmc_blk_issue_rw_rq(struct mmc_queue *mq, struct request *req) brq.data.sg_len = i; } - mmc_queue_bounce_pre(mq); - - mmc_wait_for_req(card->host, &brq.mrq); + mmc_queue_bounce_pre(mq); + + /* + * Try the workaround first for writes, then fall back. + */ + if (rq_data_dir(req) != WRITE || disable_multi || + !mmc_handle_toshiba_write(mq, card, &brq.mrq)) + mmc_wait_for_req(card->host, &brq.mrq); mmc_queue_bounce_post(mq); @@ -589,6 +752,15 @@ static struct mmc_blk_data *mmc_blk_alloc(struct mmc_card *card) goto out; } + if (card->cid.manfid == TOSHIBA_MANFID && mmc_card_mmc(card)) { + pr_info("%s: enable Toshiba workaround\n", + mmc_hostname(card->host)); + md->bounce = kmalloc(TOSHIBA_HIGH_THRESHOLD * 512, GFP_KERNEL); + if (!md->bounce) { + ret = -ENOMEM; + goto err_kfree; + } + } /* * Set the read-only status based on the supported commands @@ -655,6 +827,8 @@ static struct mmc_blk_data *mmc_blk_alloc(struct mmc_card *card) err_putdisk: put_disk(md->disk); err_kfree: + if (md->bounce) + kfree(md->bounce); kfree(md); out: return ERR_PTR(ret); diff --git a/drivers/mmc/core/mmc.c b/drivers/mmc/core/mmc.c index 45055c4..17eef89 100644 --- a/drivers/mmc/core/mmc.c +++ b/drivers/mmc/core/mmc.c @@ -307,6 +307,9 @@ static int mmc_read_ext_csd(struct mmc_card *card) else card->erased_byte = 0x0; + if (card->ext_csd.rev >= 5) + card->ext_csd.rel_wr_sec_c = ext_csd[EXT_CSD_REL_WR_SEC_C]; + out: kfree(ext_csd); diff --git a/include/linux/mmc/card.h b/include/linux/mmc/card.h index 6b75250..fea7ecb 100644 --- a/include/linux/mmc/card.h +++ b/include/linux/mmc/card.h @@ -43,6 +43,7 @@ struct mmc_csd { struct mmc_ext_csd { u8 rev; + u8 rel_wr_sec_c; u8 erase_group_def; u8 sec_feature_support; unsigned int sa_timeout; /* Units: 100ns */ diff --git a/include/linux/mmc/mmc.h b/include/linux/mmc/mmc.h index a5d765c..1e87020 100644 --- a/include/linux/mmc/mmc.h +++ b/include/linux/mmc/mmc.h @@ -260,6 +260,7 @@ struct _mmc_csd { #define EXT_CSD_CARD_TYPE 196 /* RO */ #define EXT_CSD_SEC_CNT 212 /* RO, 4 bytes */ #define EXT_CSD_S_A_TIMEOUT 217 /* RO */ +#define EXT_CSD_REL_WR_SEC_C 222 #define EXT_CSD_ERASE_TIMEOUT_MULT 223 /* RO */ #define EXT_CSD_HC_ERASE_GRP_SIZE 224 /* RO */ #define EXT_CSD_BOOT_SIZE_MULTI 226 ^ permalink raw reply related [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-11 22:27 ` Andrei Warkentin 0 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-11 22:27 UTC (permalink / raw) To: linux-arm-kernel On Wed, Feb 9, 2011 at 2:37 AM, Linus Walleij <linus.walleij@linaro.org> wrote: > [Quoting in verbatin so the orginal mail hits linux-mmc, this is very > interesting!] > > 2011/2/8 Andrei Warkentin <andreiw@motorola.com>: >> Hi, >> >> I'm not sure if this is the best place to bring this up, but Russel's >> name is on a fair share of drivers/mmc code, and there does seem to be >> quite a bit of MMC-related discussions. Excuse me in advance if this >> isn't the right forum :-). >> >> Certain MMC vendors (maybe even quite a bit of them) use a pretty >> rigid buffering scheme when it comes to handling writes. There is >> usually a buffer A for random accesses, and a buffer B for sequential >> accesses. For certain Toshiba parts, it looks like buffer A is 8KB >> wide, with buffer B being 4MB wide, and all accesses larger than 8KB >> effectively equating to 4MB accesses. Worse, consecutive small (8k) >> writes are treated as one large sequential access, once again ending >> up in buffer B, thus necessitating out-of-order writing to work around >> this. >> >> What this means is decreased life span for the parts, and it also >> means a performance impact on small writes, but the first item is much >> more crucial, especially for smaller parts. >> >> As I've mentioned, probably more vendors are affected. How about a >> generic MMC_BLOCK quirk that splits the requests (and optionally >> reorders) them? The thresholds would then be adjustable as >> module/kernel parameters based on manfid. I'm asking because I have a >> patch now, but its ugly and hardcoded against a specific manufacturer. > > There is a quirk API so that specific quirks can be flagged for certain > vendors and cards, e.g. some Toshibas in this case. e.g. grep the > kernel source for MMC_QUIRK_BLKSZ_FOR_BYTE_MODE. > > But as Russell says this probably needs to be signalled up to the > block layer to be handled properly. > > Why don't you post the code you have today as an RFC: patch, > I think many will be interested? > > Yours, > Linus Walleij > I think it's worthwhile to make make the upper block layers aware of MMC (and apparently other flash memory) limitations, but I think as a first step it could make sense (for me) to reformat the patch I am attaching into something that looks better. Don't take the attached patch too seriously :-). Thanks, A -------------- next part -------------- A non-text attachment was scrubbed... Name: toshiba_emmc_opt.patch Type: text/x-diff Size: 8737 bytes Desc: not available URL: <http://lists.infradead.org/pipermail/linux-arm-kernel/attachments/20110211/426789b7/attachment.bin> ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-11 22:27 ` Andrei Warkentin @ 2011-02-12 18:37 ` Arnd Bergmann -1 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-12 18:37 UTC (permalink / raw) To: linux-arm-kernel; +Cc: Andrei Warkentin, Linus Walleij, linux-mmc On Friday 11 February 2011 23:27:51 Andrei Warkentin wrote: > > diff --git a/drivers/mmc/card/block.c b/drivers/mmc/card/block.c > index 7054fd5..3b32329 100644 > --- a/drivers/mmc/card/block.c > +++ b/drivers/mmc/card/block.c > @@ -312,6 +316,157 @@ out: > return err ? 0 : 1; > } > > +/* > + * Workaround for Toshiba eMMC performance. If the request is less than two > + * flash pages in size, then we want to split the write into one or two > + * page-aligned writes to take advantage of faster buffering. Here we can > + * adjust the size of the MMC request and let the block layer request handler > + * deal with generating another MMC request. > + */ > +#define TOSHIBA_MANFID 0x11 > +#define TOSHIBA_PAGE_SIZE 16 /* sectors */ > +#define TOSHIBA_ADJUST_THRESHOLD 24 /* sectors */ > +static bool mmc_adjust_toshiba_write(struct mmc_card *card, > + struct mmc_request *mrq) > +{ > + if (mmc_card_mmc(card) && card->cid.manfid == TOSHIBA_MANFID && > + mrq->data->blocks <= TOSHIBA_ADJUST_THRESHOLD) { > + int sectors_in_page = TOSHIBA_PAGE_SIZE - > + (mrq->cmd->arg % TOSHIBA_PAGE_SIZE); > + if (mrq->data->blocks > sectors_in_page) { > + mrq->data->blocks = sectors_in_page; > + return true; > + } > + } > + > + return false; > +} This part might make sense in general, though it's hard to know the page size in the general case. For many SD cards, writing naturally aligned 64 KB blocks was the ideal case in my testing, but some need larger alignment or can deal well with smaller blocks. > +/* > + * This is another strange workaround to try to close the gap on Toshiba eMMC > + * performance when compared to other vendors. In order to take advantage > + * of certain optimizations and assumptions in those cards, we will look for > + * multiblock write transfers below a certain size and we do the following: > + * > + * - Break them up into seperate page-aligned (8k flash pages) transfers. > + * - Execute the transfers in reverse order. > + * - Use "reliable write" transfer mode. > + * > + * Neither the block I/O layer nor the scatterlist design seem to lend them- > + * selves well to executing a block request out of order. So instead we let > + * mmc_blk_issue_rq() setup the MMC request for the entire transfer and then > + * break it up and reorder it here. This also requires that we put the data > + * into a bounce buffer and send it as individual sg's. > + */ A lot of the SD cards I've seen will react very badly to reverse order, so that is definitely a dangerous thing to put into the code. Also, the "reliable write" seems like a really interesting thing to rely on for performance. I believe what the card is trying to do here is to optimize FAT32 directory updates. By using the small blocks in unpredictable order (anything but linear), you tell the card to treat this as part of a directory, so it probably gets written in a different way, but that might mean that it will try to turn the current erase block group into a special small write mode. I could imagine that this will cause problems on your eMMC once you write small blocks to more than erase block group, because that probably causes it to start garbage collection -- it makes sense for the cards to know that something is a directory, but it can only know about a small number of directories, so it will turn the segment into a regular one as soon something else becomes a directory. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-12 18:37 ` Arnd Bergmann 0 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-12 18:37 UTC (permalink / raw) To: linux-arm-kernel On Friday 11 February 2011 23:27:51 Andrei Warkentin wrote: > > diff --git a/drivers/mmc/card/block.c b/drivers/mmc/card/block.c > index 7054fd5..3b32329 100644 > --- a/drivers/mmc/card/block.c > +++ b/drivers/mmc/card/block.c > @@ -312,6 +316,157 @@ out: > return err ? 0 : 1; > } > > +/* > + * Workaround for Toshiba eMMC performance. If the request is less than two > + * flash pages in size, then we want to split the write into one or two > + * page-aligned writes to take advantage of faster buffering. Here we can > + * adjust the size of the MMC request and let the block layer request handler > + * deal with generating another MMC request. > + */ > +#define TOSHIBA_MANFID 0x11 > +#define TOSHIBA_PAGE_SIZE 16 /* sectors */ > +#define TOSHIBA_ADJUST_THRESHOLD 24 /* sectors */ > +static bool mmc_adjust_toshiba_write(struct mmc_card *card, > + struct mmc_request *mrq) > +{ > + if (mmc_card_mmc(card) && card->cid.manfid == TOSHIBA_MANFID && > + mrq->data->blocks <= TOSHIBA_ADJUST_THRESHOLD) { > + int sectors_in_page = TOSHIBA_PAGE_SIZE - > + (mrq->cmd->arg % TOSHIBA_PAGE_SIZE); > + if (mrq->data->blocks > sectors_in_page) { > + mrq->data->blocks = sectors_in_page; > + return true; > + } > + } > + > + return false; > +} This part might make sense in general, though it's hard to know the page size in the general case. For many SD cards, writing naturally aligned 64 KB blocks was the ideal case in my testing, but some need larger alignment or can deal well with smaller blocks. > +/* > + * This is another strange workaround to try to close the gap on Toshiba eMMC > + * performance when compared to other vendors. In order to take advantage > + * of certain optimizations and assumptions in those cards, we will look for > + * multiblock write transfers below a certain size and we do the following: > + * > + * - Break them up into seperate page-aligned (8k flash pages) transfers. > + * - Execute the transfers in reverse order. > + * - Use "reliable write" transfer mode. > + * > + * Neither the block I/O layer nor the scatterlist design seem to lend them- > + * selves well to executing a block request out of order. So instead we let > + * mmc_blk_issue_rq() setup the MMC request for the entire transfer and then > + * break it up and reorder it here. This also requires that we put the data > + * into a bounce buffer and send it as individual sg's. > + */ A lot of the SD cards I've seen will react very badly to reverse order, so that is definitely a dangerous thing to put into the code. Also, the "reliable write" seems like a really interesting thing to rely on for performance. I believe what the card is trying to do here is to optimize FAT32 directory updates. By using the small blocks in unpredictable order (anything but linear), you tell the card to treat this as part of a directory, so it probably gets written in a different way, but that might mean that it will try to turn the current erase block group into a special small write mode. I could imagine that this will cause problems on your eMMC once you write small blocks to more than erase block group, because that probably causes it to start garbage collection -- it makes sense for the cards to know that something is a directory, but it can only know about a small number of directories, so it will turn the segment into a regular one as soon something else becomes a directory. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-12 18:37 ` Arnd Bergmann @ 2011-02-13 0:10 ` Andrei Warkentin -1 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-13 0:10 UTC (permalink / raw) To: Arnd Bergmann; +Cc: linux-arm-kernel, Linus Walleij, linux-mmc On Sat, Feb 12, 2011 at 12:37 PM, Arnd Bergmann <arnd@arndb.de> wrote: > On Friday 11 February 2011 23:27:51 Andrei Warkentin wrote: >> >> diff --git a/drivers/mmc/card/block.c b/drivers/mmc/card/block.c >> index 7054fd5..3b32329 100644 >> --- a/drivers/mmc/card/block.c >> +++ b/drivers/mmc/card/block.c >> @@ -312,6 +316,157 @@ out: >> return err ? 0 : 1; >> } >> >> +/* >> + * Workaround for Toshiba eMMC performance. If the request is less than two >> + * flash pages in size, then we want to split the write into one or two >> + * page-aligned writes to take advantage of faster buffering. Here we can >> + * adjust the size of the MMC request and let the block layer request handler >> + * deal with generating another MMC request. >> + */ >> +#define TOSHIBA_MANFID 0x11 >> +#define TOSHIBA_PAGE_SIZE 16 /* sectors */ >> +#define TOSHIBA_ADJUST_THRESHOLD 24 /* sectors */ >> +static bool mmc_adjust_toshiba_write(struct mmc_card *card, >> + struct mmc_request *mrq) >> +{ >> + if (mmc_card_mmc(card) && card->cid.manfid == TOSHIBA_MANFID && >> + mrq->data->blocks <= TOSHIBA_ADJUST_THRESHOLD) { >> + int sectors_in_page = TOSHIBA_PAGE_SIZE - >> + (mrq->cmd->arg % TOSHIBA_PAGE_SIZE); >> + if (mrq->data->blocks > sectors_in_page) { >> + mrq->data->blocks = sectors_in_page; >> + return true; >> + } >> + } >> + >> + return false; >> +} > > This part might make sense in general, though it's hard to know the > page size in the general case. For many SD cards, writing naturally > aligned 64 KB blocks was the ideal case in my testing, but some need > larger alignment or can deal well with smaller blocks. > ...which is why I believe this should be a boot per-card parameter, and that it really only makes sense for embedded parts, where you know nothing else is going to be used as, say, mmcblk0. >> +/* >> + * This is another strange workaround to try to close the gap on Toshiba eMMC >> + * performance when compared to other vendors. In order to take advantage >> + * of certain optimizations and assumptions in those cards, we will look for >> + * multiblock write transfers below a certain size and we do the following: >> + * >> + * - Break them up into seperate page-aligned (8k flash pages) transfers. >> + * - Execute the transfers in reverse order. >> + * - Use "reliable write" transfer mode. >> + * >> + * Neither the block I/O layer nor the scatterlist design seem to lend them- >> + * selves well to executing a block request out of order. So instead we let >> + * mmc_blk_issue_rq() setup the MMC request for the entire transfer and then >> + * break it up and reorder it here. This also requires that we put the data >> + * into a bounce buffer and send it as individual sg's. >> + */ > > A lot of the SD cards I've seen will react very badly to reverse order, > so that is definitely a dangerous thing to put into the code. > > Also, the "reliable write" seems like a really interesting thing to > rely on for performance. I believe what the card is trying to do here > is to optimize FAT32 directory updates. By using the small blocks in > unpredictable order (anything but linear), you tell the card to treat > this as part of a directory, so it probably gets written in a different > way, but that might mean that it will try to turn the current erase > block group into a special small write mode. > > I could imagine that this will cause problems on your eMMC once you > write small blocks to more than erase block group, because that probably > causes it to start garbage collection -- it makes sense for the cards > to know that something is a directory, but it can only know about > a small number of directories, so it will turn the segment into a regular > one as soon something else becomes a directory. > It's difficult for me to argue one way or another. The code provided is implementing Toshiba's suggestions for mitigating excessive wear. Basically, as far as certain Android products are concerned, Motorola created some "typical usage" cases, and collected data logs. These logs were analyzed by Toshiba, which reported an approx x16 multiplication factor for writes. Analysis of data written showed that there were many random accesses with 16KB or 32KB, meaning they go into buffer B. According to T, that means extra GC and PE cycle. I'm guessing per write. So T suggested for random data to better go into buffer A. How? Two suggestions. 1) Split smaller accesses into 8KB and write with reliable write. 2) Split smaller accesses into 8KB and write in reverse. The patch does both and I am verifying if that is really necessary. I need to go see the mmc spec and what it says about reliable write. Basically, whatever behavior you choose is going to be wrong some set of cards. Which is why tuning it probably only makes sense for eMMC parts, and should be a set of runtime/compile-time quirks. What do you think? ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-13 0:10 ` Andrei Warkentin 0 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-13 0:10 UTC (permalink / raw) To: linux-arm-kernel On Sat, Feb 12, 2011 at 12:37 PM, Arnd Bergmann <arnd@arndb.de> wrote: > On Friday 11 February 2011 23:27:51 Andrei Warkentin wrote: >> >> diff --git a/drivers/mmc/card/block.c b/drivers/mmc/card/block.c >> index 7054fd5..3b32329 100644 >> --- a/drivers/mmc/card/block.c >> +++ b/drivers/mmc/card/block.c >> @@ -312,6 +316,157 @@ out: >> ? ? ? return err ? 0 : 1; >> ?} >> >> +/* >> + * Workaround for Toshiba eMMC performance. ?If the request is less than two >> + * flash pages in size, then we want to split the write into one or two >> + * page-aligned writes to take advantage of faster buffering. ?Here we can >> + * adjust the size of the MMC request and let the block layer request handler >> + * deal with generating another MMC request. >> + */ >> +#define TOSHIBA_MANFID 0x11 >> +#define TOSHIBA_PAGE_SIZE 16 ? ? ? ? /* sectors */ >> +#define TOSHIBA_ADJUST_THRESHOLD 24 ?/* sectors */ >> +static bool mmc_adjust_toshiba_write(struct mmc_card *card, >> + ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? struct mmc_request *mrq) >> +{ >> + ? ? if (mmc_card_mmc(card) && card->cid.manfid == TOSHIBA_MANFID && >> + ? ? ? ? mrq->data->blocks <= TOSHIBA_ADJUST_THRESHOLD) { >> + ? ? ? ? ? ? int sectors_in_page = TOSHIBA_PAGE_SIZE - >> + ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? (mrq->cmd->arg % TOSHIBA_PAGE_SIZE); >> + ? ? ? ? ? ? if (mrq->data->blocks > sectors_in_page) { >> + ? ? ? ? ? ? ? ? ? ? mrq->data->blocks = sectors_in_page; >> + ? ? ? ? ? ? ? ? ? ? return true; >> + ? ? ? ? ? ? } >> + ? ? } >> + >> + ? ? return false; >> +} > > This part might make sense in general, though it's hard to know the > page size in the general case. For many SD cards, writing naturally > aligned 64 KB blocks was the ideal case in my testing, but some need > larger alignment or can deal well with smaller blocks. > ...which is why I believe this should be a boot per-card parameter, and that it really only makes sense for embedded parts, where you know nothing else is going to be used as, say, mmcblk0. >> +/* >> + * This is another strange workaround to try to close the gap on Toshiba eMMC >> + * performance when compared to other vendors. ?In order to take advantage >> + * of certain optimizations and assumptions in those cards, we will look for >> + * multiblock write transfers below a certain size and we do the following: >> + * >> + * - Break them up into seperate page-aligned (8k flash pages) transfers. >> + * - Execute the transfers in reverse order. >> + * - Use "reliable write" transfer mode. >> + * >> + * Neither the block I/O layer nor the scatterlist design seem to lend them- >> + * selves well to executing a block request out of order. ?So instead we let >> + * mmc_blk_issue_rq() setup the MMC request for the entire transfer and then >> + * break it up and reorder it here. ?This also requires that we put the data >> + * into a bounce buffer and send it as individual sg's. >> + */ > > A lot of the SD cards I've seen will react very badly to reverse order, > so that is definitely a dangerous thing to put into the code. > > Also, the "reliable write" seems like a really interesting thing to > rely on for performance. I believe what the card is trying to do here > is to optimize FAT32 directory updates. By using the small blocks in > unpredictable order (anything but linear), you tell the card to treat > this as part of a directory, so it probably gets written in a different > way, but that might mean that it will try to turn the current erase > block group into a special small write mode. > > I could imagine that this will cause problems on your eMMC once you > write small blocks to more than erase block group, because that probably > causes it to start garbage collection -- it makes sense for the cards > to know that something is a directory, but it can only know about > a small number of directories, so it will turn the segment into a regular > one as soon something else becomes a directory. > It's difficult for me to argue one way or another. The code provided is implementing Toshiba's suggestions for mitigating excessive wear. Basically, as far as certain Android products are concerned, Motorola created some "typical usage" cases, and collected data logs. These logs were analyzed by Toshiba, which reported an approx x16 multiplication factor for writes. Analysis of data written showed that there were many random accesses with 16KB or 32KB, meaning they go into buffer B. According to T, that means extra GC and PE cycle. I'm guessing per write. So T suggested for random data to better go into buffer A. How? Two suggestions. 