* [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory
@ 2023-04-07 21:05 Dragan Stancevic
2023-04-07 22:23 ` James Houghton
` (6 more replies)
0 siblings, 7 replies; 40+ messages in thread
From: Dragan Stancevic @ 2023-04-07 21:05 UTC (permalink / raw)
To: lsf-pc; +Cc: nil-migration, linux-cxl, linux-mm
Hi folks-
if it's not too late for the schedule...
I am starting to tackle VM live migration and hypervisor clustering over
switched CXL memory[1][2], intended for cloud virtualization types of loads.
I'd be interested in doing a small BoF session with some slides and get
into a discussion/brainstorming with other people that deal with VM/LM
cloud loads. Among other things to discuss would be page migrations over
switched CXL memory, shared in-memory ABI to allow VM hand-off between
hypervisors, etc...
A few of us discussed some of this under the ZONE_XMEM thread, but I
figured it might be better to start a separate thread.
If there is interested, thank you.
[1]. High-level overview available at http://nil-migration.org/
[2]. Based on CXL spec 3.0
--
Peace can only come as a natural consequence
of universal enlightenment -Dr. Nikola Tesla
^ permalink raw reply [flat|nested] 40+ messages in thread* Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-07 21:05 [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory Dragan Stancevic @ 2023-04-07 22:23 ` James Houghton 2023-04-07 23:17 ` David Rientjes 2023-04-08 0:05 ` Gregory Price ` (5 subsequent siblings) 6 siblings, 1 reply; 40+ messages in thread From: James Houghton @ 2023-04-07 22:23 UTC (permalink / raw) To: Dragan Stancevic Cc: lsf-pc, nil-migration, linux-cxl, linux-mm, David Rientjes On Fri, Apr 7, 2023 at 5:05 PM Dragan Stancevic <dragan@stancevic.com> wrote: > > Hi folks- > > if it's not too late for the schedule... > > I am starting to tackle VM live migration and hypervisor clustering over > switched CXL memory[1][2], intended for cloud virtualization types of loads. > > I'd be interested in doing a small BoF session with some slides and get > into a discussion/brainstorming with other people that deal with VM/LM > cloud loads. Among other things to discuss would be page migrations over > switched CXL memory, shared in-memory ABI to allow VM hand-off between > hypervisors, etc... > > A few of us discussed some of this under the ZONE_XMEM thread, but I > figured it might be better to start a separate thread. > > If there is interested, thank you. Hi Dragan, Thanks for bringing up this topic. I'd be very interested to be part of this BoF, as I'm also interested in using CXL.mem as a live migration mechanism. - James > > > [1]. High-level overview available at http://nil-migration.org/ > [2]. Based on CXL spec 3.0 > > -- > Peace can only come as a natural consequence > of universal enlightenment -Dr. Nikola Tesla > ^ permalink raw reply [flat|nested] 40+ messages in thread
* Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-07 22:23 ` James Houghton @ 2023-04-07 23:17 ` David Rientjes 2023-04-08 1:33 ` Dragan Stancevic 2023-04-08 16:24 ` Dragan Stancevic 0 siblings, 2 replies; 40+ messages in thread From: David Rientjes @ 2023-04-07 23:17 UTC (permalink / raw) To: James Houghton, Dragan Stancevic Cc: lsf-pc, nil-migration, linux-cxl, linux-mm [-- Attachment #1: Type: text/plain, Size: 1460 bytes --] On Fri, 7 Apr 2023, James Houghton wrote: > On Fri, Apr 7, 2023 at 5:05 PM Dragan Stancevic <dragan@stancevic.com> wrote: > > > > Hi folks- > > > > if it's not too late for the schedule... > > > > I am starting to tackle VM live migration and hypervisor clustering over > > switched CXL memory[1][2], intended for cloud virtualization types of loads. > > > > I'd be interested in doing a small BoF session with some slides and get > > into a discussion/brainstorming with other people that deal with VM/LM > > cloud loads. Among other things to discuss would be page migrations over > > switched CXL memory, shared in-memory ABI to allow VM hand-off between > > hypervisors, etc... > > > > A few of us discussed some of this under the ZONE_XMEM thread, but I > > figured it might be better to start a separate thread. > > > > If there is interested, thank you. > > Hi Dragan, > > Thanks for bringing up this topic. I'd be very interested to be part > of this BoF, as I'm also interested in using CXL.mem as a live > migration mechanism. > Thanks for cc'ing me, this would be very interesting to talk about. Count me in! > > [1]. High-level overview available at http://nil-migration.org/ > > [2]. Based on CXL spec 3.0 > > Dragan: I'm curious about the reference to CXL spec 3.0 here, is there something specific about 3.0 that this work depends on or should we be good-to-go with 2.0 as well? (Are you referring to 3.0 for security extensions?) ^ permalink raw reply [flat|nested] 40+ messages in thread
* Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-07 23:17 ` David Rientjes @ 2023-04-08 1:33 ` Dragan Stancevic 2023-04-08 16:24 ` Dragan Stancevic 1 sibling, 0 replies; 40+ messages in thread From: Dragan Stancevic @ 2023-04-08 1:33 UTC (permalink / raw) To: David Rientjes, James Houghton; +Cc: lsf-pc, nil-migration, linux-cxl, linux-mm Hi David- On 4/7/23 18:17, David Rientjes wrote: > On Fri, 7 Apr 2023, James Houghton wrote: > >> On Fri, Apr 7, 2023 at 5:05 PM Dragan Stancevic <dragan@stancevic.com> wrote: >>> >>> Hi folks- >>> >>> if it's not too late for the schedule... >>> >>> I am starting to tackle VM live migration and hypervisor clustering over >>> switched CXL memory[1][2], intended for cloud virtualization types of loads. >>> >>> I'd be interested in doing a small BoF session with some slides and get >>> into a discussion/brainstorming with other people that deal with VM/LM >>> cloud loads. Among other things to discuss would be page migrations over >>> switched CXL memory, shared in-memory ABI to allow VM hand-off between >>> hypervisors, etc... >>> >>> A few of us discussed some of this under the ZONE_XMEM thread, but I >>> figured it might be better to start a separate thread. >>> >>> If there is interested, thank you. >> >> Hi Dragan, >> >> Thanks for bringing up this topic. I'd be very interested to be part >> of this BoF, as I'm also interested in using CXL.mem as a live >> migration mechanism. >> > > Thanks for cc'ing me, this would be very interesting to talk about. Count > me in! > >>> [1]. High-level overview available at http://nil-migration.org/ >>> [2]. Based on CXL spec 3.0 >>> > > Dragan: I'm curious about the reference to CXL spec 3.0 here, is there > something specific about 3.0 that this work depends on or should we be > good-to-go with 2.0 as well? (Are you referring to 3.0 for security > extensions?) I'm referencing 3.0 with regards to switched/shared memory as defined in Compute Express Link Specification r3.0, v1.0 8/1/22, Page 51, figure 1-4, black color scheme circle(3) and bars. It may be possible to do it with 2.0 but as far as I understand[1] the 2.0 spec it might be a lot more involved/clunky. I think new 3.0 features make it easier [1]. I would love to read 2.0 spec, but I don't have access to 2.0 spec(only 3.0). But that is my understanding from speaking with some CXL folks at last years plumbers when I floated this idea with them. -- Peace can only come as a natural consequence of universal enlightenment -Dr. Nikola Tesla ^ permalink raw reply [flat|nested] 40+ messages in thread
* Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-07 23:17 ` David Rientjes 2023-04-08 1:33 ` Dragan Stancevic @ 2023-04-08 16:24 ` Dragan Stancevic 1 sibling, 0 replies; 40+ messages in thread From: Dragan Stancevic @ 2023-04-08 16:24 UTC (permalink / raw) To: David Rientjes, James Houghton; +Cc: lsf-pc, nil-migration, linux-cxl, linux-mm Hi David- On 4/7/23 18:17, David Rientjes wrote: > On Fri, 7 Apr 2023, James Houghton wrote: > >> On Fri, Apr 7, 2023 at 5:05 PM Dragan Stancevic <dragan@stancevic.com> wrote: >>> >>> Hi folks- >>> >>> if it's not too late for the schedule... >>> >>> I am starting to tackle VM live migration and hypervisor clustering over >>> switched CXL memory[1][2], intended for cloud virtualization types of loads. >>> >>> I'd be interested in doing a small BoF session with some slides and get >>> into a discussion/brainstorming with other people that deal with VM/LM >>> cloud loads. Among other things to discuss would be page migrations over >>> switched CXL memory, shared in-memory ABI to allow VM hand-off between >>> hypervisors, etc... >>> >>> A few of us discussed some of this under the ZONE_XMEM thread, but I >>> figured it might be better to start a separate thread. >>> >>> If there is interested, thank you. >> >> Hi Dragan, >> >> Thanks for bringing up this topic. I'd be very interested to be part >> of this BoF, as I'm also interested in using CXL.mem as a live >> migration mechanism. >> > > Thanks for cc'ing me, this would be very interesting to talk about. Count > me in! > >>> [1]. High-level overview available at http://nil-migration.org/ >>> [2]. Based on CXL spec 3.0 >>> > > Dragan: I'm curious about the reference to CXL spec 3.0 here, is there > something specific about 3.0 that this work depends on or should we be > good-to-go with 2.0 as well? (Are you referring to 3.0 for security > extensions?) Sorry hit send too soon, and then had hosting provider issues... the hypervisor clustering part[1] might not work on CXL 2.0 [1]. http://nil-migration.org/ds-nil-migration-p12.png -- Peace can only come as a natural consequence of universal enlightenment -Dr. Nikola Tesla ^ permalink raw reply [flat|nested] 40+ messages in thread
* Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-07 21:05 [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory Dragan Stancevic 2023-04-07 22:23 ` James Houghton @ 2023-04-08 0:05 ` Gregory Price 2023-04-11 0:56 ` Dragan Stancevic 2023-04-11 6:37 ` [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory Huang, Ying 2023-04-09 17:40 ` Shreyas Shah ` (4 subsequent siblings) 6 siblings, 2 replies; 40+ messages in thread From: Gregory Price @ 2023-04-08 0:05 UTC (permalink / raw) To: Dragan Stancevic; +Cc: lsf-pc, nil-migration, linux-cxl, linux-mm On Fri, Apr 07, 2023 at 04:05:31PM -0500, Dragan Stancevic wrote: > Hi folks- > > if it's not too late for the schedule... > > I am starting to tackle VM live migration and hypervisor clustering over > switched CXL memory[1][2], intended for cloud virtualization types of loads. > > I'd be interested in doing a small BoF session with some slides and get into > a discussion/brainstorming with other people that deal with VM/LM cloud > loads. Among other things to discuss would be page migrations over switched > CXL memory, shared in-memory ABI to allow VM hand-off between hypervisors, > etc... > > A few of us discussed some of this under the ZONE_XMEM thread, but I figured > it might be better to start a separate thread. > > If there is interested, thank you. > > > [1]. High-level overview available at http://nil-migration.org/ > [2]. Based on CXL spec 3.0 > > -- > Peace can only come as a natural consequence > of universal enlightenment -Dr. Nikola Tesla I've been chatting about this with folks offline, figure i'll toss my thoughts on the issue here. Some things to consider: 1. If secure-compute is being used, then this mechanism won't work as pages will be pinned, and therefore not movable and excluded from using cxl memory at all. This issue does not exist with traditional live migration, because typically some kind of copy is used from one virtual space to another (i.e. RMDA), so pages aren't really migrated in the kernel memory block/numa node sense. 2. During the migration process, the memory needs to be forced not to be migrated to another node by other means (tiering software, swap, etc). The obvious way of doing this would be to migrate and temporarily pin the page... but going back to problem #1 we see that ZONE_MOVABLE and Pinning are mutually exclusive. So that's troublesome. 3. This is changing the semantics of migration from a virtual memory movement to a physical memory movement. Typically you would expect the RDMA process for live migration to work something like... a) migration request arrives b) source host informs destination host of size requirements c) destination host allocations memory and passes a Virtual Address back to source host d) source host initates an RDMA from HostA-VA to HostB-VA e) CPU task is migrated Importantly, the allocation of memory by Host B handles the important step of creating HVA->HPA mappings, and the Extended/Nested Page Tables can simply be flushed and re-created after the VM is fully migrated. to long didn't read: live migration is a virtual address operation, and node-migration is a PHYSICAL address operation, the virtual addresses remain the same. This is problematic, as it's changing the underlying semantics of the migration operation. Problem #1 and #2 are head-scratchers, but maybe solvable. Problem #3 is the meat and potatos of the issue in my opinion. So lets consider that a little more closely. Generically: NIL Migration is basically a pass by reference operation. The reference in this case is... the page tables. You need to know how to interpret the data in the CXL memory region on the remote host, and that's a "relative page table translation" (to coin a phrase? I'm not sure how to best describe it). That's... complicated to say the least. 1) Pages on the physical hardware do not need to be contiguous 2) The CFMW on source and target host do not need to be mapped at the same place 3) There's not pre-allocation in these charts, and migration isn't targeted, so having the source-host "expertly place" the data isn't possible (right now, i suppose you could make kernel extensions). 4) Similar to problem #2 above, even with a pre-allocate added in, you would need to ensure those mappings were pinned during migration, lest the target host end up swapping a page or something. An Option: Make pages physically contiguous on migration to CXL In this case, you don't necessarily care about the Host Virtual Addresses, what you actually care about are the structure of the pages in memory (are they physically contiguous? or do you need to reconstruct the contiguity by inspecting the page tables?). If a migration API were capable of reserving large swaths of contiguous CXL memory, you could discard individual page information and instead send page range information, reconstructing the virtual-physical mappings this way. That's about as far as I've thought about it so far. Feel free to rip it apart! :] ~Gregory ^ permalink raw reply [flat|nested] 40+ messages in thread
* Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-08 0:05 ` Gregory Price @ 2023-04-11 0:56 ` Dragan Stancevic 2023-04-11 1:48 ` Gregory Price 2023-04-11 6:37 ` [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory Huang, Ying 1 sibling, 1 reply; 40+ messages in thread From: Dragan Stancevic @ 2023-04-11 0:56 UTC (permalink / raw) To: Gregory Price; +Cc: lsf-pc, nil-migration, linux-cxl, linux-mm Hi Gregory- On 4/7/23 19:05, Gregory Price wrote: > On Fri, Apr 07, 2023 at 04:05:31PM -0500, Dragan Stancevic wrote: >> Hi folks- >> >> if it's not too late for the schedule... >> >> I am starting to tackle VM live migration and hypervisor clustering over >> switched CXL memory[1][2], intended for cloud virtualization types of loads. >> >> I'd be interested in doing a small BoF session with some slides and get into >> a discussion/brainstorming with other people that deal with VM/LM cloud >> loads. Among other things to discuss would be page migrations over switched >> CXL memory, shared in-memory ABI to allow VM hand-off between hypervisors, >> etc... >> >> A few of us discussed some of this under the ZONE_XMEM thread, but I figured >> it might be better to start a separate thread. >> >> If there is interested, thank you. >> >> >> [1]. High-level overview available at http://nil-migration.org/ >> [2]. Based on CXL spec 3.0 >> >> -- >> Peace can only come as a natural consequence >> of universal enlightenment -Dr. Nikola Tesla > > I've been chatting about this with folks offline, figure i'll toss my > thoughts on the issue here. excellent brain dump, thank you > Some things to consider: > > 1. If secure-compute is being used, then this mechanism won't work as > pages will be pinned, and therefore not movable and excluded from > using cxl memory at all. > > This issue does not exist with traditional live migration, because > typically some kind of copy is used from one virtual space to another > (i.e. RMDA), so pages aren't really migrated in the kernel memory > block/numa node sense. right, agreed... I don't think we can migrate in all scenarios, such as pinning or forms of pass-through, etc my opinion just to start off, as a base requirement, would be that the pages be movable. > 2. During the migration process, the memory needs to be forced not to be > migrated to another node by other means (tiering software, swap, > etc). The obvious way of doing this would be to migrate and > temporarily pin the page... but going back to problem #1 we see that > ZONE_MOVABLE and Pinning are mutually exclusive. So that's > troublesome. Yeah, true. I'd have to check the code, but I wonder if perhaps we could mapcount or refount the pages upon migration onto CLX switched memory. If my memory serves me right, wouldn't the move_pages back off or stall? I guess it's TBD, how workable or useful that would be but it's good to be thinking of different ways of doing this > 3. This is changing the semantics of migration from a virtual memory > movement to a physical memory movement. Typically you would expect > the RDMA process for live migration to work something like... > > a) migration request arrives > b) source host informs destination host of size requirements > c) destination host allocations memory and passes a Virtual Address > back to source host > d) source host initates an RDMA from HostA-VA to HostB-VA > e) CPU task is migrated > > Importantly, the allocation of memory by Host B handles the important > step of creating HVA->HPA mappings, and the Extended/Nested Page > Tables can simply be flushed and re-created after the VM is fully > migrated. > > to long didn't read: live migration is a virtual address operation, > and node-migration is a PHYSICAL address operation, the virtual > addresses remain the same. > > This is problematic, as it's changing the underlying semantics of the > migration operation. Those are all valid points, but what if you don't need to recreate HVA->HPA mappings? If I am understanding the CXL 3.0 spec correctly, then both virtual addresses and physical addresses wouldn't have to change. Because the fabric "virtualizes" host physical addresses and the translation is done by the G-FAM/GFD that has the capability to translate multi-host HPAs to it's internal DPAs. So if you have two hypervisors seeing device physical address as the same physical address, that might work? > Problem #1 and #2 are head-scratchers, but maybe solvable. > > Problem #3 is the meat and potatos of the issue in my opinion. So lets > consider that a little more closely. > > Generically: NIL Migration is basically a pass by reference operation. Yup, agreed > The reference in this case is... the page tables. You need to know how > to interpret the data in the CXL memory region on the remote host, and > that's a "relative page table translation" (to coin a phrase? I'm not > sure how to best describe it). right, coining phrases... I have been thinking of a "super-page" (for the lack of a better word) a metadata region sitting on the switched CXL.mem device that would allow hypervisors to synchronize on various aspects, such as "relative page table translation", host is up, host is down, list of peers, who owns what etc... In a perfect scenario, I would love to see the hypervisors cooperating on switched CXL.mem device the same way cpus on different numa nodes cooperate on memory in a single hypervisor. If either host can allocate and schedule from this space then "NIL" aspect of migration is "free". > That's... complicated to say the least. > 1) Pages on the physical hardware do not need to be contiguous > 2) The CFMW on source and target host do not need to be mapped at the > same place > 3) There's not pre-allocation in these charts, and migration isn't > targeted, so having the source-host "expertly place" the data isn't > possible (right now, i suppose you could make kernel extensions). > 4) Similar to problem #2 above, even with a pre-allocate added in, you > would need to ensure those mappings were pinned during migration, > lest the target host end up swapping a page or something. > > > > An Option: Make pages physically contiguous on migration to CXL > > In this case, you don't necessarily care about the Host Virtual > Addresses, what you actually care about are the structure of the pages > in memory (are they physically contiguous? or do you need to > reconstruct the contiguity by inspecting the page tables?). > > If a migration API were capable of reserving large swaths of contiguous > CXL memory, you could discard individual page information and instead > send page range information, reconstructing the virtual-physical > mappings this way. yeah, good points, but this is all tricky though... it seems this would require quiescing the VM and that is something I would like to avoid if possible. I'd like to see the VM still executing while all of it's pages are migrated onto CXL NUMA on the source hypervisor. And I would like to see the VM executing on the destination hypervisor while migrate_pages is moving pages off of CXL. Of course, what you are describing above would still be a very fast VM migration, but would require quiescing. > That's about as far as I've thought about it so far. Feel free to rip > it apart! :] Those are all great thoughts and I appreciate you sharing them. I don't have all the answers either :) > ~Gregory > -- Peace can only come as a natural consequence of universal enlightenment -Dr. Nikola Tesla ^ permalink raw reply [flat|nested] 40+ messages in thread
* Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-11 0:56 ` Dragan Stancevic @ 2023-04-11 1:48 ` Gregory Price 2023-04-14 3:32 ` Dragan Stancevic 0 siblings, 1 reply; 40+ messages in thread From: Gregory Price @ 2023-04-11 1:48 UTC (permalink / raw) To: Dragan Stancevic; +Cc: lsf-pc, nil-migration, linux-cxl, linux-mm On Mon, Apr 10, 2023 at 07:56:01PM -0500, Dragan Stancevic wrote: > Hi Gregory- > > On 4/7/23 19:05, Gregory Price wrote: > > 3. This is changing the semantics of migration from a virtual memory > > movement to a physical memory movement. Typically you would expect > > the RDMA process for live migration to work something like... > > > > a) migration request arrives > > b) source host informs destination host of size requirements > > c) destination host allocations memory and passes a Virtual Address > > back to source host > > d) source host initates an RDMA from HostA-VA to HostB-VA > > e) CPU task is migrated > > > > Importantly, the allocation of memory by Host B handles the important > > step of creating HVA->HPA mappings, and the Extended/Nested Page > > Tables can simply be flushed and re-created after the VM is fully > > migrated. > > > > to long didn't read: live migration is a virtual address operation, > > and node-migration is a PHYSICAL address operation, the virtual > > addresses remain the same. > > > > This is problematic, as it's changing the underlying semantics of the > > migration operation. > > Those are all valid points, but what if you don't need to recreate HVA->HPA > mappings? If I am understanding the CXL 3.0 spec correctly, then both > virtual addresses and physical addresses wouldn't have to change. Because > the fabric "virtualizes" host physical addresses and the translation is done > by the G-FAM/GFD that has the capability to translate multi-host HPAs to > it's internal DPAs. So if you have two hypervisors seeing device physical > address as the same physical address, that might work? > > Hm. I hadn't considered the device side translation (decoders), though that's obviously a tool in the toolbox. You still have to know how to slide ranges of data (which you mention below). > > > The reference in this case is... the page tables. You need to know how > > to interpret the data in the CXL memory region on the remote host, and > > that's a "relative page table translation" (to coin a phrase? I'm not > > sure how to best describe it). > > right, coining phrases... I have been thinking of a "super-page" (for the > lack of a better word) a metadata region sitting on the switched CXL.mem > device that would allow hypervisors to synchronize on various aspects, such > as "relative page table translation", host is up, host is down, list of > peers, who owns what etc... In a perfect scenario, I would love to see the > hypervisors cooperating on switched CXL.mem device the same way cpus on > different numa nodes cooperate on memory in a single hypervisor. If either > host can allocate and schedule from this space then "NIL" aspect of > migration is "free". > > The core of the problem is still that each of the hosts has to agree on the location (physically) of this region of memory, which could be problematic unless you have very strong BIOS and/or kernel driver controls to ensure certain devices are guaranteed to be mapped into certain spots in the CFMW. After that it's a matter of treating this memory as incoherent shared memory and handling ownership in a safe way. If the memory is only used for migrations, then you don't have to worry about performance. So I agree, as long as shared memory mapped into the same CFMW area is used, this mechanism is totally sound. My main concerns are that I don't know of a mechanism to ensure that. I suppose for those interested, and with special BIOS/EFI, you could do that - but I think that's going to be a tall ask in a heterogenous cloud environment. > > That's... complicated to say the least. > > > > <... snip ...> > > > > An Option: Make pages physically contiguous on migration to CXL > > > > In this case, you don't necessarily care about the Host Virtual > > Addresses, what you actually care about are the structure of the pages > > in memory (are they physically contiguous? or do you need to > > reconstruct the contiguity by inspecting the page tables?). > > > > If a migration API were capable of reserving large swaths of contiguous > > CXL memory, you could discard individual page information and instead > > send page range information, reconstructing the virtual-physical > > mappings this way. > > yeah, good points, but this is all tricky though... it seems this would > require quiescing the VM and that is something I would like to avoid if > possible. I'd like to see the VM still executing while all of it's pages are > migrated onto CXL NUMA on the source hypervisor. And I would like to see the > VM executing on the destination hypervisor while migrate_pages is moving > pages off of CXL. Of course, what you are describing above would still be a > very fast VM migration, but would require quiescing. > > Possibly. If you're going to quiesce you're probably better off just snapshotting to shared memory and migrating the snapshot. Maybe that's the better option for a first-pass migration mechanism. I don't know. Anyway, would love to attend this session. ~Gregory ^ permalink raw reply [flat|nested] 40+ messages in thread
* Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-11 1:48 ` Gregory Price @ 2023-04-14 3:32 ` Dragan Stancevic 2023-04-14 13:16 ` [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory Jonathan Cameron 0 siblings, 1 reply; 40+ messages in thread From: Dragan Stancevic @ 2023-04-14 3:32 UTC (permalink / raw) To: Gregory Price; +Cc: lsf-pc, nil-migration, linux-cxl, linux-mm Hi Gregory- On 4/10/23 20:48, Gregory Price wrote: > On Mon, Apr 10, 2023 at 07:56:01PM -0500, Dragan Stancevic wrote: >> Hi Gregory- >> >> On 4/7/23 19:05, Gregory Price wrote: >>> 3. This is changing the semantics of migration from a virtual memory >>> movement to a physical memory movement. Typically you would expect >>> the RDMA process for live migration to work something like... >>> >>> a) migration request arrives >>> b) source host informs destination host of size requirements >>> c) destination host allocations memory and passes a Virtual Address >>> back to source host >>> d) source host initates an RDMA from HostA-VA to HostB-VA >>> e) CPU task is migrated >>> >>> Importantly, the allocation of memory by Host B handles the important >>> step of creating HVA->HPA mappings, and the Extended/Nested Page >>> Tables can simply be flushed and re-created after the VM is fully >>> migrated. >>> >>> to long didn't read: live migration is a virtual address operation, >>> and node-migration is a PHYSICAL address operation, the virtual >>> addresses remain the same. >>> >>> This is problematic, as it's changing the underlying semantics of the >>> migration operation. >> >> Those are all valid points, but what if you don't need to recreate HVA->HPA >> mappings? If I am understanding the CXL 3.0 spec correctly, then both >> virtual addresses and physical addresses wouldn't have to change. Because >> the fabric "virtualizes" host physical addresses and the translation is done >> by the G-FAM/GFD that has the capability to translate multi-host HPAs to >> it's internal DPAs. So if you have two hypervisors seeing device physical >> address as the same physical address, that might work? >> >> > > Hm. I hadn't considered the device side translation (decoders), though > that's obviously a tool in the toolbox. You still have to know how to > slide ranges of data (which you mention below). Hmm, do you have any quick thoughts on that? >>> The reference in this case is... the page tables. You need to know how >>> to interpret the data in the CXL memory region on the remote host, and >>> that's a "relative page table translation" (to coin a phrase? I'm not >>> sure how to best describe it). >> >> right, coining phrases... I have been thinking of a "super-page" (for the >> lack of a better word) a metadata region sitting on the switched CXL.mem >> device that would allow hypervisors to synchronize on various aspects, such >> as "relative page table translation", host is up, host is down, list of >> peers, who owns what etc... In a perfect scenario, I would love to see the >> hypervisors cooperating on switched CXL.mem device the same way cpus on >> different numa nodes cooperate on memory in a single hypervisor. If either >> host can allocate and schedule from this space then "NIL" aspect of >> migration is "free". >> >> > > The core of the problem is still that each of the hosts has to agree on > the location (physically) of this region of memory, which could be > problematic unless you have very strong BIOS and/or kernel driver > controls to ensure certain devices are guaranteed to be mapped into > certain spots in the CFMW. Right, true. The way I am thinking of it is that this would be a part of data-center ops setup which at first pass would be a somewhat of a manual setup same way as other pre-OS related setup. But later on down the road perhaps this could be automated, either through some pre-agreed auto-ranges detection or similar, it's not unusual for dc ops to name hypervisors depending of where in dc/rack/etc they sit etc.. > After that it's a matter of treating this memory as incoherent shared > memory and handling ownership in a safe way. If the memory is only used > for migrations, then you don't have to worry about performance. > > So I agree, as long as shared memory mapped into the same CFMW area is > used, this mechanism is totally sound. > > My main concerns are that I don't know of a mechanism to ensure that. I > suppose for those interested, and with special BIOS/EFI, you could do > that - but I think that's going to be a tall ask in a heterogenous cloud > environment. Yeah, I get that. But in my experience even heterogeneous setups have some level of homogeneity, weather it's per rack, or per pod. As old things are sunset and new things are brought in, it gives you these segments of homogeneity with more or less advanced features. So at the end of the day, if someone wants a feature X they will need to understand the feature requirements or limitations. I feel like I deal with hardware/feature fragmentation all the time, but doesn't preclude bringing newer things in. You just have to plant it appropriately. >>> That's... complicated to say the least. >>> >>> <... snip ...> >>> >>> An Option: Make pages physically contiguous on migration to CXL >>> >>> In this case, you don't necessarily care about the Host Virtual >>> Addresses, what you actually care about are the structure of the pages >>> in memory (are they physically contiguous? or do you need to >>> reconstruct the contiguity by inspecting the page tables?). >>> >>> If a migration API were capable of reserving large swaths of contiguous >>> CXL memory, you could discard individual page information and instead >>> send page range information, reconstructing the virtual-physical >>> mappings this way. >> >> yeah, good points, but this is all tricky though... it seems this would >> require quiescing the VM and that is something I would like to avoid if >> possible. I'd like to see the VM still executing while all of it's pages are >> migrated onto CXL NUMA on the source hypervisor. And I would like to see the >> VM executing on the destination hypervisor while migrate_pages is moving >> pages off of CXL. Of course, what you are describing above would still be a >> very fast VM migration, but would require quiescing. >> >> > > Possibly. If you're going to quiesce you're probably better off just > snapshotting to shared memory and migrating the snapshot. That is exactly my thought too. > Maybe that's the better option for a first-pass migration mechanism. I > don't know. I definitely see your point, "canning" and "re-hydration" approach as a first-pass. I'd be happy with even just a "Hello World" page migration as a first pass :) > > Anyway, would love to attend this session. > > ~Gregory > -- -- Peace can only come as a natural consequence of universal enlightenment -Dr. Nikola Tesla ^ permalink raw reply [flat|nested] 40+ messages in thread
* Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-14 3:32 ` Dragan Stancevic @ 2023-04-14 13:16 ` Jonathan Cameron 0 siblings, 0 replies; 40+ messages in thread From: Jonathan Cameron @ 2023-04-14 13:16 UTC (permalink / raw) To: Dragan Stancevic Cc: Gregory Price, lsf-pc, nil-migration, linux-cxl, linux-mm On Thu, 13 Apr 2023 22:32:48 -0500 Dragan Stancevic <dragan@stancevic.com> wrote: > Hi Gregory- > > > On 4/10/23 20:48, Gregory Price wrote: > > On Mon, Apr 10, 2023 at 07:56:01PM -0500, Dragan Stancevic wrote: > >> Hi Gregory- > >> > >> On 4/7/23 19:05, Gregory Price wrote: > >>> 3. This is changing the semantics of migration from a virtual memory > >>> movement to a physical memory movement. Typically you would expect > >>> the RDMA process for live migration to work something like... > >>> > >>> a) migration request arrives > >>> b) source host informs destination host of size requirements > >>> c) destination host allocations memory and passes a Virtual Address > >>> back to source host > >>> d) source host initates an RDMA from HostA-VA to HostB-VA > >>> e) CPU task is migrated > >>> > >>> Importantly, the allocation of memory by Host B handles the important > >>> step of creating HVA->HPA mappings, and the Extended/Nested Page > >>> Tables can simply be flushed and re-created after the VM is fully > >>> migrated. > >>> > >>> to long didn't read: live migration is a virtual address operation, > >>> and node-migration is a PHYSICAL address operation, the virtual > >>> addresses remain the same. > >>> > >>> This is problematic, as it's changing the underlying semantics of the > >>> migration operation. > >> > >> Those are all valid points, but what if you don't need to recreate HVA->HPA > >> mappings? If I am understanding the CXL 3.0 spec correctly, then both > >> virtual addresses and physical addresses wouldn't have to change. That's implementation defined if we are talking DCD for this. I would suggest making it very clear which particular CXL options you are thinking of using. A CXL 2.0 approach of binding LDs to different switch vPPB (virtual ports) probably doesn't have this problem, but has it's own limitations and is a much heavier weight thing to handle. For DCD if we assuming sharing is used (I'd suggest ignoring other possibilities for now as there are architectural gaps that I'm not going into and the same issues will occur with them anyway)... Then what you get if you share on multiple LDs presented to multiple hosts is a set of extents (each is a base + size, any number any size) that have sequence numbers. The device may, typically because of fragmentation of the DPA space exposed to an LD (typically one of those from a device per host) decide to map what was created in a particular DPA extents pattern (mapped via nice linear decoders into Host PA space) in a different order and with different size extents. So in general you can't assume a spec compliant CXL type 3 device (probably a multihead device in initial deployments) will map anything to an particular location when moving the memory between hosts. So ultimately you'd need to translate between: Page tables on source + DPA extents info. and Page table needed on destination to land the parts of the DPA extents (via HDM deoders applying offsets etc) in the right place in GPA space so the guest gets the right mapping. So that will have some complexity and cost associated with it. Not impossible but not a simple reuse of tables from source on the destination. This is all PA to GPA translation though and in many cases I'd not expect that to be particularly dynamic - so it's a step before you do any actual migration hence I'm not sure it matters that might take a bit of maths. > Because > >> the fabric "virtualizes" host physical addresses and the translation is done > >> by the G-FAM/GFD that has the capability to translate multi-host HPAs to > >> it's internal DPAs. So if you have two hypervisors seeing device physical > >> address as the same physical address, that might work? > >> > >> > > > > Hm. I hadn't considered the device side translation (decoders), though > > that's obviously a tool in the toolbox. You still have to know how to > > slide ranges of data (which you mention below). > > Hmm, do you have any quick thoughts on that? HDM decoder programming is hard to do in a dynamic fashion (lots of limitations on what you can do due to ordering restrictions in the spec). I'd ignore it for this usecase beyond the fact that you get linear offsets from DPA to HPA that need to be incorporated in your thinking. > > > >>> The reference in this case is... the page tables. You need to know how > >>> to interpret the data in the CXL memory region on the remote host, and > >>> that's a "relative page table translation" (to coin a phrase? I'm not > >>> sure how to best describe it). > >> > >> right, coining phrases... I have been thinking of a "super-page" (for the > >> lack of a better word) a metadata region sitting on the switched CXL.mem > >> device that would allow hypervisors to synchronize on various aspects, such > >> as "relative page table translation", host is up, host is down, list of > >> peers, who owns what etc... In a perfect scenario, I would love to see the > >> hypervisors cooperating on switched CXL.mem device the same way cpus on > >> different numa nodes cooperate on memory in a single hypervisor. If either > >> host can allocate and schedule from this space then "NIL" aspect of > >> migration is "free". > >> > >> > > > > The core of the problem is still that each of the hosts has to agree on > > the location (physically) of this region of memory, which could be > > problematic unless you have very strong BIOS and/or kernel driver > > controls to ensure certain devices are guaranteed to be mapped into > > certain spots in the CFMW. > > Right, true. The way I am thinking of it is that this would be a part of > data-center ops setup which at first pass would be a somewhat of a > manual setup same way as other pre-OS related setup. But later on down > the road perhaps this could be automated, either through some pre-agreed > auto-ranges detection or similar, it's not unusual for dc ops to name > hypervisors depending of where in dc/rack/etc they sit etc.. > You might be able to constrain particular devices to place nicely with such a model, but that is out of the scope of the specification and I'd suggest in Linux at least we'd write the code to deal with the general case then maybe have a 'fast path' if the stars align. Jonathan ^ permalink raw reply [flat|nested] 40+ messages in thread
* Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-08 0:05 ` Gregory Price 2023-04-11 0:56 ` Dragan Stancevic @ 2023-04-11 6:37 ` Huang, Ying 2023-04-11 15:36 ` Gregory Price 2023-04-14 3:33 ` Dragan Stancevic 1 sibling, 2 replies; 40+ messages in thread From: Huang, Ying @ 2023-04-11 6:37 UTC (permalink / raw) To: Gregory Price Cc: Dragan Stancevic, lsf-pc, nil-migration, linux-cxl, linux-mm Gregory Price <gregory.price@memverge.com> writes: [snip] > 2. During the migration process, the memory needs to be forced not to be > migrated to another node by other means (tiering software, swap, > etc). The obvious way of doing this would be to migrate and > temporarily pin the page... but going back to problem #1 we see that > ZONE_MOVABLE and Pinning are mutually exclusive. So that's > troublesome. Can we use memory policy (cpusets, mbind(), set_mempolicy(), etc.) to avoid move pages out of CXL.mem node? Now, there are gaps in tiering, but I think it is fixable. Best Regards, Huang, Ying [snip] ^ permalink raw reply [flat|nested] 40+ messages in thread
* Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-11 6:37 ` [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory Huang, Ying @ 2023-04-11 15:36 ` Gregory Price 2023-04-12 2:54 ` Huang, Ying 2023-04-14 3:33 ` Dragan Stancevic 1 sibling, 1 reply; 40+ messages in thread From: Gregory Price @ 2023-04-11 15:36 UTC (permalink / raw) To: Huang, Ying; +Cc: Dragan Stancevic, lsf-pc, nil-migration, linux-cxl, linux-mm On Tue, Apr 11, 2023 at 02:37:50PM +0800, Huang, Ying wrote: > Gregory Price <gregory.price@memverge.com> writes: > > [snip] > > > 2. During the migration process, the memory needs to be forced not to be > > migrated to another node by other means (tiering software, swap, > > etc). The obvious way of doing this would be to migrate and > > temporarily pin the page... but going back to problem #1 we see that > > ZONE_MOVABLE and Pinning are mutually exclusive. So that's > > troublesome. > > Can we use memory policy (cpusets, mbind(), set_mempolicy(), etc.) to > avoid move pages out of CXL.mem node? Now, there are gaps in tiering, > but I think it is fixable. > > Best Regards, > Huang, Ying > > [snip] That feels like a hack/bodge rather than a proper solution to me. Maybe this is an affirmative argument for the creation of an EXMEM zone. Specifically to allow page pinning, but with far more stringent controls - i.e. the zone is excluded from use via general allocations. The point of ZONE_MOVABLE is to allow general allocation of userland data into hotpluggable memory regions. This memory region is not for general use, and wants to allow pinning and be hotpluggable under very controlled circumstances. That seems like a reasonable argument for the creation of EXMEM. ~Gregory ^ permalink raw reply [flat|nested] 40+ messages in thread
* Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-11 15:36 ` Gregory Price @ 2023-04-12 2:54 ` Huang, Ying 2023-04-12 8:38 ` David Hildenbrand 0 siblings, 1 reply; 40+ messages in thread From: Huang, Ying @ 2023-04-12 2:54 UTC (permalink / raw) To: Gregory Price Cc: Dragan Stancevic, lsf-pc, nil-migration, linux-cxl, linux-mm Gregory Price <gregory.price@memverge.com> writes: > On Tue, Apr 11, 2023 at 02:37:50PM +0800, Huang, Ying wrote: >> Gregory Price <gregory.price@memverge.com> writes: >> >> [snip] >> >> > 2. During the migration process, the memory needs to be forced not to be >> > migrated to another node by other means (tiering software, swap, >> > etc). The obvious way of doing this would be to migrate and >> > temporarily pin the page... but going back to problem #1 we see that >> > ZONE_MOVABLE and Pinning are mutually exclusive. So that's >> > troublesome. >> >> Can we use memory policy (cpusets, mbind(), set_mempolicy(), etc.) to >> avoid move pages out of CXL.mem node? Now, there are gaps in tiering, >> but I think it is fixable. >> >> Best Regards, >> Huang, Ying >> >> [snip] > > That feels like a hack/bodge rather than a proper solution to me. > > Maybe this is an affirmative argument for the creation of an EXMEM > zone. Let's start with requirements. What is the requirements for a new zone type? > Specifically to allow page pinning, but with far more stringent > controls - > i.e. the zone is excluded from use via general allocations. This can also be controlled via memory policy. The alternative solution is to add a per node attribute. > The point of ZONE_MOVABLE is to allow general allocation of userland > data into hotpluggable memory regions. IIUC, one typical requirement of CXL.mem is hotpluggable, right? Best Regards, Huang, Ying > This memory region is not for general use, and wants to allow pinning > and be hotpluggable under very controlled circumstances. That seems > like a reasonable argument for the creation of EXMEM. > > ~Gregory ^ permalink raw reply [flat|nested] 40+ messages in thread
* Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-12 2:54 ` Huang, Ying @ 2023-04-12 8:38 ` David Hildenbrand [not found] ` <CGME20230412111034epcas2p1b46d2a26b7d3ac5db3b0e454255527b0@epcas2p1.samsung.com> ` (2 more replies) 0 siblings, 3 replies; 40+ messages in thread From: David Hildenbrand @ 2023-04-12 8:38 UTC (permalink / raw) To: Huang, Ying, Gregory Price Cc: Dragan Stancevic, lsf-pc, nil-migration, linux-cxl, linux-mm On 12.04.23 04:54, Huang, Ying wrote: > Gregory Price <gregory.price@memverge.com> writes: > >> On Tue, Apr 11, 2023 at 02:37:50PM +0800, Huang, Ying wrote: >>> Gregory Price <gregory.price@memverge.com> writes: >>> >>> [snip] >>> >>>> 2. During the migration process, the memory needs to be forced not to be >>>> migrated to another node by other means (tiering software, swap, >>>> etc). The obvious way of doing this would be to migrate and >>>> temporarily pin the page... but going back to problem #1 we see that >>>> ZONE_MOVABLE and Pinning are mutually exclusive. So that's >>>> troublesome. >>> >>> Can we use memory policy (cpusets, mbind(), set_mempolicy(), etc.) to >>> avoid move pages out of CXL.mem node? Now, there are gaps in tiering, >>> but I think it is fixable. >>> >>> Best Regards, >>> Huang, Ying >>> >>> [snip] >> >> That feels like a hack/bodge rather than a proper solution to me. >> >> Maybe this is an affirmative argument for the creation of an EXMEM >> zone. > > Let's start with requirements. What is the requirements for a new zone > type? I'm stills scratching my head regarding this. I keep hearing all different kind of statements that just add more confusions "we want it to be hotunpluggable" "we want to allow for long-term pinning memory" "but we still want it to be movable" "we want to place some unmovable allocations on it". Huh? Just to clarify: ZONE_MOVABLE allows for pinning. It just doesn't allow for long-term pinning of memory. For good reason, because long-term pinning of memory is just the worst (memory waste, fragmentation, overcommit) and instead of finding new ways to *avoid* long-term pinnings, we're coming up with advanced concepts to work-around the fundamental property of long-term pinnings. We want all memory to be long-term pinnable and we want all memory to be movable/hotunpluggable. That's not going to work. If you'd ask me today, my prediction is that ZONE_EXMEM is not going to happen. -- Thanks, David / dhildenb ^ permalink raw reply [flat|nested] 40+ messages in thread
[parent not found: <CGME20230412111034epcas2p1b46d2a26b7d3ac5db3b0e454255527b0@epcas2p1.samsung.com>]
* RE: FW: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory [not found] ` <CGME20230412111034epcas2p1b46d2a26b7d3ac5db3b0e454255527b0@epcas2p1.samsung.com> @ 2023-04-12 11:10 ` Kyungsan Kim 2023-04-12 11:26 ` David Hildenbrand 2023-04-12 15:40 ` Matthew Wilcox 0 siblings, 2 replies; 40+ messages in thread From: Kyungsan Kim @ 2023-04-12 11:10 UTC (permalink / raw) To: david Cc: lsf-pc, linux-mm, linux-fsdevel, linux-cxl, a.manzanares, viacheslav.dubeyko, dan.j.williams, seungjun.ha, wj28.lee >> Gregory Price <gregory.price@memverge.com> writes: >> >>> On Tue, Apr 11, 2023 at 02:37:50PM +0800, Huang, Ying wrote: >>>> Gregory Price <gregory.price@memverge.com> writes: >>>> >>>> [snip] >>>> >>>>> 2. During the migration process, the memory needs to be forced not to be >>>>> migrated to another node by other means (tiering software, swap, >>>>> etc). The obvious way of doing this would be to migrate and >>>>> temporarily pin the page... but going back to problem #1 we see that >>>>> ZONE_MOVABLE and Pinning are mutually exclusive. So that's >>>>> troublesome. >>>> >>>> Can we use memory policy (cpusets, mbind(), set_mempolicy(), etc.) to >>>> avoid move pages out of CXL.mem node? Now, there are gaps in tiering, >>>> but I think it is fixable. >>>> >>>> Best Regards, >>>> Huang, Ying >>>> >>>> [snip] >>> >>> That feels like a hack/bodge rather than a proper solution to me. >>> >>> Maybe this is an affirmative argument for the creation of an EXMEM >>> zone. >> >> Let's start with requirements. What is the requirements for a new zone >> type? > >I'm stills scratching my head regarding this. I keep hearing all >different kind of statements that just add more confusions "we want it >to be hotunpluggable" "we want to allow for long-term pinning memory" >"but we still want it to be movable" "we want to place some unmovable >allocations on it". Huh? > >Just to clarify: ZONE_MOVABLE allows for pinning. It just doesn't allow >for long-term pinning of memory. > >For good reason, because long-term pinning of memory is just the worst >(memory waste, fragmentation, overcommit) and instead of finding new >ways to *avoid* long-term pinnings, we're coming up with advanced >concepts to work-around the fundamental property of long-term pinnings. > >We want all memory to be long-term pinnable and we want all memory to be >movable/hotunpluggable. That's not going to work. Looks there is misunderstanding about ZONE_EXMEM argument. Pinning and plubbability is mutual exclusive so it can not happen at the same time. What we argue is ZONE_EXMEM does not "confine movability". an allocation context can determine the movability attribute. Even one unmovable allocation will make the entire CXL DRAM unpluggable. When you see ZONE_EXMEM just on movable/unmoable aspect, we think it is the same with ZONE_NORMAL, but ZONE_EXMEM works on an extended memory, as of now CXL DRAM. Then why ZONE_EXMEM is, ZONE_EXMEM considers not only the pluggability aspect, but CXL identifier for user/kenelspace API, the abstraction of multiple CXL DRAM channels, and zone unit algorithm for CXL HW characteristics. The last one is potential at the moment, though. As mentioned in ZONE_EXMEM thread, we are preparing slides to explain experiences and proposals. It it not final version now[1]. [1] https://github.com/OpenMPDK/SMDK/wiki/93.-%5BLSF-MM-BPF-TOPIC%5D-SMDK-inspired-MM-changes-for-CXL >If you'd ask me today, my prediction is that ZONE_EXMEM is not going to >happen. > >-- >Thanks, > >David / dhildenb ^ permalink raw reply [flat|nested] 40+ messages in thread
* Re: FW: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-12 11:10 ` FW: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory Kyungsan Kim @ 2023-04-12 11:26 ` David Hildenbrand [not found] ` <CGME20230414084110epcas2p20b90a8d1892110d7ca3ac16290cd4686@epcas2p2.samsung.com> 2023-04-12 15:40 ` Matthew Wilcox 1 sibling, 1 reply; 40+ messages in thread From: David Hildenbrand @ 2023-04-12 11:26 UTC (permalink / raw) To: Kyungsan Kim Cc: lsf-pc, linux-mm, linux-fsdevel, linux-cxl, a.manzanares, viacheslav.dubeyko, dan.j.williams, seungjun.ha, wj28.lee On 12.04.23 13:10, Kyungsan Kim wrote: >>> Gregory Price <gregory.price@memverge.com> writes: >>> >>>> On Tue, Apr 11, 2023 at 02:37:50PM +0800, Huang, Ying wrote: >>>>> Gregory Price <gregory.price@memverge.com> writes: >>>>> >>>>> [snip] >>>>> >>>>>> 2. During the migration process, the memory needs to be forced not to be >>>>>> migrated to another node by other means (tiering software, swap, >>>>>> etc). The obvious way of doing this would be to migrate and >>>>>> temporarily pin the page... but going back to problem #1 we see that >>>>>> ZONE_MOVABLE and Pinning are mutually exclusive. So that's >>>>>> troublesome. >>>>> >>>>> Can we use memory policy (cpusets, mbind(), set_mempolicy(), etc.) to >>>>> avoid move pages out of CXL.mem node? Now, there are gaps in tiering, >>>>> but I think it is fixable. >>>>> >>>>> Best Regards, >>>>> Huang, Ying >>>>> >>>>> [snip] >>>> >>>> That feels like a hack/bodge rather than a proper solution to me. >>>> >>>> Maybe this is an affirmative argument for the creation of an EXMEM >>>> zone. >>> >>> Let's start with requirements. What is the requirements for a new zone >>> type? >> >> I'm stills scratching my head regarding this. I keep hearing all >> different kind of statements that just add more confusions "we want it >> to be hotunpluggable" "we want to allow for long-term pinning memory" >> "but we still want it to be movable" "we want to place some unmovable >> allocations on it". Huh? >> >> Just to clarify: ZONE_MOVABLE allows for pinning. It just doesn't allow >> for long-term pinning of memory. >> >> For good reason, because long-term pinning of memory is just the worst >> (memory waste, fragmentation, overcommit) and instead of finding new >> ways to *avoid* long-term pinnings, we're coming up with advanced >> concepts to work-around the fundamental property of long-term pinnings. >> >> We want all memory to be long-term pinnable and we want all memory to be >> movable/hotunpluggable. That's not going to work. > > Looks there is misunderstanding about ZONE_EXMEM argument. > Pinning and plubbability is mutual exclusive so it can not happen at the same time. > What we argue is ZONE_EXMEM does not "confine movability". an allocation context can determine the movability attribute. > Even one unmovable allocation will make the entire CXL DRAM unpluggable. > When you see ZONE_EXMEM just on movable/unmoable aspect, we think it is the same with ZONE_NORMAL, > but ZONE_EXMEM works on an extended memory, as of now CXL DRAM. > > Then why ZONE_EXMEM is, ZONE_EXMEM considers not only the pluggability aspect, but CXL identifier for user/kenelspace API, > the abstraction of multiple CXL DRAM channels, and zone unit algorithm for CXL HW characteristics. > The last one is potential at the moment, though. > > As mentioned in ZONE_EXMEM thread, we are preparing slides to explain experiences and proposals. > It it not final version now[1]. > [1] https://github.com/OpenMPDK/SMDK/wiki/93.-%5BLSF-MM-BPF-TOPIC%5D-SMDK-inspired-MM-changes-for-CXL Yes, hopefully we can discuss at LSF/MM also the problems we are trying to solve instead of focusing on one solution. [did not have the time to look at the slides yet, sorry] -- Thanks, David / dhildenb ^ permalink raw reply [flat|nested] 40+ messages in thread