1) Split smaller accesses into 8KB and write with reliable write. 2) Split smaller accesses into 8KB and write in reverse. The patch does both and I am verifying if that is really necessary. I need to go see the mmc spec and what it says about reliable write. Basically, whatever behavior you choose is going to be wrong some set of cards. Which is why tuning it probably only makes sense for eMMC parts, and should be a set of runtime/compile-time quirks. What do you think? ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-13 0:10 ` Andrei Warkentin @ 2011-02-13 17:39 ` Arnd Bergmann -1 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-13 17:39 UTC (permalink / raw) To: Andrei Warkentin; +Cc: linux-arm-kernel, Linus Walleij, linux-mmc On Sunday 13 February 2011 01:10:09 Andrei Warkentin wrote: > On Sat, Feb 12, 2011 at 12:37 PM, Arnd Bergmann <arnd@arndb.de> wrote: > > > This part might make sense in general, though it's hard to know the > > page size in the general case. For many SD cards, writing naturally > > aligned 64 KB blocks was the ideal case in my testing, but some need > > larger alignment or can deal well with smaller blocks. > > > > ...which is why I believe this should be a boot per-card parameter, > and that it really only makes sense for embedded parts, where you know > nothing else is going to be used as, say, mmcblk0. I don't think it needs to be boot-time, it can easily be run-time tuneable using sysfs, where you can configure it using an init script or some other logic from user space. > > I could imagine that this will cause problems on your eMMC once you > > write small blocks to more than erase block group, because that probably > > causes it to start garbage collection -- it makes sense for the cards > > to know that something is a directory, but it can only know about > > a small number of directories, so it will turn the segment into a regular > > one as soon something else becomes a directory. > > > > It's difficult for me to argue one way or another. The code provided > is implementing Toshiba's suggestions for mitigating excessive wear. > Basically, as far as certain Android products are concerned, Motorola > created some "typical usage" cases, and collected data logs. These > logs were analyzed by Toshiba, which reported an approx x16 > multiplication factor for writes. Yes, I've seen similar numbers in my measurements. My experience with the Kingston/Toshiba cards is that they combine two unfortunate problems: * Only one 4 MB AU can be open, writing to a different AU waits for garbage collection on the old one. Other cards typically have five buffers for open AUs, which makes them much easier to work with. * Only linear access within one AU is fast. Writing to a block with a lower address in the same AU causes garbage collection of the AU. > Analysis of data written showed that there were many random accesses > with 16KB or 32KB, meaning they go into buffer B. I have started a remapping layer that should be able to deal with this independent of the card, see https://wiki.linaro.org/WorkingGroups/KernelConsolidation/Projects/FlashDeviceMapper It's still in the early stages, but maybe something like that will help you as well. The real solution would be to have a file system that knows what accesses are fast and reorders file data accordingly. Right now, the only thing that is normally fast is FAT32 using 32KB clusters, and only if the file system is aligned properly. > According to T, that > means extra GC and PE cycle. I'm guessing per write. Yes. What is "PE" here? > So T suggested for random data to better go into buffer A. How? Two suggestions. > 1) Split smaller accesses into 8KB and write with reliable write. > 2) Split smaller accesses into 8KB and write in reverse. > > The patch does both and I am verifying if that is really necessary. I > need to go see the mmc spec and what it says about reliable write. I should add this to my test tool once I can reproduce it. If it turns out that other media do the same, we can also trigger the same behavior for those. > Basically, whatever behavior you choose is going to be wrong some set > of cards. Which is why tuning it probably only makes sense for eMMC > parts, and should be a set of runtime/compile-time quirks. What do you > think? Your explanation makes sense, but I'd definitely favor a run-time solution over compile-time or boot-time, because it would be much more flexible. We should also be able to find some optimizations that are universally good so we can always use them. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-13 17:39 ` Arnd Bergmann 0 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-13 17:39 UTC (permalink / raw) To: linux-arm-kernel On Sunday 13 February 2011 01:10:09 Andrei Warkentin wrote: > On Sat, Feb 12, 2011 at 12:37 PM, Arnd Bergmann <arnd@arndb.de> wrote: > > > This part might make sense in general, though it's hard to know the > > page size in the general case. For many SD cards, writing naturally > > aligned 64 KB blocks was the ideal case in my testing, but some need > > larger alignment or can deal well with smaller blocks. > > > > ...which is why I believe this should be a boot per-card parameter, > and that it really only makes sense for embedded parts, where you know > nothing else is going to be used as, say, mmcblk0. I don't think it needs to be boot-time, it can easily be run-time tuneable using sysfs, where you can configure it using an init script or some other logic from user space. > > I could imagine that this will cause problems on your eMMC once you > > write small blocks to more than erase block group, because that probably > > causes it to start garbage collection -- it makes sense for the cards > > to know that something is a directory, but it can only know about > > a small number of directories, so it will turn the segment into a regular > > one as soon something else becomes a directory. > > > > It's difficult for me to argue one way or another. The code provided > is implementing Toshiba's suggestions for mitigating excessive wear. > Basically, as far as certain Android products are concerned, Motorola > created some "typical usage" cases, and collected data logs. These > logs were analyzed by Toshiba, which reported an approx x16 > multiplication factor for writes. Yes, I've seen similar numbers in my measurements. My experience with the Kingston/Toshiba cards is that they combine two unfortunate problems: * Only one 4 MB AU can be open, writing to a different AU waits for garbage collection on the old one. Other cards typically have five buffers for open AUs, which makes them much easier to work with. * Only linear access within one AU is fast. Writing to a block with a lower address in the same AU causes garbage collection of the AU. > Analysis of data written showed that there were many random accesses > with 16KB or 32KB, meaning they go into buffer B. I have started a remapping layer that should be able to deal with this independent of the card, see https://wiki.linaro.org/WorkingGroups/KernelConsolidation/Projects/FlashDeviceMapper It's still in the early stages, but maybe something like that will help you as well. The real solution would be to have a file system that knows what accesses are fast and reorders file data accordingly. Right now, the only thing that is normally fast is FAT32 using 32KB clusters, and only if the file system is aligned properly. > According to T, that > means extra GC and PE cycle. I'm guessing per write. Yes. What is "PE" here? > So T suggested for random data to better go into buffer A. How? Two suggestions. > 1) Split smaller accesses into 8KB and write with reliable write. > 2) Split smaller accesses into 8KB and write in reverse. > > The patch does both and I am verifying if that is really necessary. I > need to go see the mmc spec and what it says about reliable write. I should add this to my test tool once I can reproduce it. If it turns out that other media do the same, we can also trigger the same behavior for those. > Basically, whatever behavior you choose is going to be wrong some set > of cards. Which is why tuning it probably only makes sense for eMMC > parts, and should be a set of runtime/compile-time quirks. What do you > think? Your explanation makes sense, but I'd definitely favor a run-time solution over compile-time or boot-time, because it would be much more flexible. We should also be able to find some optimizations that are universally good so we can always use them. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-13 17:39 ` Arnd Bergmann @ 2011-02-14 19:29 ` Andrei Warkentin -1 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-14 19:29 UTC (permalink / raw) To: Arnd Bergmann; +Cc: linux-arm-kernel, Linus Walleij, linux-mmc On Sun, Feb 13, 2011 at 11:39 AM, Arnd Bergmann <arnd@arndb.de> wrote: > I don't think it needs to be boot-time, it can easily be run-time > tuneable using sysfs, where you can configure it using an init script > or some other logic from user space. True, definitely expose the controls through sysfs. > > Yes. > > What is "PE" here? > Ah sorry, I had to look that one up myself, I thought it was the local jargon associated with the problem space :-). Program/Erase cycle. >> So T suggested for random data to better go into buffer A. How? Two suggestions. >> 1) Split smaller accesses into 8KB and write with reliable write. >> 2) Split smaller accesses into 8KB and write in reverse. >> >> The patch does both and I am verifying if that is really necessary. I >> need to go see the mmc spec and what it says about reliable write. > > I should add this to my test tool once I can reproduce it. If it turns > out that other media do the same, we can also trigger the same behavior > for those. > As I mentioned, I am checking with T right now on whether we can use suggestion (1) or suggestion (2) or if they need to be combined. The documentation we got was open to interpretation and the patch created from that did both. You mentioned that writing in reverse is not a good idea. Could you elaborate why? I would guess because you're always causing a write into a different AU (on these Toshiba cards), causing extra GC on every write? >> Basically, whatever behavior you choose is going to be wrong some set >> of cards. Which is why tuning it probably only makes sense for eMMC >> parts, and should be a set of runtime/compile-time quirks. What do you >> think? > > Your explanation makes sense, but I'd definitely favor a run-time solution > over compile-time or boot-time, because it would be much more flexible. > We should also be able to find some optimizations that are universally > good so we can always use them. > Then that's the angle I will pursue. It is the most flexible and then you don't have to pollute the block driver with little workarounds for soon-to-be-obsolete hardware. Hopefully I'll have something for re-review soon. Thanks Again! ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-14 19:29 ` Andrei Warkentin 0 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-14 19:29 UTC (permalink / raw) To: linux-arm-kernel On Sun, Feb 13, 2011 at 11:39 AM, Arnd Bergmann <arnd@arndb.de> wrote: > I don't think it needs to be boot-time, it can easily be run-time > tuneable using sysfs, where you can configure it using an init script > or some other logic from user space. True, definitely expose the controls through sysfs. > > Yes. > > What is "PE" here? > Ah sorry, I had to look that one up myself, I thought it was the local jargon associated with the problem space :-). Program/Erase cycle. >> So T suggested for random data to better go into buffer A. How? Two suggestions. >> 1) Split smaller accesses into 8KB and write with reliable write. >> 2) Split smaller accesses into 8KB and write in reverse. >> >> The patch does both and I am verifying if that is really necessary. I >> need to go see the mmc spec and what it says about reliable write. > > I should add this to my test tool once I can reproduce it. If it turns > out that other media do the same, we can also trigger the same behavior > for those. > As I mentioned, I am checking with T right now on whether we can use suggestion (1) or suggestion (2) or if they need to be combined. The documentation we got was open to interpretation and the patch created from that did both. You mentioned that writing in reverse is not a good idea. Could you elaborate why? I would guess because you're always causing a write into a different AU (on these Toshiba cards), causing extra GC on every write? >> Basically, whatever behavior you choose is going to be wrong some set >> of cards. Which is why tuning it probably only makes sense for eMMC >> parts, and should be a set of runtime/compile-time quirks. What do you >> think? > > Your explanation makes sense, but I'd definitely favor a run-time solution > over compile-time or boot-time, because it would be much more flexible. > We should also be able to find some optimizations that are universally > good so we can always use them. > Then that's the angle I will pursue. It is the most flexible and then you don't have to pollute the block driver with little workarounds for soon-to-be-obsolete hardware. Hopefully I'll have something for re-review soon. Thanks Again! ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-14 19:29 ` Andrei Warkentin @ 2011-02-14 20:22 ` Arnd Bergmann -1 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-14 20:22 UTC (permalink / raw) To: linux-arm-kernel; +Cc: Andrei Warkentin, Linus Walleij, linux-mmc On Monday 14 February 2011 20:29:59 Andrei Warkentin wrote: > On Sun, Feb 13, 2011 at 11:39 AM, Arnd Bergmann <arnd@arndb.de> wrote: > > Ah sorry, I had to look that one up myself, I thought it was the local > jargon associated with the problem space :-). Program/Erase cycle. Ok, makes sense. > >> So T suggested for random data to better go into buffer A. How? Two suggestions. > >> 1) Split smaller accesses into 8KB and write with reliable write. > >> 2) Split smaller accesses into 8KB and write in reverse. > >> > >> The patch does both and I am verifying if that is really necessary. I > >> need to go see the mmc spec and what it says about reliable write. > > > > I should add this to my test tool once I can reproduce it. If it turns > > out that other media do the same, we can also trigger the same behavior > > for those. > > > > As I mentioned, I am checking with T right now on whether we can use > suggestion (1) or > suggestion (2) or if they need to be combined. The documentation we > got was open to interpretation and the patch created from that did > both. > You mentioned that writing in reverse is not a good idea. Could you > elaborate why? I would guess because you're always causing a write > into a different AU (on these Toshiba cards), causing extra GC on > every write? Probably both the reliable write and writing small blocks in reverse order will cause any card to do something that is different from what it does on normal 64kb (or larger) aligned accesses. There are multiple ways how this could be implemented: 1. Have one exception cache for all "special" blocks. This would normally be for FAT32 subdirectory updates, which always write to the same few blocks. This means you can do small writes efficiently anywhere on the card, but only up to a (small) fixed number of block addresses. If you overflow the table, the card still needs to go through an extra PE for each new entry you write, in order to free up an entry. 2. Have a small number of AUs that can be in a special mode with efficient small writes but inefficient large writes. This means that when you alternate between small and large writes in the same AU, it has to go through a PE on every switch. Similarly, if you do small writes to more than the maximum number of AUs that can be held in this mode, you get the same effect. This number can be as small as one, because that is what FAT32 requires. In both cases, you don't actually have a solution for the problem, you just make it less likely for specific workloads. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-14 20:22 ` Arnd Bergmann 0 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-14 20:22 UTC (permalink / raw) To: linux-arm-kernel On Monday 14 February 2011 20:29:59 Andrei Warkentin wrote: > On Sun, Feb 13, 2011 at 11:39 AM, Arnd Bergmann <arnd@arndb.de> wrote: > > Ah sorry, I had to look that one up myself, I thought it was the local > jargon associated with the problem space :-). Program/Erase cycle. Ok, makes sense. > >> So T suggested for random data to better go into buffer A. How? Two suggestions. > >> 1) Split smaller accesses into 8KB and write with reliable write. > >> 2) Split smaller accesses into 8KB and write in reverse. > >> > >> The patch does both and I am verifying if that is really necessary. I > >> need to go see the mmc spec and what it says about reliable write. > > > > I should add this to my test tool once I can reproduce it. If it turns > > out that other media do the same, we can also trigger the same behavior > > for those. > > > > As I mentioned, I am checking with T right now on whether we can use > suggestion (1) or > suggestion (2) or if they need to be combined. The documentation we > got was open to interpretation and the patch created from that did > both. > You mentioned that writing in reverse is not a good idea. Could you > elaborate why? I would guess because you're always causing a write > into a different AU (on these Toshiba cards), causing extra GC on > every write? Probably both the reliable write and writing small blocks in reverse order will cause any card to do something that is different from what it does on normal 64kb (or larger) aligned accesses. There are multiple ways how this could be implemented: 1. Have one exception cache for all "special" blocks. This would normally be for FAT32 subdirectory updates, which always write to the same few blocks. This means you can do small writes efficiently anywhere on the card, but only up to a (small) fixed number of block addresses. If you overflow the table, the card still needs to go through an extra PE for each new entry you write, in order to free up an entry. 2. Have a small number of AUs that can be in a special mode with efficient small writes but inefficient large writes. This means that when you alternate between small and large writes in the same AU, it has to go through a PE on every switch. Similarly, if you do small writes to more than the maximum number of AUs that can be held in this mode, you get the same effect. This number can be as small as one, because that is what FAT32 requires. In both cases, you don't actually have a solution for the problem, you just make it less likely for specific workloads. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-14 20:22 ` Arnd Bergmann @ 2011-02-14 22:25 ` Andrei Warkentin -1 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-14 22:25 UTC (permalink / raw) To: Arnd Bergmann; +Cc: linux-arm-kernel, Linus Walleij, linux-mmc On Mon, Feb 14, 2011 at 2:22 PM, Arnd Bergmann <arnd@arndb.de> wrote: >> >> As I mentioned, I am checking with T right now on whether we can use >> suggestion (1) or >> suggestion (2) or if they need to be combined. The documentation we >> got was open to interpretation and the patch created from that did >> both. >> You mentioned that writing in reverse is not a good idea. Could you >> elaborate why? I would guess because you're always causing a write >> into a different AU (on these Toshiba cards), causing extra GC on >> every write? > > Probably both the reliable write and writing small blocks in reverse > order will cause any card to do something that is different from > what it does on normal 64kb (or larger) aligned accesses. > > There are multiple ways how this could be implemented: > > 1. Have one exception cache for all "special" blocks. This would normally > be for FAT32 subdirectory updates, which always write to the same > few blocks. This means you can do small writes efficiently anywhere > on the card, but only up to a (small) fixed number of block addresses. > If you overflow the table, the card still needs to go through an > extra PE for each new entry you write, in order to free up an entry. > > 2. Have a small number of AUs that can be in a special mode with efficient > small writes but inefficient large writes. This means that when you > alternate between small and large writes in the same AU, it has to go > through a PE on every switch. Similarly, if you do small writes to > more than the maximum number of AUs that can be held in this mode, you > get the same effect. This number can be as small as one, because that > is what FAT32 requires. > > In both cases, you don't actually have a solution for the problem, you just > make it less likely for specific workloads. Aha, ok. By the way, I did find out that either suggestion works. So I'll pull out the reversing portion of the patch. No need to overcomplicate :). ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-14 22:25 ` Andrei Warkentin 0 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-14 22:25 UTC (permalink / raw) To: linux-arm-kernel On Mon, Feb 14, 2011 at 2:22 PM, Arnd Bergmann <arnd@arndb.de> wrote: >> >> As I mentioned, I am checking with T right now on whether we can use >> suggestion (1) or >> suggestion (2) or if they need to be combined. The documentation we >> got was open to interpretation and the patch created from that did >> both. >> You mentioned that writing in reverse is not a good idea. Could you >> elaborate why? I would guess because you're always causing a write >> into a different AU (on these Toshiba cards), causing extra GC on >> every write? > > Probably both the reliable write and writing small blocks in reverse > order will cause any card to do something that is different from > what it does on normal 64kb (or larger) aligned accesses. > > There are multiple ways how this could be implemented: > > 1. Have one exception cache for all "special" blocks. This would normally > ? be for FAT32 subdirectory updates, which always write to the same > ? few blocks. This means you can do small writes efficiently anywhere > ? on the card, but only up to a (small) fixed number of block addresses. > ? If you overflow the table, the card still needs to go through an > ? extra PE for each new entry you write, in order to free up an entry. > > 2. Have a small number of AUs that can be in a special mode with efficient > ? small writes but inefficient large writes. This means that when you > ? alternate between small and large writes in the same AU, it has to go > ? through a PE on every switch. Similarly, if you do small writes to > ? more than the maximum number of AUs that can be held in this mode, you > ? get the same effect. This number can be as small as one, because that > ? is what FAT32 requires. > > In both cases, you don't actually have a solution for the problem, you just > make it less likely for specific workloads. Aha, ok. By the way, I did find out that either suggestion works. So I'll pull out the reversing portion of the patch. No need to overcomplicate :). ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-14 22:25 ` Andrei Warkentin @ 2011-02-15 17:16 ` Arnd Bergmann -1 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-15 17:16 UTC (permalink / raw) To: Andrei Warkentin; +Cc: linux-arm-kernel, Linus Walleij, linux-mmc On Monday 14 February 2011, Andrei Warkentin wrote: > > There are multiple ways how this could be implemented: > > > > 1. Have one exception cache for all "special" blocks. This would normally > > be for FAT32 subdirectory updates, which always write to the same > > few blocks. This means you can do small writes efficiently anywhere > > on the card, but only up to a (small) fixed number of block addresses. > > If you overflow the table, the card still needs to go through an > > extra PE for each new entry you write, in order to free up an entry. > > > > 2. Have a small number of AUs that can be in a special mode with efficient > > small writes but inefficient large writes. This means that when you > > alternate between small and large writes in the same AU, it has to go > > through a PE on every switch. Similarly, if you do small writes to > > more than the maximum number of AUs that can be held in this mode, you > > get the same effect. This number can be as small as one, because that > > is what FAT32 requires. > > > > In both cases, you don't actually have a solution for the problem, you just > > make it less likely for specific workloads. > > Aha, ok. By the way, I did find out that either suggestion works. So > I'll pull out the reversing portion of the patch. No need to > overcomplicate :). BTW, what file system are you using? I could imagine that each of ext4, btrfs and nilfs2 give you very different results here. It could be that if your patch is optimizing for one file system, it is actually pessimising for another one. What benchmark do you use to find out of your optimizations actually help you? Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-15 17:16 ` Arnd Bergmann 0 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-15 17:16 UTC (permalink / raw) To: linux-arm-kernel On Monday 14 February 2011, Andrei Warkentin wrote: > > There are multiple ways how this could be implemented: > > > > 1. Have one exception cache for all "special" blocks. This would normally > > be for FAT32 subdirectory updates, which always write to the same > > few blocks. This means you can do small writes efficiently anywhere > > on the card, but only up to a (small) fixed number of block addresses. > > If you overflow the table, the card still needs to go through an > > extra PE for each new entry you write, in order to free up an entry. > > > > 2. Have a small number of AUs that can be in a special mode with efficient > > small writes but inefficient large writes. This means that when you > > alternate between small and large writes in the same AU, it has to go > > through a PE on every switch. Similarly, if you do small writes to > > more than the maximum number of AUs that can be held in this mode, you > > get the same effect. This number can be as small as one, because that > > is what FAT32 requires. > > > > In both cases, you don't actually have a solution for the problem, you just > > make it less likely for specific workloads. > > Aha, ok. By the way, I did find out that either suggestion works. So > I'll pull out the reversing portion of the patch. No need to > overcomplicate :). BTW, what file system are you using? I could imagine that each of ext4, btrfs and nilfs2 give you very different results here. It could be that if your patch is optimizing for one file system, it is actually pessimising for another one. What benchmark do you use to find out of your optimizations actually help you? Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-15 17:16 ` Arnd Bergmann @ 2011-02-17 2:08 ` Andrei Warkentin -1 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-17 2:08 UTC (permalink / raw) To: Arnd Bergmann; +Cc: linux-arm-kernel, Linus Walleij, linux-mmc On Tue, Feb 15, 2011 at 11:16 AM, Arnd Bergmann <arnd@arndb.de> wrote: > On Monday 14 February 2011, Andrei Warkentin wrote: >> > There are multiple ways how this could be implemented: >> > >> > 1. Have one exception cache for all "special" blocks. This would normally >> > be for FAT32 subdirectory updates, which always write to the same >> > few blocks. This means you can do small writes efficiently anywhere >> > on the card, but only up to a (small) fixed number of block addresses. >> > If you overflow the table, the card still needs to go through an >> > extra PE for each new entry you write, in order to free up an entry. >> > >> > 2. Have a small number of AUs that can be in a special mode with efficient >> > small writes but inefficient large writes. This means that when you >> > alternate between small and large writes in the same AU, it has to go >> > through a PE on every switch. Similarly, if you do small writes to >> > more than the maximum number of AUs that can be held in this mode, you >> > get the same effect. This number can be as small as one, because that >> > is what FAT32 requires. >> > >> > In both cases, you don't actually have a solution for the problem, you just >> > make it less likely for specific workloads. >> >> Aha, ok. By the way, I did find out that either suggestion works. So >> I'll pull out the reversing portion of the patch. No need to >> overcomplicate :). > > BTW, what file system are you using? I could imagine that each of ext4, btrfs > and nilfs2 give you very different results here. It could be that if your > patch is optimizing for one file system, it is actually pessimising for > another one. > Ext4. I've actually been rewriting the patch a lot and it's taking time because there are a lot of things that are wrong in it (so I feel kinda bad for forwarding it to this list in the first place...). I've already mentioned that there is no need to reorder, so that's going away and it simplifies everything greatly. I agree, which is why all of this is controlled now through sysfs, and there are no more hard-coded checks for manfid, mmc versus sd or any other magic. There is a page_size_secs attribute, through which you can notify of the page size for the device. The workaround for small writes crossing the page boundary (and winding up in Buffer B, instead of A) is turned on by setting split_tlow and split_thigh, which provided a threshold range in sectors over which the the writes will be split/aligned. The second workaround for splitting larger requests and writing them with reliable write (to avoid getting coalesced and winding up in Buffer B again) is controlled through split_relw_tlow and split_relw_thigh. Do you think there is a better way? Or is this good enough? So, as I mentioned before, T had done some tests given data provided by M, and then T verified that this fix was good. I need to do my own tests on the patch after I rewrite it. Is iozone the best tool I can use? So far I have a MMC logging facility through connector that I use to collect stats (useful for seeing how fs traffic translates to actual mmc commands...once I clean it up I'll push here for RFC). What about the tool you're writing? Any way I can use it? ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-17 2:08 ` Andrei Warkentin 0 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-17 2:08 UTC (permalink / raw) To: linux-arm-kernel On Tue, Feb 15, 2011 at 11:16 AM, Arnd Bergmann <arnd@arndb.de> wrote: > On Monday 14 February 2011, Andrei Warkentin wrote: >> > There are multiple ways how this could be implemented: >> > >> > 1. Have one exception cache for all "special" blocks. This would normally >> > ? be for FAT32 subdirectory updates, which always write to the same >> > ? few blocks. This means you can do small writes efficiently anywhere >> > ? on the card, but only up to a (small) fixed number of block addresses. >> > ? If you overflow the table, the card still needs to go through an >> > ? extra PE for each new entry you write, in order to free up an entry. >> > >> > 2. Have a small number of AUs that can be in a special mode with efficient >> > ? small writes but inefficient large writes. This means that when you >> > ? alternate between small and large writes in the same AU, it has to go >> > ? through a PE on every switch. Similarly, if you do small writes to >> > ? more than the maximum number of AUs that can be held in this mode, you >> > ? get the same effect. This number can be as small as one, because that >> > ? is what FAT32 requires. >> > >> > In both cases, you don't actually have a solution for the problem, you just >> > make it less likely for specific workloads. >> >> Aha, ok. By the way, I did find out that either suggestion works. So >> I'll pull out the reversing portion of the patch. No need to >> overcomplicate :). > > BTW, what file system are you using? I could imagine that each of ext4, btrfs > and nilfs2 give you very different results here. It could be that if your > patch is optimizing for one file system, it is actually pessimising for > another one. > Ext4. I've actually been rewriting the patch a lot and it's taking time because there are a lot of things that are wrong in it (so I feel kinda bad for forwarding it to this list in the first place...). I've already mentioned that there is no need to reorder, so that's going away and it simplifies everything greatly. I agree, which is why all of this is controlled now through sysfs, and there are no more hard-coded checks for manfid, mmc versus sd or any other magic. There is a page_size_secs attribute, through which you can notify of the page size for the device. The workaround for small writes crossing the page boundary (and winding up in Buffer B, instead of A) is turned on by setting split_tlow and split_thigh, which provided a threshold range in sectors over which the the writes will be split/aligned. The second workaround for splitting larger requests and writing them with reliable write (to avoid getting coalesced and winding up in Buffer B again) is controlled through split_relw_tlow and split_relw_thigh. Do you think there is a better way? Or is this good enough? So, as I mentioned before, T had done some tests given data provided by M, and then T verified that this fix was good. I need to do my own tests on the patch after I rewrite it. Is iozone the best tool I can use? So far I have a MMC logging facility through connector that I use to collect stats (useful for seeing how fs traffic translates to actual mmc commands...once I clean it up I'll push here for RFC). What about the tool you're writing? Any way I can use it? ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-17 2:08 ` Andrei Warkentin @ 2011-02-17 15:47 ` Arnd Bergmann -1 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-17 15:47 UTC (permalink / raw) To: Andrei Warkentin; +Cc: linux-arm-kernel, Linus Walleij, linux-mmc On Thursday 17 February 2011, Andrei Warkentin wrote: > Ext4. Ok, I see. I haven't really done this kind of tests before, but my feeling is that ext3/ext4 may be much worse than the alternatives at the moment. It would certainly be worthwhile to do tests using nilfs2 and btrfs, whose default behaviour matches the requirements of your eMMC flash much better, and see how they perform with and without your patch. > I agree, which is why all of this is controlled now through sysfs, and > there are no more hard-coded checks for manfid, mmc versus sd or any > other magic. There is a page_size_secs attribute, through which you > can notify of the page size for the device. How about making that just page_size in bytes? sectors don't always mean 512 bytes, so this would be both shorter and less anbiguous. > The workaround for small > writes crossing the page boundary (and winding up in Buffer B, instead > of A) is turned on by setting split_tlow and split_thigh, which > provided a threshold range in sectors over which the the writes will > be split/aligned. The second workaround for splitting larger requests > and writing them with reliable write (to avoid getting coalesced and > winding up in Buffer B again) is controlled through split_relw_tlow > and split_relw_thigh. Do you think there is a better way? Or is this > good enough? I think I'd try to reduce the number of sysfs files needed for this. What are the values you would typically set here? My feeling is that separating unaligned page writes from full pages or multiples of pages could always be benefitial for all cards, or at least harmless, but that will require more measurements. Whether to do the reliable write or not could be a simple flag if the numbers are the same. > So, as I mentioned before, T had done some tests given data provided > by M, and then T verified that this fix was good. I need to do my own > tests on the patch after I rewrite it. Is iozone the best tool I can > use? So far I have a MMC logging facility through connector that I use > to collect stats (useful for seeing how fs traffic translates to > actual mmc commands...once I clean it up I'll push here for RFC). What > about the tool you're writing? Any way I can use it? It's now available in a an early almost-usable version at git://git.linaro.org/people/arnd/flashbench.git I don't have a test for the second buffer yet, but it would be good to know some of the other characteristics of your eMMC drive. Please try some of these commands: flashbench -a /dev/mmcblk0 --blocksize=1024 flashbench --open-au --open-au-nr=1 /dev/mmcblk0 --blocksize=512 flashbench --open-au --open-au-nr=1 /dev/mmcblk0 --blocksize=512 --random flashbench --open-au --open-au-nr=2 /dev/mmcblk0 --blocksize=512 flashbench --open-au --open-au-nr=2 /dev/mmcblk0 --blocksize=512 --random flashbench --open-au --open-au-nr=3 /dev/mmcblk0 --blocksize=512 flashbench --open-au --open-au-nr=3 /dev/mmcblk0 --blocksize=512 --random Note that the --open-au test will overwrite your data. You can do it on a partition you don't use, but it needs to be aligned to 4 MB. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-17 15:47 ` Arnd Bergmann 0 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-17 15:47 UTC (permalink / raw) To: linux-arm-kernel On Thursday 17 February 2011, Andrei Warkentin wrote: > Ext4. Ok, I see. I haven't really done this kind of tests before, but my feeling is that ext3/ext4 may be much worse than the alternatives at the moment. It would certainly be worthwhile to do tests using nilfs2 and btrfs, whose default behaviour matches the requirements of your eMMC flash much better, and see how they perform with and without your patch. > I agree, which is why all of this is controlled now through sysfs, and > there are no more hard-coded checks for manfid, mmc versus sd or any > other magic. There is a page_size_secs attribute, through which you > can notify of the page size for the device. How about making that just page_size in bytes? sectors don't always mean 512 bytes, so this would be both shorter and less anbiguous. > The workaround for small > writes crossing the page boundary (and winding up in Buffer B, instead > of A) is turned on by setting split_tlow and split_thigh, which > provided a threshold range in sectors over which the the writes will > be split/aligned. The second workaround for splitting larger requests > and writing them with reliable write (to avoid getting coalesced and > winding up in Buffer B again) is controlled through split_relw_tlow > and split_relw_thigh. Do you think there is a better way? Or is this > good enough? I think I'd try to reduce the number of sysfs files needed for this. What are the values you would typically set here? My feeling is that separating unaligned page writes from full pages or multiples of pages could always be benefitial for all cards, or at least harmless, but that will require more measurements. Whether to do the reliable write or not could be a simple flag if the numbers are the same. > So, as I mentioned before, T had done some tests given data provided > by M, and then T verified that this fix was good. I need to do my own > tests on the patch after I rewrite it. Is iozone the best tool I can > use? So far I have a MMC logging facility through connector that I use > to collect stats (useful for seeing how fs traffic translates to > actual mmc commands...once I clean it up I'll push here for RFC). What > about the tool you're writing? Any way I can use it? It's now available in a an early almost-usable version at git://git.linaro.org/people/arnd/flashbench.git I don't have a test for the second buffer yet, but it would be good to know some of the other characteristics of your eMMC drive. Please try some of these commands: flashbench -a /dev/mmcblk0 --blocksize=1024 flashbench --open-au --open-au-nr=1 /dev/mmcblk0 --blocksize=512 flashbench --open-au --open-au-nr=1 /dev/mmcblk0 --blocksize=512 --random flashbench --open-au --open-au-nr=2 /dev/mmcblk0 --blocksize=512 flashbench --open-au --open-au-nr=2 /dev/mmcblk0 --blocksize=512 --random flashbench --open-au --open-au-nr=3 /dev/mmcblk0 --blocksize=512 flashbench --open-au --open-au-nr=3 /dev/mmcblk0 --blocksize=512 --random Note that the --open-au test will overwrite your data. You can do it on a partition you don't use, but it needs to be aligned to 4 MB. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-17 15:47 ` Arnd Bergmann @ 2011-02-20 11:27 ` Andrei Warkentin -1 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-20 11:27 UTC (permalink / raw) To: Arnd Bergmann; +Cc: linux-arm-kernel, Linus Walleij, linux-mmc On Thu, Feb 17, 2011 at 9:47 AM, Arnd Bergmann <arnd@arndb.de> wrote: > I think I'd try to reduce the number of sysfs files needed for this. > What are the values you would typically set here? > > My feeling is that separating unaligned page writes from full pages > or multiples of pages could always be benefitial for all cards, or at > least harmless, but that will require more measurements. > Whether to do the reliable write or not could be a simple flag > if the numbers are the same. I thought about this some more, and I realized it would be ugly if everybody added enable_workaround_sec_start/enable_workaround_sec_end for every novel idea of working around some issue with performance/reliability on mmc/sd cards. What about letting the user/embedder create policies for how certain accesses are done? That way you give runtime-accessible blocks for tuning mmc block layer while having one interface to manipulate (and combine) multiple workarounds, all the while catching conflicts and without forcing specific policy in code. Essentially under /sys/block/mmcblk0/device you have an attribute called "policies". Example: # echo mypol0 > /sys/block/mmcblk0/device/policies # ls /sys/block/mmcblk0/device/mypol0 debug delete start_block end_block access_size_low access_size_high write_policy erase_policy read_policy # cat /sys/block/mmcblk0/device/mypol0/write_policy Current: none 0x00000001: Split unaligned writes across page_size 0x00000002: Split writes into page_size chunks and write using reliable writes 0x00000004: Use reliable writes for WRITE_META blocks. # cat /sys/block/mmcblk0/device/mypol0/erase_policy Current: none 0x00000001: Use secure erase. # echo 1 > delete # Policy is deleted. The policies are all stored in a rb-tree. First order of business inside mmc_blk_issue_rw_rq/mmc_blk_issue_* is to fetch an existing policy given the access type and block start/end (which both tells where the access is going and the size of the access). Later, it's that policy information which controls how the request is translated into MMC commands. I'm almost done with a prototype. I noticed that all sysfs attributes are managed by code under core/mmc.c and core/sd.c, duplicating where necessary. I think some of the new block-related settings like page_size (or policies) are generic enough that they should live in the card/block code. How about putting all future sysfs block related things into block-sysfs.c? Thanks, A ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-20 11:27 ` Andrei Warkentin 0 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-20 11:27 UTC (permalink / raw) To: linux-arm-kernel On Thu, Feb 17, 2011 at 9:47 AM, Arnd Bergmann <arnd@arndb.de> wrote: > I think I'd try to reduce the number of sysfs files needed for this. > What are the values you would typically set here? > > My feeling is that separating unaligned page writes from full pages > or multiples of pages could always be benefitial for all cards, or at > least harmless, but that will require more measurements. > Whether to do the reliable write or not could be a simple flag > if the numbers are the same. I thought about this some more, and I realized it would be ugly if everybody added enable_workaround_sec_start/enable_workaround_sec_end for every novel idea of working around some issue with performance/reliability on mmc/sd cards. What about letting the user/embedder create policies for how certain accesses are done? That way you give runtime-accessible blocks for tuning mmc block layer while having one interface to manipulate (and combine) multiple workarounds, all the while catching conflicts and without forcing specific policy in code. Essentially under /sys/block/mmcblk0/device you have an attribute called "policies". Example: # echo mypol0 > /sys/block/mmcblk0/device/policies # ls /sys/block/mmcblk0/device/mypol0 debug delete start_block end_block access_size_low access_size_high write_policy erase_policy read_policy # cat /sys/block/mmcblk0/device/mypol0/write_policy Current: none 0x00000001: Split unaligned writes across page_size 0x00000002: Split writes into page_size chunks and write using reliable writes 0x00000004: Use reliable writes for WRITE_META blocks. # cat /sys/block/mmcblk0/device/mypol0/erase_policy Current: none 0x00000001: Use secure erase. # echo 1 > delete # Policy is deleted. The policies are all stored in a rb-tree. First order of business inside mmc_blk_issue_rw_rq/mmc_blk_issue_* is to fetch an existing policy given the access type and block start/end (which both tells where the access is going and the size of the access). Later, it's that policy information which controls how the request is translated into MMC commands. I'm almost done with a prototype. I noticed that all sysfs attributes are managed by code under core/mmc.c and core/sd.c, duplicating where necessary. I think some of the new block-related settings like page_size (or policies) are generic enough that they should live in the card/block code. How about putting all future sysfs block related things into block-sysfs.c? Thanks, A ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-20 11:27 ` Andrei Warkentin @ 2011-02-20 14:39 ` Arnd Bergmann -1 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-20 14:39 UTC (permalink / raw) To: linux-arm-kernel, linux-fsdevel Cc: Andrei Warkentin, Linus Walleij, linux-mmc [adding linux-fsdevel to Cc, see http://lwn.net/Articles/428941/ and http://comments.gmane.org/gmane.linux.ports.arm.kernel/105607 for more on this discussion.] On Sunday 20 February 2011 12:27:39 Andrei Warkentin wrote: > On Thu, Feb 17, 2011 at 9:47 AM, Arnd Bergmann <arnd@arndb.de> wrote: > > I think I'd try to reduce the number of sysfs files needed for this. > > What are the values you would typically set here? > > > > My feeling is that separating unaligned page writes from full pages > > or multiples of pages could always be benefitial for all cards, or at > > least harmless, but that will require more measurements. > > Whether to do the reliable write or not could be a simple flag > > if the numbers are the same. > > I thought about this some more, and I realized it would be ugly if > everybody added enable_workaround_sec_start/enable_workaround_sec_end > for every novel idea of working around some issue with > performance/reliability on mmc/sd cards. > > What about letting the user/embedder create policies for how certain > accesses are done? That way you give runtime-accessible > blocks for tuning mmc block layer while having one interface to > manipulate (and combine) multiple workarounds, all the while catching > conflicts and > without forcing specific policy in code. > > Essentially under /sys/block/mmcblk0/device you have an attribute > called "policies". Example: > > # echo mypol0 > /sys/block/mmcblk0/device/policies > # ls /sys/block/mmcblk0/device/mypol0 > debug > delete > start_block > end_block > access_size_low > access_size_high > write_policy > erase_policy > read_policy > # cat /sys/block/mmcblk0/device/mypol0/write_policy > Current: none > 0x00000001: Split unaligned writes across page_size > 0x00000002: Split writes into page_size chunks and write using reliable writes > 0x00000004: Use reliable writes for WRITE_META blocks. > # cat /sys/block/mmcblk0/device/mypol0/erase_policy > Current: none > 0x00000001: Use secure erase. > # echo 1 > delete > # Policy is deleted. > > The policies are all stored in a rb-tree. First order of business > inside mmc_blk_issue_rw_rq/mmc_blk_issue_* is to fetch an existing > policy given the access type and block start/end (which both tells > where the access is going and the size of the access). Later, it's > that policy information which controls how the request is translated > into MMC commands. I'm almost done with a prototype. I think it's good to discuss all the options, but my feeling is that we should not add so much complexity at the interface level, because we will never be able to change all that again. In general, sysfs files should contain simple values that are self-descriptive (a simple number or one word), and should have no side-effects (unlike the delete or the policies attributes you describe). The behavior of the Toshiba chip is peculiar enough to justify having some workarounds for it, including run-time selected ones, but I'm looking for something much simpler. I'd certainly be interested in the patch you come up with and any performance results, but I don't think it can be merged like that. In the end, Chris will have to make the decision on mmc patches of course -- I'm just trying to contribute experience from other subsystems. What I see as a more promising approach is to add the tunables to attributes of the CFQ I/O scheduler once we know what we want. This will allow doing the same optimizations to non-MMC devices such as USB sticks or CF/IDE cards without reimplementing it in other subsystems, and give more control over the individual requests than the MMC layer has. E.g. the I/O scheduler can also make sure that we always submit all blocks from the start of one erase unit (e.g. 4 MB) to the end, but not try to merge requests across erase unit boundaries. It can also try to group the requests in aligned power-of-two sized chunks rather than merging as many sectors as possible up to the maximum request size, ignoring the alignment. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-20 14:39 ` Arnd Bergmann 0 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-20 14:39 UTC (permalink / raw) To: linux-arm-kernel [adding linux-fsdevel to Cc, see http://lwn.net/Articles/428941/ and http://comments.gmane.org/gmane.linux.ports.arm.kernel/105607 for more on this discussion.] On Sunday 20 February 2011 12:27:39 Andrei Warkentin wrote: > On Thu, Feb 17, 2011 at 9:47 AM, Arnd Bergmann <arnd@arndb.de> wrote: > > I think I'd try to reduce the number of sysfs files needed for this. > > What are the values you would typically set here? > > > > My feeling is that separating unaligned page writes from full pages > > or multiples of pages could always be benefitial for all cards, or at > > least harmless, but that will require more measurements. > > Whether to do the reliable write or not could be a simple flag > > if the numbers are the same. > > I thought about this some more, and I realized it would be ugly if > everybody added enable_workaround_sec_start/enable_workaround_sec_end > for every novel idea of working around some issue with > performance/reliability on mmc/sd cards. > > What about letting the user/embedder create policies for how certain > accesses are done? That way you give runtime-accessible > blocks for tuning mmc block layer while having one interface to > manipulate (and combine) multiple workarounds, all the while catching > conflicts and > without forcing specific policy in code. > > Essentially under /sys/block/mmcblk0/device you have an attribute > called "policies". Example: > > # echo mypol0 > /sys/block/mmcblk0/device/policies > # ls /sys/block/mmcblk0/device/mypol0 > debug > delete > start_block > end_block > access_size_low > access_size_high > write_policy > erase_policy > read_policy > # cat /sys/block/mmcblk0/device/mypol0/write_policy > Current: none > 0x00000001: Split unaligned writes across page_size > 0x00000002: Split writes into page_size chunks and write using reliable writes > 0x00000004: Use reliable writes for WRITE_META blocks. > # cat /sys/block/mmcblk0/device/mypol0/erase_policy > Current: none > 0x00000001: Use secure erase. > # echo 1 > delete > # Policy is deleted. > > The policies are all stored in a rb-tree. First order of business > inside mmc_blk_issue_rw_rq/mmc_blk_issue_* is to fetch an existing > policy given the access type and block start/end (which both tells > where the access is going and the size of the access). Later, it's > that policy information which controls how the request is translated > into MMC commands. I'm almost done with a prototype. I think it's good to discuss all the options, but my feeling is that we should not add so much complexity at the interface level, because we will never be able to change all that again. In general, sysfs files should contain simple values that are self-descriptive (a simple number or one word), and should have no side-effects (unlike the delete or the policies attributes you describe). The behavior of the Toshiba chip is peculiar enough to justify having some workarounds for it, including run-time selected ones, but I'm looking for something much simpler. I'd certainly be interested in the patch you come up with and any performance results, but I don't think it can be merged like that. In the end, Chris will have to make the decision on mmc patches of course -- I'm just trying to contribute experience from other subsystems. What I see as a more promising approach is to add the tunables to attributes of the CFQ I/O scheduler once we know what we want. This will allow doing the same optimizations to non-MMC devices such as USB sticks or CF/IDE cards without reimplementing it in other subsystems, and give more control over the individual requests than the MMC layer has. E.g. the I/O scheduler can also make sure that we always submit all blocks from the start of one erase unit (e.g. 4 MB) to the end, but not try to merge requests across erase unit boundaries. It can also try to group the requests in aligned power-of-two sized chunks rather than merging as many sectors as possible up to the maximum request size, ignoring the alignment. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-20 14:39 ` Arnd Bergmann @ 2011-02-22 7:46 ` Andrei Warkentin -1 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-22 7:46 UTC (permalink / raw) To: Arnd Bergmann; +Cc: linux-arm-kernel, linux-fsdevel, Linus Walleij, linux-mmc On Sun, Feb 20, 2011 at 8:39 AM, Arnd Bergmann <arnd@arndb.de> wrote: > [adding linux-fsdevel to Cc, see http://lwn.net/Articles/428941/ and > http://comments.gmane.org/gmane.linux.ports.arm.kernel/105607 for more > on this discussion.] > > > I think it's good to discuss all the options, but my feeling is that > we should not add so much complexity at the interface level, because > we will never be able to change all that again. In general, sysfs > files should contain simple values that are self-descriptive (a simple > number or one word), and should have no side-effects (unlike the delete > or the policies attributes you describe). > > The behavior of the Toshiba chip is peculiar enough to justify having > some workarounds for it, including run-time selected ones, but I'm > looking for something much simpler. I'd certainly be interested in > the patch you come up with and any performance results, but I don't > think it can be merged like that. > Sure. The page_align patch is just going to be a single sysfs attribute. All I need to prove to myself now is the effect for large unaligned accesses (and show everyone else the data :-)). > In the end, Chris will have to make the decision on mmc patches of > course -- I'm just trying to contribute experience from other subsystems. > > What I see as a more promising approach is to add the tunables > to attributes of the CFQ I/O scheduler once we know what we want. > This will allow doing the same optimizations to non-MMC devices such > as USB sticks or CF/IDE cards without reimplementing it in other > subsystems, and give more control over the individual requests than > the MMC layer has. > > E.g. the I/O scheduler can also make sure that we always submit all > blocks from the start of one erase unit (e.g. 4 MB) to the end, but > not try to merge requests across erase unit boundaries. It can > also try to group the requests in aligned power-of-two sized chunks > rather than merging as many sectors as possible up to the maximum > request size, ignoring the alignment. I agree. These are common things that affect any kind of flash storage, and it belongs in the I/O scheduler as simple tuneables. I'll see if I can figure my way around that... What belongs in mmc card driver are tunable workarounds for MMC/SD brokeness. For example - needing to use 8K-spitted reliable writes to ensure that a 64KB access doesn't wind up in the 4MB buffer B (as to improve lifespan of the card.) But you want a waterline above which you don't do this anymore, otherwise the overall performance will go to 0 - i.e. there is a need to balance between performance and reliability, so the range of access size for which the workaround works needs to be runtime controlled, as it's potentially different. Another example (this one is apparently affecting Sandisk) - do special stuff for block erase, since the card violates spec in that regard (touch ext_csd instead of argument, I believe). A different example might be turning on reliable writes for WRITE_META (or all) blocks for a certain partition (but I just made that up... ). So there are things that just should be on (spec brokeness workarounds), and things that apply only to a subset of accesses (and thus they are selective at issue_*_rq time), whether it's because of accessed offset or access size. I agree that the sysfs method is particularly nasty, and I guess I didn't have to make a prototype to figure that out :-) (but needed something similar for selective testing anyway). Nothing else exists right now that acts in the same way, and nothing really should, as there is no feedback for manipulating the policies (echo POLICY_ENUM > policy, if it doesn't stick, then the arguments were wrong, etc). You could put the entire MMC block policy interface through an API usable by system integrators - i.e. you would really only care for tuning the MMC parameters if you're creating a device around an emmc. Idea (1). One idea is to keep the "policies" from my previous mail. Policies are registered through platform-specific code. The policies could be then matched for enabling against a specific block device by manfid/date/etc at the time of mmc_block_alloc... For removable media no one would fiddle with the tunable parameters anyway, unless there was some global database of cards and workarounds and a daemon or some such to take care of that... Probably don't want to add such baggage to the kernel. Idea (2). There is probably no need to overcomplicate. Just add a platform callback (something like int (*mmc_platform_block_workaround)(struct request *, struct mmc_blk_request *)). This will be usable as-is for R/W accesses, and the discard code will need to be slightly modified. Do you think there is any need for runtime tuning of the MMC workarounds (disregarding ones that really belong in the I/O scheduler)? Should the workarounds be simply platform callbacks, or should they be something heftier ("policies")? A ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-22 7:46 ` Andrei Warkentin 0 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-22 7:46 UTC (permalink / raw) To: linux-arm-kernel On Sun, Feb 20, 2011 at 8:39 AM, Arnd Bergmann <arnd@arndb.de> wrote: > [adding linux-fsdevel to Cc, see http://lwn.net/Articles/428941/ and > http://comments.gmane.org/gmane.linux.ports.arm.kernel/105607 for more > on this discussion.] > > > I think it's good to discuss all the options, but my feeling is that > we should not add so much complexity at the interface level, because > we will never be able to change all that again. In general, sysfs > files should contain simple values that are self-descriptive (a simple > number or one word), and should have no side-effects (unlike the delete > or the policies attributes you describe). > > The behavior of the Toshiba chip is peculiar enough to justify having > some workarounds for it, including run-time selected ones, but I'm > looking for something much simpler. I'd certainly be interested in > the patch you come up with and any performance results, but I don't > think it can be merged like that. > Sure. The page_align patch is just going to be a single sysfs attribute. All I need to prove to myself now is the effect for large unaligned accesses (and show everyone else the data :-)). > In the end, Chris will have to make the decision on mmc patches of > course -- I'm just trying to contribute experience from other subsystems. > > What I see as a more promising approach is to add the tunables > to attributes of the CFQ I/O scheduler once we know what we want. > This will allow doing the same optimizations to non-MMC devices such > as USB sticks or CF/IDE cards without reimplementing it in other > subsystems, and give more control over the individual requests than > the MMC layer has. > > E.g. the I/O scheduler can also make sure that we always submit all > blocks from the start of one erase unit (e.g. 4 MB) to the end, but > not try to merge requests across erase unit boundaries. It can > also try to group the requests in aligned power-of-two sized chunks > rather than merging as many sectors as possible up to the maximum > request size, ignoring the alignment. I agree. These are common things that affect any kind of flash storage, and it belongs in the I/O scheduler as simple tuneables. I'll see if I can figure my way around that... What belongs in mmc card driver are tunable workarounds for MMC/SD brokeness. For example - needing to use 8K-spitted reliable writes to ensure that a 64KB access doesn't wind up in the 4MB buffer B (as to improve lifespan of the card.) But you want a waterline above which you don't do this anymore, otherwise the overall performance will go to 0 - i.e. there is a need to balance between performance and reliability, so the range of access size for which the workaround works needs to be runtime controlled, as it's potentially different. Another example (this one is apparently affecting Sandisk) - do special stuff for block erase, since the card violates spec in that regard (touch ext_csd instead of argument, I believe). A different example might be turning on reliable writes for WRITE_META (or all) blocks for a certain partition (but I just made that up... ). So there are things that just should be on (spec brokeness workarounds), and things that apply only to a subset of accesses (and thus they are selective at issue_*_rq time), whether it's because of accessed offset or access size. I agree that the sysfs method is particularly nasty, and I guess I didn't have to make a prototype to figure that out :-) (but needed something similar for selective testing anyway). Nothing else exists right now that acts in the same way, and nothing really should, as there is no feedback for manipulating the policies (echo POLICY_ENUM > policy, if it doesn't stick, then the arguments were wrong, etc). You could put the entire MMC block policy interface through an API usable by system integrators - i.e. you would really only care for tuning the MMC parameters if you're creating a device around an emmc. Idea (1). One idea is to keep the "policies" from my previous mail. Policies are registered through platform-specific code. The policies could be then matched for enabling against a specific block device by manfid/date/etc at the time of mmc_block_alloc... For removable media no one would fiddle with the tunable parameters anyway, unless there was some global database of cards and workarounds and a daemon or some such to take care of that... Probably don't want to add such baggage to the kernel. Idea (2). There is probably no need to overcomplicate. Just add a platform callback (something like int (*mmc_platform_block_workaround)(struct request *, struct mmc_blk_request *)). This will be usable as-is for R/W accesses, and the discard code will need to be slightly modified. Do you think there is any need for runtime tuning of the MMC workarounds (disregarding ones that really belong in the I/O scheduler)? Should the workarounds be simply platform callbacks, or should they be something heftier ("policies")? A ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-22 7:46 ` Andrei Warkentin @ 2011-02-22 17:00 ` Arnd Bergmann -1 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-22 17:00 UTC (permalink / raw) To: Andrei Warkentin Cc: linux-arm-kernel, linux-fsdevel, Linus Walleij, linux-mmc On Tuesday 22 February 2011, Andrei Warkentin wrote: > On Sun, Feb 20, 2011 at 8:39 AM, Arnd Bergmann <arnd@arndb.de> wrote: > > E.g. the I/O scheduler can also make sure that we always submit all > > blocks from the start of one erase unit (e.g. 4 MB) to the end, but > > not try to merge requests across erase unit boundaries. It can > > also try to group the requests in aligned power-of-two sized chunks > > rather than merging as many sectors as possible up to the maximum > > request size, ignoring the alignment. > > I agree. These are common things that affect any kind of flash > storage, and it belongs in the I/O scheduler as simple tuneables. I'll > see if I can figure my way around that... > > What belongs in mmc card driver are tunable workarounds for MMC/SD > brokeness. For example - needing to use 8K-spitted reliable writes to > ensure that a 64KB access doesn't wind up in the 4MB buffer B (as to > improve lifespan of the card.) But you want a waterline above which > you don't do this anymore, otherwise the overall performance will go > to 0 - i.e. there is a need to balance between performance and > reliability, so the range of access size for which the workaround > works needs to be runtime controlled, as it's potentially different. > Another example (this one is apparently affecting Sandisk) - do > special stuff for block erase, since the card violates spec in that > regard (touch ext_csd instead of argument, I believe). A different > example might be turning on reliable writes for WRITE_META (or all) > blocks for a certain partition (but I just made that up... ). Yes, makes sense. > You could put the entire MMC block policy interface through an API > usable by system integrators - i.e. you would really only care for > tuning the MMC parameters if you're creating a device around an emmc. > > Idea (1). One idea is to keep the "policies" from my previous mail. > Policies are registered through platform-specific code. The policies > could be then matched for enabling against a specific block device by > manfid/date/etc at the time of mmc_block_alloc... For removable media > no one would fiddle with the tunable parameters anyway, unless there > was some global database of cards and workarounds and a daemon or some > such to take care of that... Probably don't want to add such baggage > to the kernel. > > Idea (2). There is probably no need to overcomplicate. Just add a > platform callback (something like int > (*mmc_platform_block_workaround)(struct request *, struct > mmc_blk_request *)). This will be usable as-is for R/W accesses, and > the discard code will need to be slightly modified. > > Do you think there is any need for runtime tuning of the MMC > workarounds (disregarding ones that really belong in the I/O > scheduler)? Should the workarounds be simply platform callbacks, or > should they be something heftier ("policies")? The platform hook seems the wrong place, because you might use the same chip in multiple platforms, and a single platform might have a large number of different boards, all of which require separate workarounds. A per-card quirk table does not seem so bad, we have that in other subsystems as well. I wouldn't necessarily make it a list of possible quirks, but rather a __devinit function that is called for a new card on insertion, in order to tweak various parameters. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-22 17:00 ` Arnd Bergmann 0 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-22 17:00 UTC (permalink / raw) To: linux-arm-kernel On Tuesday 22 February 2011, Andrei Warkentin wrote: > On Sun, Feb 20, 2011 at 8:39 AM, Arnd Bergmann <arnd@arndb.de> wrote: > > E.g. the I/O scheduler can also make sure that we always submit all > > blocks from the start of one erase unit (e.g. 4 MB) to the end, but > > not try to merge requests across erase unit boundaries. It can > > also try to group the requests in aligned power-of-two sized chunks > > rather than merging as many sectors as possible up to the maximum > > request size, ignoring the alignment. > > I agree. These are common things that affect any kind of flash > storage, and it belongs in the I/O scheduler as simple tuneables. I'll > see if I can figure my way around that... > > What belongs in mmc card driver are tunable workarounds for MMC/SD > brokeness. For example - needing to use 8K-spitted reliable writes to > ensure that a 64KB access doesn't wind up in the 4MB buffer B (as to > improve lifespan of the card.) But you want a waterline above which > you don't do this anymore, otherwise the overall performance will go > to 0 - i.e. there is a need to balance between performance and > reliability, so the range of access size for which the workaround > works needs to be runtime controlled, as it's potentially different. > Another example (this one is apparently affecting Sandisk) - do > special stuff for block erase, since the card violates spec in that > regard (touch ext_csd instead of argument, I believe). A different > example might be turning on reliable writes for WRITE_META (or all) > blocks for a certain partition (but I just made that up... ). Yes, makes sense. > You could put the entire MMC block policy interface through an API > usable by system integrators - i.e. you would really only care for > tuning the MMC parameters if you're creating a device around an emmc. > > Idea (1). One idea is to keep the "policies" from my previous mail. > Policies are registered through platform-specific code. The policies > could be then matched for enabling against a specific block device by > manfid/date/etc at the time of mmc_block_alloc... For removable media > no one would fiddle with the tunable parameters anyway, unless there > was some global database of cards and workarounds and a daemon or some > such to take care of that... Probably don't want to add such baggage > to the kernel. > > Idea (2). There is probably no need to overcomplicate. Just add a > platform callback (something like int > (*mmc_platform_block_workaround)(struct request *, struct > mmc_blk_request *)). This will be usable as-is for R/W accesses, and > the discard code will need to be slightly modified. > > Do you think there is any need for runtime tuning of the MMC > workarounds (disregarding ones that really belong in the I/O > scheduler)? Should the workarounds be simply platform callbacks, or > should they be something heftier ("policies")? The platform hook seems the wrong place, because you might use the same chip in multiple platforms, and a single platform might have a large number of different boards, all of which require separate workarounds. A per-card quirk table does not seem so bad, we have that in other subsystems as well. I wouldn't necessarily make it a list of possible quirks, but rather a __devinit function that is called for a new card on insertion, in order to tweak various parameters. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-22 17:00 ` Arnd Bergmann @ 2011-02-23 10:19 ` Andrei Warkentin -1 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-23 10:19 UTC (permalink / raw) To: Arnd Bergmann; +Cc: linux-arm-kernel, linux-fsdevel, Linus Walleij, linux-mmc On Tue, Feb 22, 2011 at 11:00 AM, Arnd Bergmann <arnd@arndb.de> wrote: >> >> Do you think there is any need for runtime tuning of the MMC >> workarounds (disregarding ones that really belong in the I/O >> scheduler)? Should the workarounds be simply platform callbacks, or >> should they be something heftier ("policies")? > > The platform hook seems the wrong place, because you might use > the same chip in multiple platforms, and a single platform might > have a large number of different boards, all of which require > separate workarounds. > That's a good point. At best it would result in massive copy-paste/ > A per-card quirk table does not seem so bad, we have that in > other subsystems as well. I wouldn't necessarily make it > a list of possible quirks, but rather a __devinit function that > is called for a new card on insertion, in order to tweak various > parameters. > That sounds good! In fact, for any quirks enabled for a particular card, I'll expose the tuneables through sysfs attributes, something like /sys/block/mmcblk0/device/quirks/quirk-name/attr-names. Quirks will have block intervals and access size intervals over which they are valid, along with any other quirk-specific parameter. Interval overlap will not be allowed for quirks in the same operation type (r/w/e). The goal here is to make the changes to issue_*_rq as small as possible, and not to pollute block.c at all with the quirks stuff. Quirks are looked up inside issue_*_rq based on req type and [start,end) interval. The resulting found quirks structure will contain a callback used inside issue_*_rq to modify mmc block request structures prior to generating actual MMC commands. Quirks consist of a callback called inside of mmc issue_*_rq, configurable attributes, and the sysfs interface. Quirk groups are defined per-card. At card insertion time, a matching quirk group is found, and is enabled. The quirk group enable function then enables the relevant quirks with the right parameters (adds them to per mmc_blk_data quirk interval tree). Some sane defaults for the tunables are used. If the tunables are modified through sysfs, care is taken that an interval overlap never happens, otherwise the tunable is not modified and a kernel error message is logged. I hope I explained the tentative idea clearly... Thoughts? A ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-23 10:19 ` Andrei Warkentin 0 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-23 10:19 UTC (permalink / raw) To: linux-arm-kernel On Tue, Feb 22, 2011 at 11:00 AM, Arnd Bergmann <arnd@arndb.de> wrote: >> >> Do you think there is any need for runtime tuning of the MMC >> workarounds (disregarding ones that really belong in the I/O >> scheduler)? Should the workarounds be simply platform callbacks, or >> should they be something heftier ("policies")? > > The platform hook seems the wrong place, because you might use > the same chip in multiple platforms, and a single platform might > have a large number of different boards, all of which require > separate workarounds. > That's a good point. At best it would result in massive copy-paste/ > A per-card quirk table does not seem so bad, we have that in > other subsystems as well. I wouldn't necessarily make it > a list of possible quirks, but rather a __devinit function that > is called for a new card on insertion, in order to tweak various > parameters. > That sounds good! In fact, for any quirks enabled for a particular card, I'll expose the tuneables through sysfs attributes, something like /sys/block/mmcblk0/device/quirks/quirk-name/attr-names. Quirks will have block intervals and access size intervals over which they are valid, along with any other quirk-specific parameter. Interval overlap will not be allowed for quirks in the same operation type (r/w/e). The goal here is to make the changes to issue_*_rq as small as possible, and not to pollute block.c at all with the quirks stuff. Quirks are looked up inside issue_*_rq based on req type and [start,end) interval. The resulting found quirks structure will contain a callback used inside issue_*_rq to modify mmc block request structures prior to generating actual MMC commands. Quirks consist of a callback called inside of mmc issue_*_rq, configurable attributes, and the sysfs interface. Quirk groups are defined per-card. At card insertion time, a matching quirk group is found, and is enabled. The quirk group enable function then enables the relevant quirks with the right parameters (adds them to per mmc_blk_data quirk interval tree). Some sane defaults for the tunables are used. If the tunables are modified through sysfs, care is taken that an interval overlap never happens, otherwise the tunable is not modified and a kernel error message is logged. I hope I explained the tentative idea clearly... Thoughts? A ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-23 10:19 ` Andrei Warkentin @ 2011-02-23 16:09 ` Arnd Bergmann -1 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-23 16:09 UTC (permalink / raw) To: Andrei Warkentin Cc: linux-arm-kernel, linux-fsdevel, Linus Walleij, linux-mmc On Wednesday 23 February 2011, Andrei Warkentin wrote: > That sounds good! In fact, for any quirks enabled for a particular > card, I'll expose the tuneables through sysfs attributes, something > like /sys/block/mmcblk0/device/quirks/quirk-name/attr-names. > > Quirks will have block intervals and access size intervals over which > they are valid, along with any other quirk-specific parameter. > Interval overlap will not be allowed for quirks in the same operation > type (r/w/e). The goal here is to make the changes to issue_*_rq as > small as possible, and not to pollute block.c at all with the quirks > stuff. Quirks are looked up inside issue_*_rq based on req type and > [start,end) interval. The resulting found quirks structure will > contain a callback used inside issue_*_rq to modify mmc block request > structures prior to generating actual MMC commands. > > Quirks consist of a callback called inside of mmc issue_*_rq, > configurable attributes, and the sysfs interface. Quirk groups are > defined per-card. At card insertion time, a matching quirk group is > found, and is enabled. The quirk group enable function then enables > the relevant quirks with the right parameters (adds them to per > mmc_blk_data quirk interval tree). Some sane defaults for the tunables > are used. If the tunables are modified through sysfs, care is taken > that an interval overlap never happens, otherwise the tunable is not > modified and a kernel error message is logged. > > I hope I explained the tentative idea clearly... Thoughts? I would hope that the quirks can be simpler than this still, without the need to call any function pointers while using the device, or quirk specific sysfs directories. What I meant is to have a single function pointer that can get called when detecting a specific known card. All this function does is to set values and flags that we can export either through common attributes of block devices (e.g. preferred erase size), or attributes specific to mmc devices (e.g. the toshiba hack, as a bool attribute). An obvious attribute would be the minimum size of an atomic page update. By default this could be 32KB, because any device should support that (FAT32 cannot have larger clusters). A card specific quirk can set it to another value, like 8KB, 16KB or 64KB, and file systems or other tools like mkfs can optimize for this value. I would like the flags like "don't submit requests spanning this boundary" and "make all writes below this size" to be defined in terms of the regular sizes we already know about, like the page size or the erase size. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-23 16:09 ` Arnd Bergmann 0 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-23 16:09 UTC (permalink / raw) To: linux-arm-kernel On Wednesday 23 February 2011, Andrei Warkentin wrote: > That sounds good! In fact, for any quirks enabled for a particular > card, I'll expose the tuneables through sysfs attributes, something > like /sys/block/mmcblk0/device/quirks/quirk-name/attr-names. > > Quirks will have block intervals and access size intervals over which > they are valid, along with any other quirk-specific parameter. > Interval overlap will not be allowed for quirks in the same operation > type (r/w/e). The goal here is to make the changes to issue_*_rq as > small as possible, and not to pollute block.c at all with the quirks > stuff. Quirks are looked up inside issue_*_rq based on req type and > [start,end) interval. The resulting found quirks structure will > contain a callback used inside issue_*_rq to modify mmc block request > structures prior to generating actual MMC commands. > > Quirks consist of a callback called inside of mmc issue_*_rq, > configurable attributes, and the sysfs interface. Quirk groups are > defined per-card. At card insertion time, a matching quirk group is > found, and is enabled. The quirk group enable function then enables > the relevant quirks with the right parameters (adds them to per > mmc_blk_data quirk interval tree). Some sane defaults for the tunables > are used. If the tunables are modified through sysfs, care is taken > that an interval overlap never happens, otherwise the tunable is not > modified and a kernel error message is logged. > > I hope I explained the tentative idea clearly... Thoughts? I would hope that the quirks can be simpler than this still, without the need to call any function pointers while using the device, or quirk specific sysfs directories. What I meant is to have a single function pointer that can get called when detecting a specific known card. All this function does is to set values and flags that we can export either through common attributes of block devices (e.g. preferred erase size), or attributes specific to mmc devices (e.g. the toshiba hack, as a bool attribute). An obvious attribute would be the minimum size of an atomic page update. By default this could be 32KB, because any device should support that (FAT32 cannot have larger clusters). A card specific quirk can set it to another value, like 8KB, 16KB or 64KB, and file systems or other tools like mkfs can optimize for this value. I would like the flags like "don't submit requests spanning this boundary" and "make all writes below this size" to be defined in terms of the regular sizes we already know about, like the page size or the erase size. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-23 16:09 ` Arnd Bergmann @ 2011-02-23 22:26 ` Andrei Warkentin -1 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-23 22:26 UTC (permalink / raw) To: Arnd Bergmann; +Cc: linux-arm-kernel, linux-fsdevel, Linus Walleij, linux-mmc On Wed, Feb 23, 2011 at 10:09 AM, Arnd Bergmann <arnd@arndb.de> wrote: > On Wednesday 23 February 2011, Andrei Warkentin wrote: >> That sounds good! In fact, for any quirks enabled for a particular >> card, I'll expose the tuneables through sysfs attributes, something >> like /sys/block/mmcblk0/device/quirks/quirk-name/attr-names. >> >> Quirks will have block intervals and access size intervals over which >> they are valid, along with any other quirk-specific parameter. >> Interval overlap will not be allowed for quirks in the same operation >> type (r/w/e). The goal here is to make the changes to issue_*_rq as >> small as possible, and not to pollute block.c at all with the quirks >> stuff. Quirks are looked up inside issue_*_rq based on req type and >> [start,end) interval. The resulting found quirks structure will >> contain a callback used inside issue_*_rq to modify mmc block request >> structures prior to generating actual MMC commands. >> >> Quirks consist of a callback called inside of mmc issue_*_rq, >> configurable attributes, and the sysfs interface. Quirk groups are >> defined per-card. At card insertion time, a matching quirk group is >> found, and is enabled. The quirk group enable function then enables >> the relevant quirks with the right parameters (adds them to per >> mmc_blk_data quirk interval tree). Some sane defaults for the tunables >> are used. If the tunables are modified through sysfs, care is taken >> that an interval overlap never happens, otherwise the tunable is not >> modified and a kernel error message is logged. >> >> I hope I explained the tentative idea clearly... Thoughts? > > I would hope that the quirks can be simpler than this still, without > the need to call any function pointers while using the device, or > quirk specific sysfs directories. > I'll skip the sysfs part from the first RFC patch. I think this complicates what I'm trying to achieve and makes this whole thing look bigger than it is. > What I meant is to have a single function pointer that can get > called when detecting a specific known card. All this function > does is to set values and flags that we can export either through > common attributes of block devices (e.g. preferred erase size), > or attributes specific to mmc devices (e.g. the toshiba hack, as > a bool attribute). > > An obvious attribute would be the minimum size of an atomic > page update. By default this could be 32KB, because any device > should support that (FAT32 cannot have larger clusters). A > card specific quirk can set it to another value, like 8KB, 16KB > or 64KB, and file systems or other tools like mkfs can optimize > for this value. > > I would like the flags like "don't submit requests spanning > this boundary" and "make all writes below this size" to be defined > in terms of the regular sizes we already know about, like the > page size or the erase size. > I agree with you on the size/align issues. These are very generic attributes and don't need a complicated framework like I described to be dealt with. Ultimately they are just hints to the I/O scheduler, so they should be part of the block device. I am more concerned with workarounds that depend on access size (like the toshiba one) and that modify the MMC commands sent (using reliable writes, like the Toshiba one, or putting parameters differently like the Sandisk erase workaround). It's these kinds of workarounds that the quirks framework is meant to address. I don't think it's a good idea to pollute mmc_blk_issue_rw_rq and mmc_blk_issue_discard_rq with if()-elsed workarounds, because it's going to quickly complicate the logic, and get out of hand and unmanageable the more cards are added. I'm trying to avoid having to make any changes to card/block.c as part of making quirk workarounds. The only cost when compared to an if-else will be one O(log n) quirk lookup, where n is either one or something close that (since the search is only done for quirks per mmc_blk_data), and one callback invoked after "brq.data.sg_len = mmc_queue_map_sg(mq);" so it can patch up mrq as necessary. ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-23 22:26 ` Andrei Warkentin 0 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-23 22:26 UTC (permalink / raw) To: linux-arm-kernel On Wed, Feb 23, 2011 at 10:09 AM, Arnd Bergmann <arnd@arndb.de> wrote: > On Wednesday 23 February 2011, Andrei Warkentin wrote: >> That sounds good! In fact, for any quirks enabled for a particular >> card, I'll expose the tuneables through sysfs attributes, something >> like /sys/block/mmcblk0/device/quirks/quirk-name/attr-names. >> >> Quirks will have block intervals and access size intervals over which >> they are valid, along with any other quirk-specific parameter. >> Interval overlap will not be allowed for quirks in the same operation >> type (r/w/e). The goal here is to make the changes to issue_*_rq as >> small as possible, and not to pollute block.c at all with the quirks >> stuff. Quirks are looked up inside issue_*_rq based on req type and >> [start,end) interval. The resulting found quirks structure will >> contain a callback used inside issue_*_rq to modify mmc block request >> structures prior to generating actual MMC commands. >> >> Quirks consist of a callback called inside of mmc issue_*_rq, >> configurable attributes, and the sysfs interface. Quirk groups are >> defined per-card. At card insertion time, a matching quirk group is >> found, and is enabled. The quirk group enable function then enables >> the relevant quirks with the right parameters (adds them to per >> mmc_blk_data quirk interval tree). Some sane defaults for the tunables >> are used. If the tunables are modified through sysfs, care is taken >> that an interval overlap never happens, otherwise the tunable is not >> modified and a kernel error message is logged. >> >> I hope I explained the tentative idea clearly... Thoughts? > > I would hope that the quirks can be simpler than this still, without > the need to call any function pointers while using the device, or > quirk specific sysfs directories. > I'll skip the sysfs part from the first RFC patch. I think this complicates what I'm trying to achieve and makes this whole thing look bigger than it is. > What I meant is to have a single function pointer that can get > called when detecting a specific known card. All this function > does is to set values and flags that we can export either through > common attributes of block devices (e.g. preferred erase size), > or attributes specific to mmc devices (e.g. the toshiba hack, as > a bool attribute). > > An obvious attribute would be the minimum size of an atomic > page update. By default this could be 32KB, because any device > should support that (FAT32 cannot have larger clusters). A > card specific quirk can set it to another value, like 8KB, 16KB > or 64KB, and file systems or other tools like mkfs can optimize > for this value. > > I would like the flags like "don't submit requests spanning > this boundary" and "make all writes below this size" to be defined > in terms of the regular sizes we already know about, like the > page size or the erase size. > I agree with you on the size/align issues. These are very generic attributes and don't need a complicated framework like I described to be dealt with. Ultimately they are just hints to the I/O scheduler, so they should be part of the block device. I am more concerned with workarounds that depend on access size (like the toshiba one) and that modify the MMC commands sent (using reliable writes, like the Toshiba one, or putting parameters differently like the Sandisk erase workaround). It's these kinds of workarounds that the quirks framework is meant to address. I don't think it's a good idea to pollute mmc_blk_issue_rw_rq and mmc_blk_issue_discard_rq with if()-elsed workarounds, because it's going to quickly complicate the logic, and get out of hand and unmanageable the more cards are added. I'm trying to avoid having to make any changes to card/block.c as part of making quirk workarounds. The only cost when compared to an if-else will be one O(log n) quirk lookup, where n is either one or something close that (since the search is only done for quirks per mmc_blk_data), and one callback invoked after "brq.data.sg_len = mmc_queue_map_sg(mq);" so it can patch up mrq as necessary. ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-23 22:26 ` Andrei Warkentin @ 2011-02-24 9:24 ` Arnd Bergmann -1 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-24 9:24 UTC (permalink / raw) To: Andrei Warkentin Cc: linux-arm-kernel, linux-fsdevel, Linus Walleij, linux-mmc On Wednesday 23 February 2011, Andrei Warkentin wrote: > I am more concerned with workarounds that depend on access size (like > the toshiba one) and that modify the MMC commands sent (using reliable > writes, like the Toshiba one, or putting parameters differently like > the Sandisk erase workaround). It's these kinds of workarounds that > the quirks framework is meant to address. I don't think it's a good > idea to pollute mmc_blk_issue_rw_rq and mmc_blk_issue_discard_rq with > if()-elsed workarounds, because it's going to quickly complicate the > logic, and get out of hand and unmanageable the more cards are added. > I'm trying to avoid having to make any changes to card/block.c as part > of making quirk workarounds. The only cost when compared to an if-else > will be one O(log n) quirk lookup, where n is either one or something > close that (since the search is only done for quirks per > mmc_blk_data), and one callback invoked after "brq.data.sg_len = > mmc_queue_map_sg(mq);" so it can patch up mrq as necessary. Unlike the sysfs interface, the code does not need to be future-proof, it can always be changed if we feel the code becomes more maintainable by doing it another way. The approach that I'd like to see here is: * Start out with an ad-hoc patch for a quirk (like the one you already have). * Add a boolean variable to enable it per card. * Get performance data for this quirk to show that it's useful in real-world workloads for some cards but counterproductive for others * Get the patch into the mmc tree. * Repeat for the next quirk * When the code becomes overly complicated after adding all the quirks, decide on a good strategy to move the code around, and do a new patch. I understand that you are convinced that you will need the indirect function calls in the end. That is fine, just don't add them before they are actually needed -- that would only make it harder for you to get the first patch included. Note that the situation is very different for user interfaces such as sysfs: You need to plan ahead because once the interface is merged upstream, it can never be changed. When you submit a patch that introduces a new sysfs interface, it has to be documented, and you have to convince the reviewers that it is sufficient to cover all the cases it is designed for, while at the same time it is the most simple way to achieve this. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-24 9:24 ` Arnd Bergmann 0 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-24 9:24 UTC (permalink / raw) To: linux-arm-kernel On Wednesday 23 February 2011, Andrei Warkentin wrote: > I am more concerned with workarounds that depend on access size (like > the toshiba one) and that modify the MMC commands sent (using reliable > writes, like the Toshiba one, or putting parameters differently like > the Sandisk erase workaround). It's these kinds of workarounds that > the quirks framework is meant to address. I don't think it's a good > idea to pollute mmc_blk_issue_rw_rq and mmc_blk_issue_discard_rq with > if()-elsed workarounds, because it's going to quickly complicate the > logic, and get out of hand and unmanageable the more cards are added. > I'm trying to avoid having to make any changes to card/block.c as part > of making quirk workarounds. The only cost when compared to an if-else > will be one O(log n) quirk lookup, where n is either one or something > close that (since the search is only done for quirks per > mmc_blk_data), and one callback invoked after "brq.data.sg_len = > mmc_queue_map_sg(mq);" so it can patch up mrq as necessary. Unlike the sysfs interface, the code does not need to be future-proof, it can always be changed if we feel the code becomes more maintainable by doing it another way. The approach that I'd like to see here is: * Start out with an ad-hoc patch for a quirk (like the one you already have). * Add a boolean variable to enable it per card. * Get performance data for this quirk to show that it's useful in real-world workloads for some cards but counterproductive for others * Get the patch into the mmc tree. * Repeat for the next quirk * When the code becomes overly complicated after adding all the quirks, decide on a good strategy to move the code around, and do a new patch. I understand that you are convinced that you will need the indirect function calls in the end. That is fine, just don't add them before they are actually needed -- that would only make it harder for you to get the first patch included. Note that the situation is very different for user interfaces such as sysfs: You need to plan ahead because once the interface is merged upstream, it can never be changed. When you submit a patch that introduces a new sysfs interface, it has to be documented, and you have to convince the reviewers that it is sufficient to cover all the cases it is designed for, while at the same time it is the most simple way to achieve this. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-24 9:24 ` Arnd Bergmann @ 2011-02-25 11:02 ` Andrei Warkentin -1 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-25 11:02 UTC (permalink / raw) To: Arnd Bergmann; +Cc: linux-arm-kernel, linux-fsdevel, Linus Walleij, linux-mmc On Thu, Feb 24, 2011 at 3:24 AM, Arnd Bergmann <arnd@arndb.de> wrote: > Unlike the sysfs interface, the code does not need to be future-proof, > it can always be changed if we feel the code becomes more maintainable > by doing it another way. > > The approach that I'd like to see here is: > > * Start out with an ad-hoc patch for a quirk (like the one you already > have). > * Add a boolean variable to enable it per card. > * Get performance data for this quirk to show that it's useful in > real-world workloads for some cards but counterproductive for others > * Get the patch into the mmc tree. > * Repeat for the next quirk > * When the code becomes overly complicated after adding all the quirks, > decide on a good strategy to move the code around, and do a new patch. > Yup. I understand :-). That's the strategy I'm going to follow. For page_size-alignment/splitting I'm looking at the block layer now. Is that the right approach or should I still submit a (cleaned up) patch to mmc/card/block.c for that performance improvement? The other (Toshiba quirk) is obviously a quirk belonging to mmc/card/block.c. > I understand that you are convinced that you will need the indirect function > calls in the end. That is fine, just don't add them before they are > actually needed -- that would only make it harder for you to get the first > patch included. > > Note that the situation is very different for user interfaces such as sysfs: > You need to plan ahead because once the interface is merged upstream, it > can never be changed. When you submit a patch that introduces a new sysfs > interface, it has to be documented, and you have to convince the reviewers > that it is sufficient to cover all the cases it is designed for, while > at the same time it is the most simple way to achieve this. Ok, thanks a lot for the explanation, I hadn't thought of it that way (and should have). A -- To unsubscribe from this list: send the line "unsubscribe linux-fsdevel" in the body of a message to majordomo@vger.kernel.org More majordomo info at http://vger.kernel.org/majordomo-info.html ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-25 11:02 ` Andrei Warkentin 0 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-02-25 11:02 UTC (permalink / raw) To: linux-arm-kernel On Thu, Feb 24, 2011 at 3:24 AM, Arnd Bergmann <arnd@arndb.de> wrote: > Unlike the sysfs interface, the code does not need to be future-proof, > it can always be changed if we feel the code becomes more maintainable > by doing it another way. > > The approach that I'd like to see here is: > > * Start out with an ad-hoc patch for a quirk (like the one you already > ?have). > * Add a boolean variable to enable it per card. > * Get performance data for this quirk to show that it's useful in > ?real-world workloads for some cards but counterproductive for others > * Get the patch into the mmc tree. > * Repeat for the next quirk > * When the code becomes overly complicated after adding all the quirks, > ?decide on a good strategy to move the code around, and do a new patch. > Yup. I understand :-). That's the strategy I'm going to follow. For page_size-alignment/splitting I'm looking at the block layer now. Is that the right approach or should I still submit a (cleaned up) patch to mmc/card/block.c for that performance improvement? The other (Toshiba quirk) is obviously a quirk belonging to mmc/card/block.c. > I understand that you are convinced that you will need the indirect function > calls in the end. That is fine, just don't add them before they are > actually needed -- that would only make it harder for you to get the first > patch included. > > Note that the situation is very different for user interfaces such as sysfs: > You need to plan ahead because once the interface is merged upstream, it > can never be changed. When you submit a patch that introduces a new sysfs > interface, it has to be documented, and you have to convince the reviewers > that it is sufficient to cover all the cases it is designed for, while > at the same time it is the most simple way to achieve this. Ok, thanks a lot for the explanation, I hadn't thought of it that way (and should have). A ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-25 11:02 ` Andrei Warkentin @ 2011-02-25 12:21 ` Arnd Bergmann -1 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-25 12:21 UTC (permalink / raw) To: Andrei Warkentin, Jens Axboe Cc: linux-arm-kernel, linux-fsdevel, Linus Walleij, linux-mmc On Friday 25 February 2011, Andrei Warkentin wrote: > Yup. I understand :-). That's the strategy I'm going to follow. For > page_size-alignment/splitting I'm looking at the block layer now. Is > that the right approach or should I still submit a (cleaned up) patch > to mmc/card/block.c for that performance improvement. I guess it should live in block/cfq-iosched in the long run, but I don't know how easy it is to implement it there for test purposes. It may be easier to prototype it in the mmc code, since you are more familiar with that already, post that patch together with benchmark results and then do a new patch for the final solution. We'll need more benchmarking to figure out if that should be applied for all nonrotational storage, or if there are cases where it actually hurts performance to split requests on page boundaries. If it turns out to be a good idea in general, we won't even need a sysfs interface for enabling it, just one for reading/writing the underlying page size. > The other (Toshiba quirk) is obviously a quirk belonging to mmc/card/block.c. Makes sense. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-02-25 12:21 ` Arnd Bergmann 0 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-25 12:21 UTC (permalink / raw) To: linux-arm-kernel On Friday 25 February 2011, Andrei Warkentin wrote: > Yup. I understand :-). That's the strategy I'm going to follow. For > page_size-alignment/splitting I'm looking at the block layer now. Is > that the right approach or should I still submit a (cleaned up) patch > to mmc/card/block.c for that performance improvement. I guess it should live in block/cfq-iosched in the long run, but I don't know how easy it is to implement it there for test purposes. It may be easier to prototype it in the mmc code, since you are more familiar with that already, post that patch together with benchmark results and then do a new patch for the final solution. We'll need more benchmarking to figure out if that should be applied for all nonrotational storage, or if there are cases where it actually hurts performance to split requests on page boundaries. If it turns out to be a good idea in general, we won't even need a sysfs interface for enabling it, just one for reading/writing the underlying page size. > The other (Toshiba quirk) is obviously a quirk belonging to mmc/card/block.c. Makes sense. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-02-25 12:21 ` Arnd Bergmann @ 2011-03-01 18:48 ` Jens Axboe -1 siblings, 0 replies; 117+ messages in thread From: Jens Axboe @ 2011-03-01 18:48 UTC (permalink / raw) To: Arnd Bergmann Cc: Andrei Warkentin, linux-arm-kernel, linux-fsdevel, Linus Walleij, linux-mmc On 2011-02-25 07:21, Arnd Bergmann wrote: > On Friday 25 February 2011, Andrei Warkentin wrote: >> Yup. I understand :-). That's the strategy I'm going to follow. For >> page_size-alignment/splitting I'm looking at the block layer now. Is >> that the right approach or should I still submit a (cleaned up) patch >> to mmc/card/block.c for that performance improvement. > > I guess it should live in block/cfq-iosched in the long run, but I don't > know how easy it is to implement it there for test purposes. I don't think I saw the original patch(es) for this? -- Jens Axboe ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-03-01 18:48 ` Jens Axboe 0 siblings, 0 replies; 117+ messages in thread From: Jens Axboe @ 2011-03-01 18:48 UTC (permalink / raw) To: linux-arm-kernel On 2011-02-25 07:21, Arnd Bergmann wrote: > On Friday 25 February 2011, Andrei Warkentin wrote: >> Yup. I understand :-). That's the strategy I'm going to follow. For >> page_size-alignment/splitting I'm looking at the block layer now. Is >> that the right approach or should I still submit a (cleaned up) patch >> to mmc/card/block.c for that performance improvement. > > I guess it should live in block/cfq-iosched in the long run, but I don't > know how easy it is to implement it there for test purposes. I don't think I saw the original patch(es) for this? -- Jens Axboe ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-03-01 18:48 ` Jens Axboe @ 2011-03-01 19:11 ` Arnd Bergmann -1 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-03-01 19:11 UTC (permalink / raw) To: Jens Axboe Cc: Andrei Warkentin, linux-arm-kernel, linux-fsdevel, Linus Walleij, linux-mmc On Tuesday 01 March 2011 19:48:17 Jens Axboe wrote: > > On 2011-02-25 07:21, Arnd Bergmann wrote: > > On Friday 25 February 2011, Andrei Warkentin wrote: > >> Yup. I understand :-). That's the strategy I'm going to follow. For > >> page_size-alignment/splitting I'm looking at the block layer now. Is > >> that the right approach or should I still submit a (cleaned up) patch > >> to mmc/card/block.c for that performance improvement. > > > > I guess it should live in block/cfq-iosched in the long run, but I don't > > know how easy it is to implement it there for test purposes. > > I don't think I saw the original patch(es) for this? Nobody has posted one yet, only discussions. Andrei made a patch for the MMC block driver to split requests in some cases, but I think the concept has changed enough that it's probably not useful to look at that patch. I think what needs to be done here is to split requests in these cases: * Small requests should be split on flash page boundaries, where a page is typically 8 to 32 KB. Sending one hardware request that spans two partial pages can be slower than sending two requests with the same data, but on page boundaries. * If a hardware transfer is limited to a few sectors, these should be aligned to page boundaries. E.g. assuming a 16 sector page and 32 sector maximum transfers, a request that spans from sector 7 to 62 should be split into three transfers: 7-15, 16-47 and 48-62, not 7-38 and 39-62. This reduces the number of page read-modify-write cycles that the drive does. * No request should ever span multiple erase blocks. Most flash drives today have 4MB erase blocks (sometimes 1, 2 or 8), and the I/O scheduler should treat the erase block boundary like a seek on a hard drive. The I/O scheduler should try to send all sector writes of an erase block in sequence, but after that it can chose any other erase block to write to next. I think if we get this logic, we can deal well with all cheap flash drives. The two parameters we need are the page size and the erase block size, which the kernel can sometimes guess, but should also be tunable in sysfs for devices that don't tell us or lie to the kernel about them. I'm not sure if we want to do this for all nonrotational media, or add another flag to enable these optimizations. On proper SSDs that have an intelligent controller and enough RAM, they probably would not help all that much, or even make it slightly slower due to a higher number of separate write requests. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-03-01 19:11 ` Arnd Bergmann 0 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-03-01 19:11 UTC (permalink / raw) To: linux-arm-kernel On Tuesday 01 March 2011 19:48:17 Jens Axboe wrote: > > On 2011-02-25 07:21, Arnd Bergmann wrote: > > On Friday 25 February 2011, Andrei Warkentin wrote: > >> Yup. I understand :-). That's the strategy I'm going to follow. For > >> page_size-alignment/splitting I'm looking at the block layer now. Is > >> that the right approach or should I still submit a (cleaned up) patch > >> to mmc/card/block.c for that performance improvement. > > > > I guess it should live in block/cfq-iosched in the long run, but I don't > > know how easy it is to implement it there for test purposes. > > I don't think I saw the original patch(es) for this? Nobody has posted one yet, only discussions. Andrei made a patch for the MMC block driver to split requests in some cases, but I think the concept has changed enough that it's probably not useful to look at that patch. I think what needs to be done here is to split requests in these cases: * Small requests should be split on flash page boundaries, where a page is typically 8 to 32 KB. Sending one hardware request that spans two partial pages can be slower than sending two requests with the same data, but on page boundaries. * If a hardware transfer is limited to a few sectors, these should be aligned to page boundaries. E.g. assuming a 16 sector page and 32 sector maximum transfers, a request that spans from sector 7 to 62 should be split into three transfers: 7-15, 16-47 and 48-62, not 7-38 and 39-62. This reduces the number of page read-modify-write cycles that the drive does. * No request should ever span multiple erase blocks. Most flash drives today have 4MB erase blocks (sometimes 1, 2 or 8), and the I/O scheduler should treat the erase block boundary like a seek on a hard drive. The I/O scheduler should try to send all sector writes of an erase block in sequence, but after that it can chose any other erase block to write to next. I think if we get this logic, we can deal well with all cheap flash drives. The two parameters we need are the page size and the erase block size, which the kernel can sometimes guess, but should also be tunable in sysfs for devices that don't tell us or lie to the kernel about them. I'm not sure if we want to do this for all nonrotational media, or add another flag to enable these optimizations. On proper SSDs that have an intelligent controller and enough RAM, they probably would not help all that much, or even make it slightly slower due to a higher number of separate write requests. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-03-01 19:11 ` Arnd Bergmann @ 2011-03-01 19:15 ` Jens Axboe -1 siblings, 0 replies; 117+ messages in thread From: Jens Axboe @ 2011-03-01 19:15 UTC (permalink / raw) To: Arnd Bergmann Cc: Andrei Warkentin, linux-arm-kernel, linux-fsdevel, Linus Walleij, linux-mmc On 2011-03-01 14:11, Arnd Bergmann wrote: > On Tuesday 01 March 2011 19:48:17 Jens Axboe wrote: >> >> On 2011-02-25 07:21, Arnd Bergmann wrote: >>> On Friday 25 February 2011, Andrei Warkentin wrote: >>>> Yup. I understand :-). That's the strategy I'm going to follow. For >>>> page_size-alignment/splitting I'm looking at the block layer now. Is >>>> that the right approach or should I still submit a (cleaned up) patch >>>> to mmc/card/block.c for that performance improvement. >>> >>> I guess it should live in block/cfq-iosched in the long run, but I don't >>> know how easy it is to implement it there for test purposes. >> >> I don't think I saw the original patch(es) for this? > > Nobody has posted one yet, only discussions. Andrei made a patch for the > MMC block driver to split requests in some cases, but I think the > concept has changed enough that it's probably not useful to look at > that patch. > > I think what needs to be done here is to split requests in these cases: > > * Small requests should be split on flash page boundaries, where a page > is typically 8 to 32 KB. Sending one hardware request that spans two > partial pages can be slower than sending two requests with the same > data, but on page boundaries. > > * If a hardware transfer is limited to a few sectors, these should be > aligned to page boundaries. E.g. assuming a 16 sector page and 32 sector > maximum transfers, a request that spans from sector 7 to 62 should be > split into three transfers: 7-15, 16-47 and 48-62, not 7-38 and 39-62. > This reduces the number of page read-modify-write cycles that the drive > does. > > * No request should ever span multiple erase blocks. Most flash drives today > have 4MB erase blocks (sometimes 1, 2 or 8), and the I/O scheduler should > treat the erase block boundary like a seek on a hard drive. The I/O > scheduler should try to send all sector writes of an erase block in sequence, > but after that it can chose any other erase block to write to next. > > I think if we get this logic, we can deal well with all cheap flash drives. > The two parameters we need are the page size and the erase block size, > which the kernel can sometimes guess, but should also be tunable in > sysfs for devices that don't tell us or lie to the kernel about them. > > I'm not sure if we want to do this for all nonrotational media, or > add another flag to enable these optimizations. On proper SSDs that have > an intelligent controller and enough RAM, they probably would not help > all that much, or even make it slightly slower due to a higher number > of separate write requests. Thanks for the recap. One way to handle this would be to have a dm target that ensures that requests are never built up to violate any of the above items. Doing splitting is a little silly, when you can prevent it from happening in the first place. Alternatively, a queue ->merge_bvec_fn() with a settings table could provide the same. As this is of limited scope, I would prefer having this done via a plugin of some sort (like a dm target). -- Jens Axboe ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-03-01 19:15 ` Jens Axboe 0 siblings, 0 replies; 117+ messages in thread From: Jens Axboe @ 2011-03-01 19:15 UTC (permalink / raw) To: linux-arm-kernel On 2011-03-01 14:11, Arnd Bergmann wrote: > On Tuesday 01 March 2011 19:48:17 Jens Axboe wrote: >> >> On 2011-02-25 07:21, Arnd Bergmann wrote: >>> On Friday 25 February 2011, Andrei Warkentin wrote: >>>> Yup. I understand :-). That's the strategy I'm going to follow. For >>>> page_size-alignment/splitting I'm looking at the block layer now. Is >>>> that the right approach or should I still submit a (cleaned up) patch >>>> to mmc/card/block.c for that performance improvement. >>> >>> I guess it should live in block/cfq-iosched in the long run, but I don't >>> know how easy it is to implement it there for test purposes. >> >> I don't think I saw the original patch(es) for this? > > Nobody has posted one yet, only discussions. Andrei made a patch for the > MMC block driver to split requests in some cases, but I think the > concept has changed enough that it's probably not useful to look at > that patch. > > I think what needs to be done here is to split requests in these cases: > > * Small requests should be split on flash page boundaries, where a page > is typically 8 to 32 KB. Sending one hardware request that spans two > partial pages can be slower than sending two requests with the same > data, but on page boundaries. > > * If a hardware transfer is limited to a few sectors, these should be > aligned to page boundaries. E.g. assuming a 16 sector page and 32 sector > maximum transfers, a request that spans from sector 7 to 62 should be > split into three transfers: 7-15, 16-47 and 48-62, not 7-38 and 39-62. > This reduces the number of page read-modify-write cycles that the drive > does. > > * No request should ever span multiple erase blocks. Most flash drives today > have 4MB erase blocks (sometimes 1, 2 or 8), and the I/O scheduler should > treat the erase block boundary like a seek on a hard drive. The I/O > scheduler should try to send all sector writes of an erase block in sequence, > but after that it can chose any other erase block to write to next. > > I think if we get this logic, we can deal well with all cheap flash drives. > The two parameters we need are the page size and the erase block size, > which the kernel can sometimes guess, but should also be tunable in > sysfs for devices that don't tell us or lie to the kernel about them. > > I'm not sure if we want to do this for all nonrotational media, or > add another flag to enable these optimizations. On proper SSDs that have > an intelligent controller and enough RAM, they probably would not help > all that much, or even make it slightly slower due to a higher number > of separate write requests. Thanks for the recap. One way to handle this would be to have a dm target that ensures that requests are never built up to violate any of the above items. Doing splitting is a little silly, when you can prevent it from happening in the first place. Alternatively, a queue ->merge_bvec_fn() with a settings table could provide the same. As this is of limited scope, I would prefer having this done via a plugin of some sort (like a dm target). -- Jens Axboe ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-03-01 19:15 ` Jens Axboe @ 2011-03-01 19:51 ` Arnd Bergmann -1 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-03-01 19:51 UTC (permalink / raw) To: Jens Axboe Cc: Andrei Warkentin, linux-arm-kernel, linux-fsdevel, Linus Walleij, linux-mmc On Tuesday 01 March 2011 20:15:30 Jens Axboe wrote: > Thanks for the recap. One way to handle this would be to have a dm > target that ensures that requests are never built up to violate any of > the above items. Doing splitting is a little silly, when you can prevent > it from happening in the first place. Ok, that sounds good. I didn't know that it's possible to prevent bios from getting created that violate this. I'm actually trying to do a device mapper target that does much more than this, see https://wiki.linaro.org/WorkingGroups/KernelConsolidation/Projects/FlashDeviceMapper for an early draft. The design has moved on since I wrote that, but the basic idea is still the same: all blocks get written in a way that fills up entire 4MB segments before moving to another segment, independent of what the logical block numbers are, and a little space is used to store a lookup table for the logical-to-physical block mapping. > Alternatively, a queue ->merge_bvec_fn() with a settings table could > provide the same. That's probably better for the common case. The device mapper target would be useful for those that want the best case write performance, but if I understand you correctly, the merge_bvec_fn() could be used per block driver, so we could simply add that to the SCSI (for USB and consumer SSD) case and MMC block drivers. The point that this does not solve is submitting all outstanding writes for an erase block together, which is needed to reduce the garbage collection overhead. When you do a partial update of an erase block (4MB typically) and then start writing to another erase block, the drive will have to copy all data you did not write in order to free up internal resources. > As this is of limited scope, I would prefer having this done via a > plugin of some sort (like a dm target). I'm not sure what you mean with limited scope. This is certainly not as important for the classic server environment (aside from USB boot drives), but I assume that it is highly relevant for the a large portion of new embedded designs as people move from raw flash to eMMC and similar "technologies". Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-03-01 19:51 ` Arnd Bergmann 0 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-03-01 19:51 UTC (permalink / raw) To: linux-arm-kernel On Tuesday 01 March 2011 20:15:30 Jens Axboe wrote: > Thanks for the recap. One way to handle this would be to have a dm > target that ensures that requests are never built up to violate any of > the above items. Doing splitting is a little silly, when you can prevent > it from happening in the first place. Ok, that sounds good. I didn't know that it's possible to prevent bios from getting created that violate this. I'm actually trying to do a device mapper target that does much more than this, see https://wiki.linaro.org/WorkingGroups/KernelConsolidation/Projects/FlashDeviceMapper for an early draft. The design has moved on since I wrote that, but the basic idea is still the same: all blocks get written in a way that fills up entire 4MB segments before moving to another segment, independent of what the logical block numbers are, and a little space is used to store a lookup table for the logical-to-physical block mapping. > Alternatively, a queue ->merge_bvec_fn() with a settings table could > provide the same. That's probably better for the common case. The device mapper target would be useful for those that want the best case write performance, but if I understand you correctly, the merge_bvec_fn() could be used per block driver, so we could simply add that to the SCSI (for USB and consumer SSD) case and MMC block drivers. The point that this does not solve is submitting all outstanding writes for an erase block together, which is needed to reduce the garbage collection overhead. When you do a partial update of an erase block (4MB typically) and then start writing to another erase block, the drive will have to copy all data you did not write in order to free up internal resources. > As this is of limited scope, I would prefer having this done via a > plugin of some sort (like a dm target). I'm not sure what you mean with limited scope. This is certainly not as important for the classic server environment (aside from USB boot drives), but I assume that it is highly relevant for the a large portion of new embedded designs as people move from raw flash to eMMC and similar "technologies". Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-03-01 19:51 ` Arnd Bergmann @ 2011-03-01 21:33 ` Andrei Warkentin -1 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-03-01 21:33 UTC (permalink / raw) To: Arnd Bergmann Cc: Jens Axboe, linux-arm-kernel, linux-fsdevel, Linus Walleij, linux-mmc On Tue, Mar 1, 2011 at 1:51 PM, Arnd Bergmann <arnd@arndb.de> wrote: > On Tuesday 01 March 2011 20:15:30 Jens Axboe wrote: >> Thanks for the recap. One way to handle this would be to have a dm >> target that ensures that requests are never built up to violate any of >> the above items. Doing splitting is a little silly, when you can prevent >> it from happening in the first place. > > Ok, that sounds good. I didn't know that it's possible to prevent > bios from getting created that violate this. > Wouldn't someone still be able to perform a generic_make_request that would violate the conditions (i.e. cross alignment boundary while performing unaligned write)? You could prevent the merges that would result in violating the conditions, sure, but you would need to handle single unaligned accesses correctly too... Sorry, I'm just groping my way around the block layer...a lot I'm still trying to draw a mental picture for. P.S. I've submitted for review the first 3 patches. Tear into them :). A ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-03-01 21:33 ` Andrei Warkentin 0 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-03-01 21:33 UTC (permalink / raw) To: linux-arm-kernel On Tue, Mar 1, 2011 at 1:51 PM, Arnd Bergmann <arnd@arndb.de> wrote: > On Tuesday 01 March 2011 20:15:30 Jens Axboe wrote: >> Thanks for the recap. One way to handle this would be to have a dm >> target that ensures that requests are never built up to violate any of >> the above items. Doing splitting is a little silly, when you can prevent >> it from happening in the first place. > > Ok, that sounds good. I didn't know that it's possible to prevent > bios from getting created that violate this. > Wouldn't someone still be able to perform a generic_make_request that would violate the conditions (i.e. cross alignment boundary while performing unaligned write)? You could prevent the merges that would result in violating the conditions, sure, but you would need to handle single unaligned accesses correctly too... Sorry, I'm just groping my way around the block layer...a lot I'm still trying to draw a mental picture for. P.S. I've submitted for review the first 3 patches. Tear into them :). A ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-03-01 19:11 ` Arnd Bergmann @ 2011-03-02 10:34 ` Andrei Warkentin -1 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-03-02 10:34 UTC (permalink / raw) To: Arnd Bergmann Cc: Jens Axboe, linux-arm-kernel, linux-fsdevel, Linus Walleij, linux-mmc On Tue, Mar 1, 2011 at 1:11 PM, Arnd Bergmann <arnd@arndb.de> wrote: > On Tuesday 01 March 2011 19:48:17 Jens Axboe wrote: >> >> On 2011-02-25 07:21, Arnd Bergmann wrote: >> > On Friday 25 February 2011, Andrei Warkentin wrote: >> >> Yup. I understand :-). That's the strategy I'm going to follow. For >> >> page_size-alignment/splitting I'm looking at the block layer now. Is >> >> that the right approach or should I still submit a (cleaned up) patch >> >> to mmc/card/block.c for that performance improvement. >> > >> > I guess it should live in block/cfq-iosched in the long run, but I don't >> > know how easy it is to implement it there for test purposes. >> >> I don't think I saw the original patch(es) for this? > > Nobody has posted one yet, only discussions. Andrei made a patch for the > MMC block driver to split requests in some cases, but I think the > concept has changed enough that it's probably not useful to look at > that patch. > Before the generic improvements are made to the block layer, I think there is some value in implementing the (simpler) ones in mmc block code, as well as expose an mmc block quirk interface by which its easy to add complex workarounds. Some things will never be able to completely stay above mmc block code, for example, when splitting up smaller accesses, you need to be careful on the Toshiba card, since the 4th consecutive 8KB block results in the entire 32KB getting pushed into the bigger 4MB buffer. On our platform, there are a lot of accesses in the 16KB-32KB range which benefit from the splitting. Data collected showed splitting more than 32KB to have adverse effect on performance (I guess that sort of makes sense, after all, why else would the controller treat 4 consecutive 8KB accesses as a larger access and treat it accordingly?) On the other hand, that data was collected on code that used reliable write for every portion of the split access, so I'm going to have to get some new data... -- To unsubscribe from this list: send the line "unsubscribe linux-fsdevel" in the body of a message to majordomo@vger.kernel.org More majordomo info at http://vger.kernel.org/majordomo-info.html ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-03-02 10:34 ` Andrei Warkentin 0 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-03-02 10:34 UTC (permalink / raw) To: linux-arm-kernel On Tue, Mar 1, 2011 at 1:11 PM, Arnd Bergmann <arnd@arndb.de> wrote: > On Tuesday 01 March 2011 19:48:17 Jens Axboe wrote: >> >> On 2011-02-25 07:21, Arnd Bergmann wrote: >> > On Friday 25 February 2011, Andrei Warkentin wrote: >> >> Yup. I understand :-). ?That's the strategy I'm going to follow. For >> >> page_size-alignment/splitting I'm looking at the block layer now. Is >> >> that the right approach or should I still submit a (cleaned up) patch >> >> to mmc/card/block.c for that performance improvement. >> > >> > I guess it should live in block/cfq-iosched in the long run, but I don't >> > know how easy it is to implement it there for test purposes. >> >> I don't think I saw the original patch(es) for this? > > Nobody has posted one yet, only discussions. Andrei made a patch for the > MMC block driver to split requests in some cases, but I think the > concept has changed enough that it's probably not useful to look at > that patch. > Before the generic improvements are made to the block layer, I think there is some value in implementing the (simpler) ones in mmc block code, as well as expose an mmc block quirk interface by which its easy to add complex workarounds. Some things will never be able to completely stay above mmc block code, for example, when splitting up smaller accesses, you need to be careful on the Toshiba card, since the 4th consecutive 8KB block results in the entire 32KB getting pushed into the bigger 4MB buffer. On our platform, there are a lot of accesses in the 16KB-32KB range which benefit from the splitting. Data collected showed splitting more than 32KB to have adverse effect on performance (I guess that sort of makes sense, after all, why else would the controller treat 4 consecutive 8KB accesses as a larger access and treat it accordingly?) On the other hand, that data was collected on code that used reliable write for every portion of the split access, so I'm going to have to get some new data... ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-03-02 10:34 ` Andrei Warkentin @ 2011-03-05 9:23 ` Andrei Warkentin -1 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-03-05 9:23 UTC (permalink / raw) To: Arnd Bergmann Cc: Jens Axboe, linux-arm-kernel, linux-fsdevel, Linus Walleij, linux-mmc On Wed, Mar 2, 2011 at 4:34 AM, Andrei Warkentin <andreiw@motorola.com> wrote: > Before the generic improvements are made to the block layer, I think > there is some value > in implementing the (simpler) ones in mmc block code, as well as > expose an mmc block quirk interface by which its easy to add complex > workarounds. Some things will never be able to completely stay above > mmc block code, for example, when splitting up smaller accesses, you > need to be careful on the Toshiba card, since the 4th consecutive 8KB > block results in the entire 32KB getting pushed into the bigger 4MB > buffer. On our platform, there are a lot of accesses in the 16KB-32KB > range which benefit from the splitting. Data collected showed > splitting more than 32KB to have adverse effect on performance (I > guess that sort of makes sense, after all, why else would the > controller treat 4 consecutive 8KB accesses as a larger access and > treat it accordingly?) On the other hand, that data was collected on > code that used reliable write for every portion of the split access, > so I'm going to have to get some new data... > Just want to correct myself - any consecutive write that exceeds 8K goes into the 4MB buffer. Also, according to vendor, there is no performance penalty for using reliable write. This is why in the patch set, for splitting larger requests (to improve lifetime by reducing the number of AU write/erase cycles) I perform a reliable write for each split block set. ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-03-05 9:23 ` Andrei Warkentin 0 siblings, 0 replies; 117+ messages in thread From: Andrei Warkentin @ 2011-03-05 9:23 UTC (permalink / raw) To: linux-arm-kernel On Wed, Mar 2, 2011 at 4:34 AM, Andrei Warkentin <andreiw@motorola.com> wrote: > Before the generic improvements are made to the block layer, I think > there is some value > in implementing the (simpler) ones in mmc block code, as well as > expose an mmc block quirk interface by which its easy to add complex > workarounds. Some things will never be able to completely stay above > mmc block code, for example, when splitting up smaller accesses, you > need to be careful on the Toshiba card, since the 4th consecutive 8KB > block results in the entire 32KB getting pushed ?into the bigger 4MB > buffer. On our platform, there are a lot of accesses in the 16KB-32KB > range which benefit from the splitting. Data collected showed > splitting more than 32KB to have adverse effect on performance (I > guess that sort of makes sense, after all, why else would the > controller treat 4 consecutive 8KB accesses as a larger access and > treat it accordingly?) On the other hand, that data was collected on > code that used reliable write for every portion of the split access, > so I'm going to have to get some new data... > Just want to correct myself - any consecutive write that exceeds 8K goes into the 4MB buffer. Also, according to vendor, there is no performance penalty for using reliable write. This is why in the patch set, for splitting larger requests (to improve lifetime by reducing the number of AU write/erase cycles) I perform a reliable write for each split block set. ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. 2011-02-08 21:22 MMC quirks relating to performance/lifetime Andrei Warkentin ` (2 preceding siblings ...) 2011-02-09 8:37 ` Linus Walleij @ 2011-02-11 14:41 ` Pavel Machek 2011-02-11 14:51 ` Arnd Bergmann 3 siblings, 1 reply; 117+ messages in thread From: Pavel Machek @ 2011-02-11 14:41 UTC (permalink / raw) To: linux-arm-kernel Hi! > I'm not sure if this is the best place to bring this up, but Russel's > name is on a fair share of drivers/mmc code, and there does seem to be > quite a bit of MMC-related discussions. Excuse me in advance if this > isn't the right forum :-). > > Certain MMC vendors (maybe even quite a bit of them) use a pretty > rigid buffering scheme when it comes to handling writes. There is > usually a buffer A for random accesses, and a buffer B for sequential > accesses. For certain Toshiba parts, it looks like buffer A is 8KB > wide, with buffer B being 4MB wide, and all accesses larger than 8KB > effectively equating to 4MB accesses. Worse, consecutive small (8k) > writes are treated as one large sequential access, once again ending > up in buffer B, thus necessitating out-of-order writing to work around > this. Hmmmm, I somehow assumed MMCs would be much more cleverr than this. > reorders) them? The thresholds would then be adjustable as > module/kernel parameters based on manfid. I'm asking because I have a > patch now, but its ugly and hardcoded against a specific manufacturer. How big is performance difference? Pavel -- (english) http://www.livejournal.com/~pavelmachek (cesky, pictures) http://atrey.karlin.mff.cuni.cz/~pavel/picture/horses/blog.html ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. 2011-02-11 14:41 ` Pavel Machek @ 2011-02-11 14:51 ` Arnd Bergmann 2011-02-11 15:20 ` Lei Wen 2011-03-08 6:59 ` Pavel Machek 0 siblings, 2 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-11 14:51 UTC (permalink / raw) To: linux-arm-kernel On Friday 11 February 2011, Pavel Machek wrote: > Hi! > > > I'm not sure if this is the best place to bring this up, but Russel's > > name is on a fair share of drivers/mmc code, and there does seem to be > > quite a bit of MMC-related discussions. Excuse me in advance if this > > isn't the right forum :-). > > > > Certain MMC vendors (maybe even quite a bit of them) use a pretty > > rigid buffering scheme when it comes to handling writes. There is > > usually a buffer A for random accesses, and a buffer B for sequential > > accesses. For certain Toshiba parts, it looks like buffer A is 8KB > > wide, with buffer B being 4MB wide, and all accesses larger than 8KB > > effectively equating to 4MB accesses. Worse, consecutive small (8k) > > writes are treated as one large sequential access, once again ending > > up in buffer B, thus necessitating out-of-order writing to work around > > this. > > Hmmmm, I somehow assumed MMCs would be much more cleverr than this. No, these devices are incredibly stupid, or extremely optimized to a specific use case (writing large video files to FAT32), depending on how you look at them. > > reorders) them? The thresholds would then be adjustable as > > module/kernel parameters based on manfid. I'm asking because I have a > > patch now, but its ugly and hardcoded against a specific manufacturer. > > How big is performance difference? Several orders of magnitude. It is very easy to get a card that can write 12 MB/s into a case where it writes no more than 30 KB/s, doing only things that happen frequently with ext3. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. 2011-02-11 14:51 ` Arnd Bergmann @ 2011-02-11 15:20 ` Lei Wen 2011-02-11 15:25 ` Arnd Bergmann 2011-03-08 6:59 ` Pavel Machek 1 sibling, 1 reply; 117+ messages in thread From: Lei Wen @ 2011-02-11 15:20 UTC (permalink / raw) To: linux-arm-kernel On Fri, Feb 11, 2011 at 10:51 PM, Arnd Bergmann <arnd@arndb.de> wrote: > On Friday 11 February 2011, Pavel Machek wrote: >> Hi! >> >> > I'm not sure if this is the best place to bring this up, but Russel's >> > name is on a fair share of drivers/mmc code, and there does seem to be >> > quite a bit of MMC-related discussions. Excuse me in advance if this >> > isn't the right forum :-). >> > >> > Certain MMC vendors (maybe even quite a bit of them) use a pretty >> > rigid buffering scheme when it comes to handling writes. There is >> > usually a buffer A for random accesses, and a buffer B for sequential >> > accesses. For certain Toshiba parts, it looks like buffer A is 8KB >> > wide, with buffer B being 4MB wide, and all accesses larger than 8KB >> > effectively equating to 4MB accesses. Worse, consecutive small (8k) >> > writes are treated as one large sequential access, once again ending >> > up in buffer B, thus necessitating out-of-order writing to work around >> > this. >> >> Hmmmm, I somehow assumed MMCs would be much more cleverr than this. > > No, these devices are incredibly stupid, or extremely optimized to > a specific use case (writing large video files to FAT32), depending on how > you look at them. > >> > reorders) them? The thresholds would then be adjustable as >> > module/kernel parameters based on manfid. I'm asking because I have a >> > patch now, but its ugly and hardcoded against a specific manufacturer. >> >> How big is performance difference? > > Several orders of magnitude. It is very easy to get a card that can write > 12 MB/s into a case where it writes no more than 30 KB/s, doing only > things that happen frequently with ext3. > Maybe we could get that case into mmc_test code, so that we could track that in latter whether it already be fixed or not? Or in other word, to prove the firmware in sd card is stupid or not. :) Best regards, Lei ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. 2011-02-11 15:20 ` Lei Wen @ 2011-02-11 15:25 ` Arnd Bergmann 0 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-02-11 15:25 UTC (permalink / raw) To: linux-arm-kernel On Friday 11 February 2011, Lei Wen wrote: > > Several orders of magnitude. It is very easy to get a card that can write > > 12 MB/s into a case where it writes no more than 30 KB/s, doing only > > things that happen frequently with ext3. > > > > Maybe we could get that case into mmc_test code, so that we could track > that in latter whether it already be fixed or not? Or in other word, to prove > the firmware in sd card is stupid or not. :) There are many kinds of stupid, and a lot of cards are. I've actually had excellent success with simply measuring from user space, which is much easier than in mmc_test. Unfortunately, you have to write to the card to do that, which may destroy the data even if you write the same data that is already on it. See https://wiki.linaro.org/WorkingGroups/KernelConsolidation/Projects/FlashCardSurvey for most of my results. I'm about to write up a better paper with all the measurements, and will make my tools available soon. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. 2011-02-11 14:51 ` Arnd Bergmann 2011-02-11 15:20 ` Lei Wen @ 2011-03-08 6:59 ` Pavel Machek 2011-03-08 14:03 ` Arnd Bergmann 1 sibling, 1 reply; 117+ messages in thread From: Pavel Machek @ 2011-03-08 6:59 UTC (permalink / raw) To: linux-arm-kernel Hi! > > > I'm not sure if this is the best place to bring this up, but Russel's > > > name is on a fair share of drivers/mmc code, and there does seem to be > > > quite a bit of MMC-related discussions. Excuse me in advance if this > > > isn't the right forum :-). > > > > > > Certain MMC vendors (maybe even quite a bit of them) use a pretty > > > rigid buffering scheme when it comes to handling writes. There is > > > usually a buffer A for random accesses, and a buffer B for sequential > > > accesses. For certain Toshiba parts, it looks like buffer A is 8KB > > > wide, with buffer B being 4MB wide, and all accesses larger than 8KB > > > effectively equating to 4MB accesses. Worse, consecutive small (8k) > > > writes are treated as one large sequential access, once again ending > > > up in buffer B, thus necessitating out-of-order writing to work around > > > this. > > > > Hmmmm, I somehow assumed MMCs would be much more cleverr than this. > > No, these devices are incredibly stupid, or extremely optimized to > a specific use case (writing large video files to FAT32), depending on how > you look at them. > > > > reorders) them? The thresholds would then be adjustable as > > > module/kernel parameters based on manfid. I'm asking because I have a > > > patch now, but its ugly and hardcoded against a specific manufacturer. > > > > How big is performance difference? > > Several orders of magnitude. It is very easy to get a card that can write > 12 MB/s into a case where it writes no more than 30 KB/s, doing only > things that happen frequently with ext3. Ungood. I guess we should create something like loopback device, which knows about flash specifics, and does the right coalescing so that card stays in the fast mode? ...or, do we need to create new, simple filesystem with layout similar to fat32, for use on mmc cards? Pavel -- (english) http://www.livejournal.com/~pavelmachek (cesky, pictures) http://atrey.karlin.mff.cuni.cz/~pavel/picture/horses/blog.html ^ permalink raw reply [flat|nested] 117+ messages in thread
* Re: MMC quirks relating to performance/lifetime. 2011-03-08 6:59 ` Pavel Machek @ 2011-03-08 14:03 ` Arnd Bergmann 0 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-03-08 14:03 UTC (permalink / raw) To: Pavel Machek; +Cc: linux-arm-kernel, Andrei Warkentin, linux-fsdevel, linux-mmc On Tuesday 08 March 2011, Pavel Machek wrote: > > > > > > How big is performance difference? > > > > Several orders of magnitude. It is very easy to get a card that can write > > 12 MB/s into a case where it writes no more than 30 KB/s, doing only > > things that happen frequently with ext3. > > Ungood. > > I guess we should create something like loopback device, which knows > about flash specifics, and does the right coalescing so that card > stays in the fast mode? I have listed a few suggestions for areas to work in my article at https://lwn.net/Articles/428584/. My idea was to use a device mapper target, as described in https://wiki.linaro.org/WorkingGroups/KernelConsolidation/Projects/FlashDeviceMapper but a loopback device might work as well. The other area that I think will help a lot is to make the I/O scheduler aware of the erase block size and the preferred access patterns. > ...or, do we need to create new, simple filesystem with layout similar > to fat32, for use on mmc cards? It doesn't need to be similar to fat32, but creating a new file system could fix this, too. Microsoft seems to have built ExFAT around cheap flash devices, though they don't document what that does exactly. I think we can do better than that, and I still want to find out how close nilfs2 and btrfs can actually get to the optimum. Note that it's not just MMC cards though, you get the exact same effects on some low-end SSDs (which are basically repackaged CF cards) and most USB sticks. The best USB sticks I have seen can hide some effects with a bit of caching, and they have a higher number of open segments than the cheap ones, but the basic problems are unchanged. The requirements for a good low-end flash optimized file system would be roughly: 1. Do all writes is chunks of 32 or 64 KB. If there is less data to write, fill the chunk with zeroes and clean up later, but don't write more data to the same chunk. 2. Start writing on a segment (e.g. 4 MB, configurable) boundary, then write that segment to the end using the chunks mentioned above. 3. Erase full segments using trim/erase/discard before writing to them, if supported by the drive. 4. Have a configurable number of segments open for writing, i.e. you have written blocks at the start of the segment but not filled the segment to the end. Typical hardware limitations are between 1 and 10 open segments. 5. Keep all metadata within a single 4 MB segment. Drives that cannot do random access within normal segments can do it in the area that holds the FAT. If 4 MB is not enough, the FAT area can be used as a journal or cache, for a larger metadata area that gets written less frequently. 6. Because of the requirement to erase 4 MB chunks at once, there needs to be garbage collection to free up space. The quality of the garbage collection algorithm directly relates to the performance on full file systems and/or the space overhead. 7. Some static wear levelling is required to increase the expected life of consumer devices that only do dynamic wear levelling, i.e. the segments that contain purely static data need to be written occasionally so they make it back into the wear leveling pool of the hardware. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
* MMC quirks relating to performance/lifetime. @ 2011-03-08 14:03 ` Arnd Bergmann 0 siblings, 0 replies; 117+ messages in thread From: Arnd Bergmann @ 2011-03-08 14:03 UTC (permalink / raw) To: linux-arm-kernel On Tuesday 08 March 2011, Pavel Machek wrote: > > > > > > How big is performance difference? > > > > Several orders of magnitude. It is very easy to get a card that can write > > 12 MB/s into a case where it writes no more than 30 KB/s, doing only > > things that happen frequently with ext3. > > Ungood. > > I guess we should create something like loopback device, which knows > about flash specifics, and does the right coalescing so that card > stays in the fast mode? I have listed a few suggestions for areas to work in my article at https://lwn.net/Articles/428584/. My idea was to use a device mapper target, as described in https://wiki.linaro.org/WorkingGroups/KernelConsolidation/Projects/FlashDeviceMapper but a loopback device might work as well. The other area that I think will help a lot is to make the I/O scheduler aware of the erase block size and the preferred access patterns. > ...or, do we need to create new, simple filesystem with layout similar > to fat32, for use on mmc cards? It doesn't need to be similar to fat32, but creating a new file system could fix this, too. Microsoft seems to have built ExFAT around cheap flash devices, though they don't document what that does exactly. I think we can do better than that, and I still want to find out how close nilfs2 and btrfs can actually get to the optimum. Note that it's not just MMC cards though, you get the exact same effects on some low-end SSDs (which are basically repackaged CF cards) and most USB sticks. The best USB sticks I have seen can hide some effects with a bit of caching, and they have a higher number of open segments than the cheap ones, but the basic problems are unchanged. The requirements for a good low-end flash optimized file system would be roughly: 1. Do all writes is chunks of 32 or 64 KB. If there is less data to write, fill the chunk with zeroes and clean up later, but don't write more data to the same chunk. 2. Start writing on a segment (e.g. 4 MB, configurable) boundary, then write that segment to the end using the chunks mentioned above. 3. Erase full segments using trim/erase/discard before writing to them, if supported by the drive. 4. Have a configurable number of segments open for writing, i.e. you have written blocks at the start of the segment but not filled the segment to the end. Typical hardware limitations are between 1 and 10 open segments. 5. Keep all metadata within a single 4 MB segment. Drives that cannot do random access within normal segments can do it in the area that holds the FAT. If 4 MB is not enough, the FAT area can be used as a journal or cache, for a larger metadata area that gets written less frequently. 6. Because of the requirement to erase 4 MB chunks at once, there needs to be garbage collection to free up space. The quality of the garbage collection algorithm directly relates to the performance on full file systems and/or the space overhead. 7. Some static wear levelling is required to increase the expected life of consumer devices that only do dynamic wear levelling, i.e. the segments that contain purely static data need to be written occasionally so they make it back into the wear leveling pool of the hardware. Arnd ^ permalink raw reply [flat|nested] 117+ messages in thread
end of thread, other threads:[~2011-03-08 14:03 UTC | newest] Thread overview: 117+ messages (download: mbox.gz / follow: Atom feed) -- links below jump to the message on this page -- 2011-02-08 21:22 MMC quirks relating to performance/lifetime Andrei Warkentin 2011-02-08 21:38 ` Wolfram Sang 2011-02-08 21:38 ` Wolfram Sang 2011-02-08 22:42 ` Russell King - ARM Linux 2011-02-09 8:37 ` Linus Walleij 2011-02-09 8:37 ` Linus Walleij 2011-02-09 9:13 ` Arnd Bergmann 2011-02-09 9:13 ` Arnd Bergmann 2011-02-11 22:33 ` Andrei Warkentin 2011-02-11 22:33 ` Andrei Warkentin 2011-02-12 17:05 ` Arnd Bergmann 2011-02-12 17:05 ` Arnd Bergmann 2011-02-12 17:33 ` Andrei Warkentin 2011-02-12 17:33 ` Andrei Warkentin 2011-02-12 18:22 ` Arnd Bergmann 2011-02-12 18:22 ` Arnd Bergmann 2011-02-18 1:10 ` Andrei Warkentin 2011-02-18 1:10 ` Andrei Warkentin 2011-02-18 13:44 ` Arnd Bergmann 2011-02-18 13:44 ` Arnd Bergmann 2011-02-18 19:47 ` Andrei Warkentin 2011-02-18 19:47 ` Andrei Warkentin 2011-02-18 22:40 ` Andrei Warkentin 2011-02-18 22:40 ` Andrei Warkentin 2011-02-18 23:17 ` Andrei Warkentin 2011-02-18 23:17 ` Andrei Warkentin 2011-02-19 11:20 ` Arnd Bergmann 2011-02-19 11:20 ` Arnd Bergmann 2011-02-20 5:56 ` Andrei Warkentin 2011-02-20 5:56 ` Andrei Warkentin 2011-02-20 15:23 ` Arnd Bergmann 2011-02-20 15:23 ` Arnd Bergmann 2011-02-22 7:05 ` Andrei Warkentin 2011-02-22 7:05 ` Andrei Warkentin 2011-02-22 16:49 ` Arnd Bergmann 2011-02-22 16:49 ` Arnd Bergmann 2011-02-19 9:54 ` Arnd Bergmann 2011-02-19 9:54 ` Arnd Bergmann 2011-02-20 4:39 ` Andrei Warkentin 2011-02-20 4:39 ` Andrei Warkentin 2011-02-20 15:03 ` Arnd Bergmann 2011-02-20 15:03 ` Arnd Bergmann 2011-02-22 6:42 ` Andrei Warkentin 2011-02-22 6:42 ` Andrei Warkentin 2011-02-22 16:42 ` Arnd Bergmann 2011-02-22 16:42 ` Arnd Bergmann 2011-02-11 23:23 ` Linus Walleij 2011-02-11 23:23 ` Linus Walleij 2011-02-12 10:45 ` Arnd Bergmann 2011-02-12 10:45 ` Arnd Bergmann 2011-02-12 10:59 ` Russell King - ARM Linux 2011-02-12 10:59 ` Russell King - ARM Linux 2011-02-12 16:28 ` Arnd Bergmann 2011-02-12 16:28 ` Arnd Bergmann 2011-02-12 16:37 ` Russell King - ARM Linux 2011-02-12 16:37 ` Russell King - ARM Linux 2011-02-11 22:27 ` Andrei Warkentin 2011-02-11 22:27 ` Andrei Warkentin 2011-02-12 18:37 ` Arnd Bergmann 2011-02-12 18:37 ` Arnd Bergmann 2011-02-13 0:10 ` Andrei Warkentin 2011-02-13 0:10 ` Andrei Warkentin 2011-02-13 17:39 ` Arnd Bergmann 2011-02-13 17:39 ` Arnd Bergmann 2011-02-14 19:29 ` Andrei Warkentin 2011-02-14 19:29 ` Andrei Warkentin 2011-02-14 20:22 ` Arnd Bergmann 2011-02-14 20:22 ` Arnd Bergmann 2011-02-14 22:25 ` Andrei Warkentin 2011-02-14 22:25 ` Andrei Warkentin 2011-02-15 17:16 ` Arnd Bergmann 2011-02-15 17:16 ` Arnd Bergmann 2011-02-17 2:08 ` Andrei Warkentin 2011-02-17 2:08 ` Andrei Warkentin 2011-02-17 15:47 ` Arnd Bergmann 2011-02-17 15:47 ` Arnd Bergmann 2011-02-20 11:27 ` Andrei Warkentin 2011-02-20 11:27 ` Andrei Warkentin 2011-02-20 14:39 ` Arnd Bergmann 2011-02-20 14:39 ` Arnd Bergmann 2011-02-22 7:46 ` Andrei Warkentin 2011-02-22 7:46 ` Andrei Warkentin 2011-02-22 17:00 ` Arnd Bergmann 2011-02-22 17:00 ` Arnd Bergmann 2011-02-23 10:19 ` Andrei Warkentin 2011-02-23 10:19 ` Andrei Warkentin 2011-02-23 16:09 ` Arnd Bergmann 2011-02-23 16:09 ` Arnd Bergmann 2011-02-23 22:26 ` Andrei Warkentin 2011-02-23 22:26 ` Andrei Warkentin 2011-02-24 9:24 ` Arnd Bergmann 2011-02-24 9:24 ` Arnd Bergmann 2011-02-25 11:02 ` Andrei Warkentin 2011-02-25 11:02 ` Andrei Warkentin 2011-02-25 12:21 ` Arnd Bergmann 2011-02-25 12:21 ` Arnd Bergmann 2011-03-01 18:48 ` Jens Axboe 2011-03-01 18:48 ` Jens Axboe 2011-03-01 19:11 ` Arnd Bergmann 2011-03-01 19:11 ` Arnd Bergmann 2011-03-01 19:15 ` Jens Axboe 2011-03-01 19:15 ` Jens Axboe 2011-03-01 19:51 ` Arnd Bergmann 2011-03-01 19:51 ` Arnd Bergmann 2011-03-01 21:33 ` Andrei Warkentin 2011-03-01 21:33 ` Andrei Warkentin 2011-03-02 10:34 ` Andrei Warkentin 2011-03-02 10:34 ` Andrei Warkentin 2011-03-05 9:23 ` Andrei Warkentin 2011-03-05 9:23 ` Andrei Warkentin 2011-02-11 14:41 ` Pavel Machek 2011-02-11 14:51 ` Arnd Bergmann 2011-02-11 15:20 ` Lei Wen 2011-02-11 15:25 ` Arnd Bergmann 2011-03-08 6:59 ` Pavel Machek 2011-03-08 14:03 ` Arnd Bergmann 2011-03-08 14:03 ` Arnd Bergmann
This is an external index of several public inboxes, see mirroring instructions on how to clone and mirror all data and code used by this external index.
![[-- Attachment #2: scatter_8k_read_ts.png --] [-- Type: image/png, Size: 11238 bytes --]](../../AANLkTin0BVMgpjmeg682F7zcJJajRumLYcsgNriBwX2v@mail.gmail.com/2-scatter_8k_read_ts.png){kind=link}
![[-- Attachment #3: scatter_8k_sandisk.png --] [-- Type: image/png, Size: 8964 bytes --]](../../AANLkTin0BVMgpjmeg682F7zcJJajRumLYcsgNriBwX2v@mail.gmail.com/3-scatter_8k_sandisk.png){kind=link}
![[-- Attachment #4: scatter_16k_sandisk.png --] [-- Type: image/png, Size: 6853 bytes --]](../../AANLkTin0BVMgpjmeg682F7zcJJajRumLYcsgNriBwX2v@mail.gmail.com/4-scatter_16k_sandisk.png){kind=link}
![[-- Attachment #5: scatter_32k_read_ts.png --] [-- Type: image/png, Size: 9471 bytes --]](../../AANLkTin0BVMgpjmeg682F7zcJJajRumLYcsgNriBwX2v@mail.gmail.com/5-scatter_32k_read_ts.png){kind=link}
![[-- Attachment #6: scatter_32k_sandisk.png --] [-- Type: image/png, Size: 6790 bytes --]](../../AANLkTin0BVMgpjmeg682F7zcJJajRumLYcsgNriBwX2v@mail.gmail.com/6-scatter_32k_sandisk.png){kind=link}
![[-- Attachment #7: scatter_16k_read_ts.png --] [-- Type: image/png, Size: 9040 bytes --]](../../AANLkTin0BVMgpjmeg682F7zcJJajRumLYcsgNriBwX2v@mail.gmail.com/7-scatter_16k_read_ts.png){kind=link}
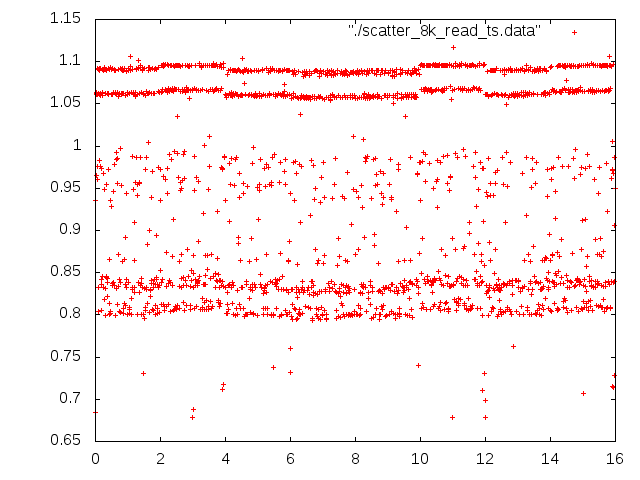{kind=link}
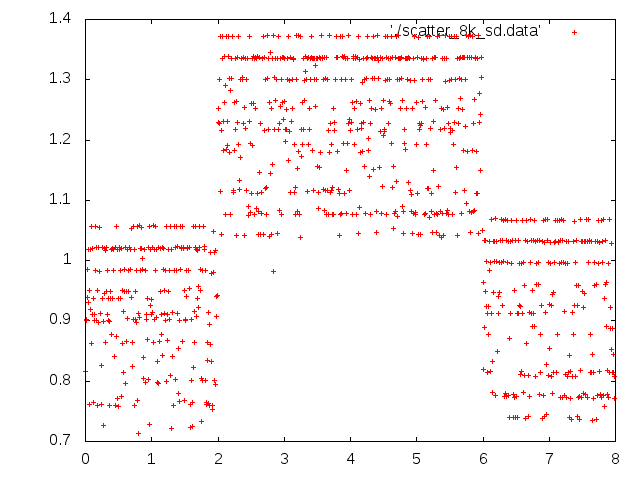{kind=link}
{kind=link}
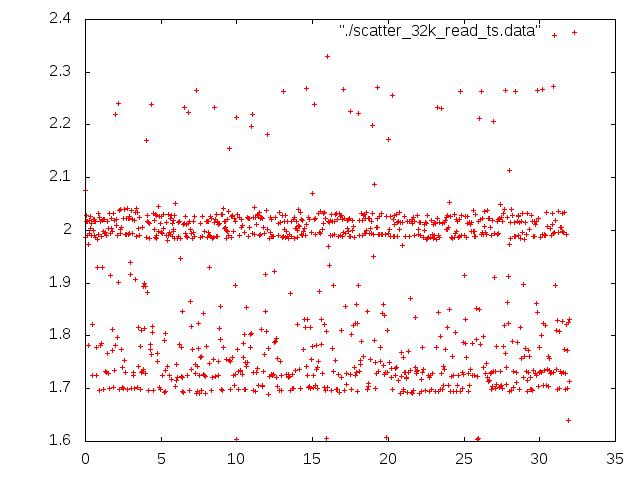{kind=link}
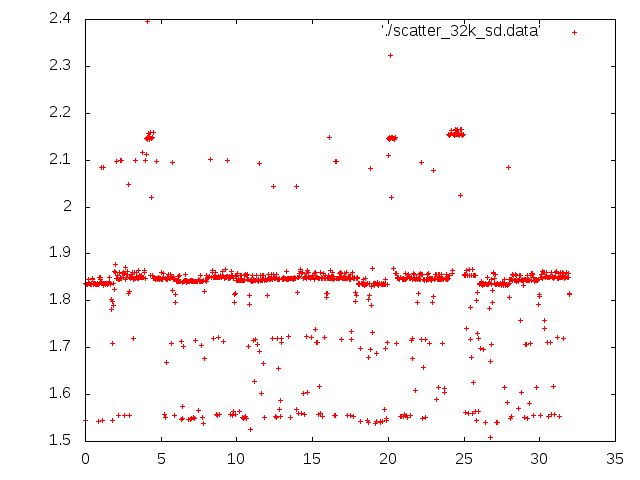{kind=link}
{kind=link}