[parent not found: <CGME20230414084110epcas2p20b90a8d1892110d7ca3ac16290cd4686@epcas2p2.samsung.com>]
* RE: FW: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory [not found] ` <CGME20230414084110epcas2p20b90a8d1892110d7ca3ac16290cd4686@epcas2p2.samsung.com> @ 2023-04-14 8:41 ` Kyungsan Kim 0 siblings, 0 replies; 40+ messages in thread From: Kyungsan Kim @ 2023-04-14 8:41 UTC (permalink / raw) To: david Cc: lsf-pc, linux-mm, linux-fsdevel, linux-cxl, a.manzanares, viacheslav.dubeyko, dan.j.williams, seungjun.ha, wj28.lee, hj96.nam >On 12.04.23 13:10, Kyungsan Kim wrote: >>>> Gregory Price <gregory.price@memverge.com> writes: >>>> >>>>> On Tue, Apr 11, 2023 at 02:37:50PM +0800, Huang, Ying wrote: >>>>>> Gregory Price <gregory.price@memverge.com> writes: >>>>>> >>>>>> [snip] >>>>>> >>>>>>> 2. During the migration process, the memory needs to be forced not to be >>>>>>> migrated to another node by other means (tiering software, swap, >>>>>>> etc). The obvious way of doing this would be to migrate and >>>>>>> temporarily pin the page... but going back to problem #1 we see that >>>>>>> ZONE_MOVABLE and Pinning are mutually exclusive. So that's >>>>>>> troublesome. >>>>>> >>>>>> Can we use memory policy (cpusets, mbind(), set_mempolicy(), etc.) to >>>>>> avoid move pages out of CXL.mem node? Now, there are gaps in tiering, >>>>>> but I think it is fixable. >>>>>> >>>>>> Best Regards, >>>>>> Huang, Ying >>>>>> >>>>>> [snip] >>>>> >>>>> That feels like a hack/bodge rather than a proper solution to me. >>>>> >>>>> Maybe this is an affirmative argument for the creation of an EXMEM >>>>> zone. >>>> >>>> Let's start with requirements. What is the requirements for a new zone >>>> type? >>> >>> I'm stills scratching my head regarding this. I keep hearing all >>> different kind of statements that just add more confusions "we want it >>> to be hotunpluggable" "we want to allow for long-term pinning memory" >>> "but we still want it to be movable" "we want to place some unmovable >>> allocations on it". Huh? >>> >>> Just to clarify: ZONE_MOVABLE allows for pinning. It just doesn't allow >>> for long-term pinning of memory. >>> >>> For good reason, because long-term pinning of memory is just the worst >>> (memory waste, fragmentation, overcommit) and instead of finding new >>> ways to *avoid* long-term pinnings, we're coming up with advanced >>> concepts to work-around the fundamental property of long-term pinnings. >>> >>> We want all memory to be long-term pinnable and we want all memory to be >>> movable/hotunpluggable. That's not going to work. >> >> Looks there is misunderstanding about ZONE_EXMEM argument. >> Pinning and plubbability is mutual exclusive so it can not happen at the same time. >> What we argue is ZONE_EXMEM does not "confine movability". an allocation context can determine the movability attribute. >> Even one unmovable allocation will make the entire CXL DRAM unpluggable. >> When you see ZONE_EXMEM just on movable/unmoable aspect, we think it is the same with ZONE_NORMAL, >> but ZONE_EXMEM works on an extended memory, as of now CXL DRAM. >> >> Then why ZONE_EXMEM is, ZONE_EXMEM considers not only the pluggability aspect, but CXL identifier for user/kenelspace API, >> the abstraction of multiple CXL DRAM channels, and zone unit algorithm for CXL HW characteristics. >> The last one is potential at the moment, though. >> >> As mentioned in ZONE_EXMEM thread, we are preparing slides to explain experiences and proposals. >> It it not final version now[1]. >> [1] https://protect2.fireeye.com/v1/url?k=265f4f76-47d45a59-265ec439-74fe485cbfe7-1e8ec1d2f0c2fd0a&q=1&e=727e97be-fc78-4fa6-990b-a86c256978d1&u=https%3A%2F%2Fgithub.com%2FOpenMPDK%2FSMDK%2Fwiki%2F93.-%255BLSF-MM-BPF-TOPIC%255D-SMDK-inspired-MM-changes-for-CXL > >Yes, hopefully we can discuss at LSF/MM also the problems we are trying >to solve instead of focusing on one solution. [did not have the time to >look at the slides yet, sorry] For sure.. The purpose of LSF/MM this year is weighted on sharing experiences and issues as CXL provider for last couple of years. We don't think our solution is the only way, but propose it. Hopefully, we gradually figure out the best way with experts here. > >-- >Thanks, > >David / dhildenb ^ permalink raw reply [flat|nested] 40+ messages in thread
* Re: FW: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-12 11:10 ` FW: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory Kyungsan Kim 2023-04-12 11:26 ` David Hildenbrand @ 2023-04-12 15:40 ` Matthew Wilcox [not found] ` <CGME20230414084114epcas2p4754d6c0d3c86a0d6d4e855058562100f@epcas2p4.samsung.com> 1 sibling, 1 reply; 40+ messages in thread From: Matthew Wilcox @ 2023-04-12 15:40 UTC (permalink / raw) To: Kyungsan Kim Cc: david, lsf-pc, linux-mm, linux-fsdevel, linux-cxl, a.manzanares, viacheslav.dubeyko, dan.j.williams, seungjun.ha, wj28.lee On Wed, Apr 12, 2023 at 08:10:33PM +0900, Kyungsan Kim wrote: > Pinning and plubbability is mutual exclusive so it can not happen at the same time. > What we argue is ZONE_EXMEM does not "confine movability". an allocation context can determine the movability attribute. > Even one unmovable allocation will make the entire CXL DRAM unpluggable. > When you see ZONE_EXMEM just on movable/unmoable aspect, we think it is the same with ZONE_NORMAL, > but ZONE_EXMEM works on an extended memory, as of now CXL DRAM. > > Then why ZONE_EXMEM is, ZONE_EXMEM considers not only the pluggability aspect, but CXL identifier for user/kenelspace API, > the abstraction of multiple CXL DRAM channels, and zone unit algorithm for CXL HW characteristics. > The last one is potential at the moment, though. > > As mentioned in ZONE_EXMEM thread, we are preparing slides to explain experiences and proposals. > It it not final version now[1]. > [1] https://github.com/OpenMPDK/SMDK/wiki/93.-%5BLSF-MM-BPF-TOPIC%5D-SMDK-inspired-MM-changes-for-CXL The problem is that you're starting out with a solution. Tell us what your requirements are, at a really high level, then walk us through why ZONE_EXMEM is the best way to satisfy those requirements. Also, those slides are terrible. Even at 200% zoom, the text is tiny. There is no MAP_NORMAL argument to mmap(), there are no GFP flags to sys_mmap() and calling mmap() does not typically cause alloc_page() to be called. I'm not sure that putting your thoughts onto slides is making them any better organised. ^ permalink raw reply [flat|nested] 40+ messages in thread
[parent not found: <CGME20230414084114epcas2p4754d6c0d3c86a0d6d4e855058562100f@epcas2p4.samsung.com>]
* RE: RE: FW: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory [not found] ` <CGME20230414084114epcas2p4754d6c0d3c86a0d6d4e855058562100f@epcas2p4.samsung.com> @ 2023-04-14 8:41 ` Kyungsan Kim 0 siblings, 0 replies; 40+ messages in thread From: Kyungsan Kim @ 2023-04-14 8:41 UTC (permalink / raw) To: willy Cc: lsf-pc, linux-mm, linux-fsdevel, linux-cxl, a.manzanares, viacheslav.dubeyko, dan.j.williams, seungjun.ha, wj28.lee, hj96.nam >On Wed, Apr 12, 2023 at 08:10:33PM +0900, Kyungsan Kim wrote: >> Pinning and plubbability is mutual exclusive so it can not happen at the same time. >> What we argue is ZONE_EXMEM does not "confine movability". an allocation context can determine the movability attribute. >> Even one unmovable allocation will make the entire CXL DRAM unpluggable. >> When you see ZONE_EXMEM just on movable/unmoable aspect, we think it is the same with ZONE_NORMAL, >> but ZONE_EXMEM works on an extended memory, as of now CXL DRAM. >> >> Then why ZONE_EXMEM is, ZONE_EXMEM considers not only the pluggability aspect, but CXL identifier for user/kenelspace API, >> the abstraction of multiple CXL DRAM channels, and zone unit algorithm for CXL HW characteristics. >> The last one is potential at the moment, though. >> >> As mentioned in ZONE_EXMEM thread, we are preparing slides to explain experiences and proposals. >> It it not final version now[1]. >> [1] https://github.com/OpenMPDK/SMDK/wiki/93.-%5BLSF-MM-BPF-TOPIC%5D-SMDK-inspired-MM-changes-for-CXL > >The problem is that you're starting out with a solution. Tell us what >your requirements are, at a really high level, then walk us through >why ZONE_EXMEM is the best way to satisfy those requirements. Thank you for your advice. It makes sense. We will restate requirements(usecases and issues) rather than our solution aspect. A sympathy about the requirements should come first at the moment. Hope we gradually reach up a consensus. >Also, those slides are terrible. Even at 200% zoom, the text is tiny. > >There is no MAP_NORMAL argument to mmap(), there are no GFP flags to >sys_mmap() and calling mmap() does not typically cause alloc_page() to >be called. I'm not sure that putting your thoughts onto slides is >making them any better organised. I'm sorry for your inconvenience. Explaining the version of document, the 1st slide shows SMDK kernel, not vanilla kernel. Especially, the slide is geared to highlight the flow of the new user/kernel API to implicitly/explicitly access DIMM DRAM or CXL DRAM to help understanding at previous discussion context. We added MAP_NORMAL/MAP_EXMEM on mmap()/sys_mmap(), GFP_EXMEM/GFP_NORMAL on alloc_pages(). If you mean COW, please assume the mmap() is called with MAP_POPULATE flag. We wanted to draw it simple to highlight the purpose. The document is not final version, we will apply your comment while preparing. ^ permalink raw reply [flat|nested] 40+ messages in thread
* Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-12 8:38 ` David Hildenbrand [not found] ` <CGME20230412111034epcas2p1b46d2a26b7d3ac5db3b0e454255527b0@epcas2p1.samsung.com> @ 2023-04-12 15:15 ` James Bottomley 2023-05-03 23:42 ` Dragan Stancevic 2023-04-12 15:26 ` Gregory Price 2 siblings, 1 reply; 40+ messages in thread From: James Bottomley @ 2023-04-12 15:15 UTC (permalink / raw) To: David Hildenbrand, Huang, Ying, Gregory Price Cc: Dragan Stancevic, lsf-pc, nil-migration, linux-cxl, linux-mm On Wed, 2023-04-12 at 10:38 +0200, David Hildenbrand wrote: > On 12.04.23 04:54, Huang, Ying wrote: > > Gregory Price <gregory.price@memverge.com> writes: [...] > > > That feels like a hack/bodge rather than a proper solution to me. > > > > > > Maybe this is an affirmative argument for the creation of an > > > EXMEM zone. > > > > Let's start with requirements. What is the requirements for a new > > zone type? > > I'm stills scratching my head regarding this. I keep hearing all > different kind of statements that just add more confusions "we want > it to be hotunpluggable" "we want to allow for long-term pinning > memory" "but we still want it to be movable" "we want to place some > unmovable allocations on it". Huh? This is the essential question about CXL memory itself: what would its killer app be? The CXL people (or at least the ones I've talked to) don't exactly know. Within IBM I've seen lots of ideas but no actual concrete applications. Given the rates at which memory density in systems is increasing, I'm a bit dubious of the extensible system pool argument. Providing extensible memory to VMs sounds a bit more plausible, particularly as it solves a big part of the local overcommit problem (although you still have a global one). I'm not really sure I buy the VM migration use case: iterative transfer works fine with small down times so transferring memory seems to be the least of problems with the VM migration use case (it's mostly about problems with attached devices). CXL 3.0 is adding sharing primitives for memory so now we have to ask if there are any multi-node shared memory use cases for this, but most of us have already been burned by multi-node shared clusters once in our career and are a bit leery of a second go around. Is there a use case I left out (or needs expanding)? James ^ permalink raw reply [flat|nested] 40+ messages in thread
* Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-12 15:15 ` [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory James Bottomley @ 2023-05-03 23:42 ` Dragan Stancevic 0 siblings, 0 replies; 40+ messages in thread From: Dragan Stancevic @ 2023-05-03 23:42 UTC (permalink / raw) To: James Bottomley, David Hildenbrand, Huang, Ying, Gregory Price Cc: lsf-pc, nil-migration, linux-cxl, linux-mm Hi James, sorry looks like I missed your email... On 4/12/23 10:15, James Bottomley wrote: > On Wed, 2023-04-12 at 10:38 +0200, David Hildenbrand wrote: >> On 12.04.23 04:54, Huang, Ying wrote: >>> Gregory Price <gregory.price@memverge.com> writes: > [...] >>>> That feels like a hack/bodge rather than a proper solution to me. >>>> >>>> Maybe this is an affirmative argument for the creation of an >>>> EXMEM zone. >>> >>> Let's start with requirements. What is the requirements for a new >>> zone type? >> >> I'm stills scratching my head regarding this. I keep hearing all >> different kind of statements that just add more confusions "we want >> it to be hotunpluggable" "we want to allow for long-term pinning >> memory" "but we still want it to be movable" "we want to place some >> unmovable allocations on it". Huh? > > This is the essential question about CXL memory itself: what would its > killer app be? The CXL people (or at least the ones I've talked to) > don't exactly know. I hope it's not something I've said, I'm not claiming VM migration or hypervisor clustering is the killer app for CXL. I would never claim that. And I'm not one of the CXL folks. You can chuck me into the "CXL enthusiasts" bucket.... For a bit of context, I'm one of the co-authors/architects of VMware's clustered filesystem[1] and I've worked on live VM migration as far back as 2003 on the original ESX server. Back in the day, we introduced the concept of VM live migration into the x86 data-center parlance with a combination of a process monitor and a clustered filesystem. The basic mechanism we put forward at the time was: pre-copy, quiesce, post-copy, un-quiesce. And I think most hypervisor after which added live migration are using loosely the same basic principles, iirc xen introduced LM 4 years later in 2007 and KVM about the same time or perhaps a year later. Anyway, the point that I am trying to get to is, it bugged me 20 years ago that we quiesced, and it bugs me today :) I think 20 years ago, quiescing was an acceptable compromise because we couldn't solve it technologically. Maybe 20-25 years later, we've reached a point we can solve it technologically. I don't know, but the problem interests me enough to try. > Within IBM I've seen lots of ideas but no actual > concrete applications. Given the rates at which memory density in > systems is increasing, I'm a bit dubious of the extensible system pool > argument. Providing extensible memory to VMs sounds a bit more > plausible, particularly as it solves a big part of the local overcommit > problem (although you still have a global one). I'm not really sure I > buy the VM migration use case: iterative transfer works fine with small > down times so transferring memory seems to be the least of problems > with the VM migration use case We do approximately 2.5 Million live migrations per year. Some migrations take less than a second, some take roughly a second, and others on very noisy VMs can take several seconds. Whatever that average is, let's say 1 second per live migration, that's cumulatively roughly 28 days of steal lost to migration per year. As you probably know, live migrations are essential for de-fragmenting hypervisors/de-stranding resources and from my perspective, I'd like to see them happen more often with a smaller customer impact. > (it's mostly about problems with attached devices). That is purely virtualization load type dependent. Maybe for the cloud you're running devices are a problem(I'm guessing here). For us this is a non existent problem. We serve approximately 600,000 customers and don't do forms of pass-through so it's literally a non issue. What I am starting to tackle with nil-migration is to be able to migrate live and executing memory, instead of frozen memory. Which should especially help with noisy VMs, and in my experience customers of noisy VMs are more likely to notice steal and complain about steal. I understand everyone has their own workloads, and the devices problem will be solved in it's own right, but it's out of scope for what I am tackling with nil-migration. My main focus at this time is memory and context migration. < CXL 3.0 is adding sharing primitives for memory so > now we have to ask if there are any multi-node shared memory use cases > for this, but most of us have already been burned by multi-node shared > clusters once in our career and are a bit leery of a second go around. Chatting with you at the last LPC, and judging by the combined gray hair between us, I'll venture to guess we've both fallen off the proverbial bike, many times. It's never stopped me from getting back on. Issue interest me enough to try. If you don't mind me asking, what clustering did you work on? Maybe I am familiar with it > > Is there a use case I left out (or needs expanding)? > > James > [1]. https://en.wikipedia.org/wiki/VMware_VMFS -- Peace can only come as a natural consequence of universal enlightenment -Dr. Nikola Tesla ^ permalink raw reply [flat|nested] 40+ messages in thread
* Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-12 8:38 ` David Hildenbrand [not found] ` <CGME20230412111034epcas2p1b46d2a26b7d3ac5db3b0e454255527b0@epcas2p1.samsung.com> 2023-04-12 15:15 ` [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory James Bottomley @ 2023-04-12 15:26 ` Gregory Price 2023-04-12 15:50 ` David Hildenbrand 2 siblings, 1 reply; 40+ messages in thread From: Gregory Price @ 2023-04-12 15:26 UTC (permalink / raw) To: David Hildenbrand Cc: Huang, Ying, Dragan Stancevic, lsf-pc, nil-migration, linux-cxl, linux-mm On Wed, Apr 12, 2023 at 10:38:04AM +0200, David Hildenbrand wrote: > On 12.04.23 04:54, Huang, Ying wrote: > > Gregory Price <gregory.price@memverge.com> writes: > > > > > On Tue, Apr 11, 2023 at 02:37:50PM +0800, Huang, Ying wrote: > > > > Gregory Price <gregory.price@memverge.com> writes: > > > > > > > > [snip] > > > > > > > > > 2. During the migration process, the memory needs to be forced not to be > > > > > migrated to another node by other means (tiering software, swap, > > > > > etc). The obvious way of doing this would be to migrate and > > > > > temporarily pin the page... but going back to problem #1 we see that > > > > > ZONE_MOVABLE and Pinning are mutually exclusive. So that's > > > > > troublesome. > > > > > > > > Can we use memory policy (cpusets, mbind(), set_mempolicy(), etc.) to > > > > avoid move pages out of CXL.mem node? Now, there are gaps in tiering, > > > > but I think it is fixable. > > > > > > > > Best Regards, > > > > Huang, Ying > > > > > > > > [snip] > > > > > > That feels like a hack/bodge rather than a proper solution to me. > > > > > > Maybe this is an affirmative argument for the creation of an EXMEM > > > zone. > > > > Let's start with requirements. What is the requirements for a new zone > > type? > > I'm stills scratching my head regarding this. I keep hearing all different > kind of statements that just add more confusions "we want it to be > hotunpluggable" "we want to allow for long-term pinning memory" "but we > still want it to be movable" "we want to place some unmovable allocations on > it". Huh? > > Just to clarify: ZONE_MOVABLE allows for pinning. It just doesn't allow for > long-term pinning of memory. > I apologize for the confusion, this is my fault. I had assumed that since dax regions can't be pinned, subsequent nodes backed by a dax device could not be pinned. In testing this, this is not the case. Re: long-term pinning, can you be more explicit as to what is considered long-term? Minutes? hours? days? etc If a migration operation is considered short term, then pinning VM memory during migration deals with this issue cleanly. So walking back my statement - give my testing, i don't believe there's a reason for a new zone. > For good reason, because long-term pinning of memory is just the worst > (memory waste, fragmentation, overcommit) and instead of finding new ways to > *avoid* long-term pinnings, we're coming up with advanced concepts to > work-around the fundamental property of long-term pinnings. > > We want all memory to be long-term pinnable and we want all memory to be > movable/hotunpluggable. That's not going to work. > > If you'd ask me today, my prediction is that ZONE_EXMEM is not going to > happen. > > -- > Thanks, > > David / dhildenb > ^ permalink raw reply [flat|nested] 40+ messages in thread
* Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-12 15:26 ` Gregory Price @ 2023-04-12 15:50 ` David Hildenbrand 2023-04-12 16:34 ` Gregory Price 0 siblings, 1 reply; 40+ messages in thread From: David Hildenbrand @ 2023-04-12 15:50 UTC (permalink / raw) To: Gregory Price Cc: Huang, Ying, Dragan Stancevic, lsf-pc, nil-migration, linux-cxl, linux-mm On 12.04.23 17:26, Gregory Price wrote: > On Wed, Apr 12, 2023 at 10:38:04AM +0200, David Hildenbrand wrote: >> On 12.04.23 04:54, Huang, Ying wrote: >>> Gregory Price <gregory.price@memverge.com> writes: >>> >>>> On Tue, Apr 11, 2023 at 02:37:50PM +0800, Huang, Ying wrote: >>>>> Gregory Price <gregory.price@memverge.com> writes: >>>>> >>>>> [snip] >>>>> >>>>>> 2. During the migration process, the memory needs to be forced not to be >>>>>> migrated to another node by other means (tiering software, swap, >>>>>> etc). The obvious way of doing this would be to migrate and >>>>>> temporarily pin the page... but going back to problem #1 we see that >>>>>> ZONE_MOVABLE and Pinning are mutually exclusive. So that's >>>>>> troublesome. >>>>> >>>>> Can we use memory policy (cpusets, mbind(), set_mempolicy(), etc.) to >>>>> avoid move pages out of CXL.mem node? Now, there are gaps in tiering, >>>>> but I think it is fixable. >>>>> >>>>> Best Regards, >>>>> Huang, Ying >>>>> >>>>> [snip] >>>> >>>> That feels like a hack/bodge rather than a proper solution to me. >>>> >>>> Maybe this is an affirmative argument for the creation of an EXMEM >>>> zone. >>> >>> Let's start with requirements. What is the requirements for a new zone >>> type? >> >> I'm stills scratching my head regarding this. I keep hearing all different >> kind of statements that just add more confusions "we want it to be >> hotunpluggable" "we want to allow for long-term pinning memory" "but we >> still want it to be movable" "we want to place some unmovable allocations on >> it". Huh? >> >> Just to clarify: ZONE_MOVABLE allows for pinning. It just doesn't allow for >> long-term pinning of memory. >> > > I apologize for the confusion, this is my fault. I had assumed that > since dax regions can't be pinned, subsequent nodes backed by a dax > device could not be pinned. In testing this, this is not the case. > > Re: long-term pinning, can you be more explicit as to what is considered > long-term? Minutes? hours? days? etc long-term: possibly forever, controlled by user space. In practice, anything longer than ~10 seconds ( best guess :) ). There can be long-term pinnings that are of very short duration, we just don't know what user space is up to and when it will decide to unpin. Assume user space requests to trigger read/write of a user space page to a file: the page is pinned, DMA is started, once DMA completes the page is unpinned. Short-term. User space does not control how long the page remains pinned. In contrast: Example #1: mapping VM guest memory into an IOMMU using vfio for PCI passthrough requires pinning the pages. Until user space decides to unmap the pages from the IOMMU, the pages will remain pinned. -> long-term Example #2: mapping a user space address range into an IOMMU to repeatedly perform RDMA using that address range requires pinning the pages. Until user space decides to unregister that range, the pages remain pinned. -> long-term Example #3: registering a user space address range with io_uring as a fixed buffer, such that io_uring OPS can avoid the page table walks by simply using the pinned pages that were looked up once. As long as the fixed buffer remains registered, the pages stay pinned. -> long-term -- Thanks, David / dhildenb ^ permalink raw reply [flat|nested] 40+ messages in thread
* Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-12 15:50 ` David Hildenbrand @ 2023-04-12 16:34 ` Gregory Price 2023-04-14 4:16 ` Dragan Stancevic 0 siblings, 1 reply; 40+ messages in thread From: Gregory Price @ 2023-04-12 16:34 UTC (permalink / raw) To: David Hildenbrand Cc: Huang, Ying, Dragan Stancevic, lsf-pc, nil-migration, linux-cxl, linux-mm On Wed, Apr 12, 2023 at 05:50:55PM +0200, David Hildenbrand wrote: > > long-term: possibly forever, controlled by user space. In practice, anything > longer than ~10 seconds ( best guess :) ). There can be long-term pinnings > that are of very short duration, we just don't know what user space is up to > and when it will decide to unpin. > > Assume user space requests to trigger read/write of a user space page to a > file: the page is pinned, DMA is started, once DMA completes the page is > unpinned. Short-term. User space does not control how long the page remains > pinned. > > In contrast: > > Example #1: mapping VM guest memory into an IOMMU using vfio for PCI > passthrough requires pinning the pages. Until user space decides to unmap > the pages from the IOMMU, the pages will remain pinned. -> long-term > > Example #2: mapping a user space address range into an IOMMU to repeatedly > perform RDMA using that address range requires pinning the pages. Until user > space decides to unregister that range, the pages remain pinned. -> > long-term > > Example #3: registering a user space address range with io_uring as a fixed > buffer, such that io_uring OPS can avoid the page table walks by simply > using the pinned pages that were looked up once. As long as the fixed buffer > remains registered, the pages stay pinned. -> long-term > > -- > Thanks, > > David / dhildenb > That pretty much precludes live migration from using CXL as a transport mechanism, since live migration would be a user-initiated process, you would need what amounts to an atomic move between hosts to ensure pages are not left pinned. The more i'm reading the more i'm somewhat convinced CXL memory should not allow pinning at all. I suppose you could implement a new RDMA feature where the remote host's CXL memory is temporarily mapped, data is migrated, and then that area is unmapped. Basically the exact same RDMA mechanism, but using memory instead of network. This would make the operation a kernel-controlled if pin/unpin is required. Lots to talk about. ~Gregory ^ permalink raw reply [flat|nested] 40+ messages in thread
* Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-12 16:34 ` Gregory Price @ 2023-04-14 4:16 ` Dragan Stancevic 0 siblings, 0 replies; 40+ messages in thread From: Dragan Stancevic @ 2023-04-14 4:16 UTC (permalink / raw) To: Gregory Price, David Hildenbrand Cc: Huang, Ying, lsf-pc, nil-migration, linux-cxl, linux-mm Hi Gregory- On 4/12/23 11:34, Gregory Price wrote: > On Wed, Apr 12, 2023 at 05:50:55PM +0200, David Hildenbrand wrote: >> >> long-term: possibly forever, controlled by user space. In practice, anything >> longer than ~10 seconds ( best guess :) ). There can be long-term pinnings >> that are of very short duration, we just don't know what user space is up to >> and when it will decide to unpin. >> >> Assume user space requests to trigger read/write of a user space page to a >> file: the page is pinned, DMA is started, once DMA completes the page is >> unpinned. Short-term. User space does not control how long the page remains >> pinned. >> >> In contrast: >> >> Example #1: mapping VM guest memory into an IOMMU using vfio for PCI >> passthrough requires pinning the pages. Until user space decides to unmap >> the pages from the IOMMU, the pages will remain pinned. -> long-term >> >> Example #2: mapping a user space address range into an IOMMU to repeatedly >> perform RDMA using that address range requires pinning the pages. Until user >> space decides to unregister that range, the pages remain pinned. -> >> long-term >> >> Example #3: registering a user space address range with io_uring as a fixed >> buffer, such that io_uring OPS can avoid the page table walks by simply >> using the pinned pages that were looked up once. As long as the fixed buffer >> remains registered, the pages stay pinned. -> long-term >> >> -- >> Thanks, >> >> David / dhildenb >> > > That pretty much precludes live migration from using CXL as a transport > mechanism, since live migration would be a user-initiated process, you > would need what amounts to an atomic move between hosts to ensure pages > are not left pinned. Do you really need an atomic-in-between-hots? I mean, it's not really a failure if you are in the process of migrating pages onto the switched cxl memory memory and one of the pages is pulled out of cxl and back on the hypervisor. The running VM cpu can do loads and stores from either. So it's running, it's not affected. It's just that your migration is potentially "stalled" or "canceled". You only encounter issues when all your pages are on cxl and the other hypervisor is pulling pages out. > The more i'm reading the more i'm somewhat convinced CXL memory should > not allow pinning at all. I think you want to be able to somehow pin the pages on one hypervisor and unpin them on the other hypervisor. Or in some other way "pass ownership" between the hypervisor. Right? Because of the scenario I mention above, if your source hypervisor takes a page out of cxl, then your destination hypervisor has a hole in VMs address space and can't run it. > I suppose you could implement a new RDMA feature where the remote host's > CXL memory is temporarily mapped, data is migrated, and then that area > is unmapped. Basically the exact same RDMA mechanism, but using memory > instead of network. This would make the operation a kernel-controlled > if pin/unpin is required. That would move us from the shared memory in the CXL 3 spec into the sections on direct memory placement I think. Which in order of preference is a #2 for me personally and a "backup" plan if #1 shared memory doesn't pan out. > Lots to talk about. > > ~Gregory > -- -- Peace can only come as a natural consequence of universal enlightenment -Dr. Nikola Tesla ^ permalink raw reply [flat|nested] 40+ messages in thread
* Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-11 6:37 ` [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory Huang, Ying 2023-04-11 15:36 ` Gregory Price @ 2023-04-14 3:33 ` Dragan Stancevic 2023-04-14 5:35 ` Huang, Ying 1 sibling, 1 reply; 40+ messages in thread From: Dragan Stancevic @ 2023-04-14 3:33 UTC (permalink / raw) To: Huang, Ying, Gregory Price; +Cc: lsf-pc, nil-migration, linux-cxl, linux-mm On 4/11/23 01:37, Huang, Ying wrote: > Gregory Price <gregory.price@memverge.com> writes: > > [snip] > >> 2. During the migration process, the memory needs to be forced not to be >> migrated to another node by other means (tiering software, swap, >> etc). The obvious way of doing this would be to migrate and >> temporarily pin the page... but going back to problem #1 we see that >> ZONE_MOVABLE and Pinning are mutually exclusive. So that's >> troublesome. > > Can we use memory policy (cpusets, mbind(), set_mempolicy(), etc.) to > avoid move pages out of CXL.mem node? Now, there are gaps in tiering, > but I think it is fixable. Hmmm, I don't know about cpusets. For mbind, are you thinking something along the lines of MPOL_MF_MOVE_ALL? I guess it does have that deterministic placement, but this would have to be called from the process itself. Unlike migrate_pages which takes a pid. Same for set_mempolicy, right? I mean I guess, if some of this needs to be added into qemu it's not the end of the word... > Best Regards, > Huang, Ying > > [snip] > -- -- Peace can only come as a natural consequence of universal enlightenment -Dr. Nikola Tesla ^ permalink raw reply [flat|nested] 40+ messages in thread
* Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-14 3:33 ` Dragan Stancevic @ 2023-04-14 5:35 ` Huang, Ying 0 siblings, 0 replies; 40+ messages in thread From: Huang, Ying @ 2023-04-14 5:35 UTC (permalink / raw) To: Dragan Stancevic Cc: Gregory Price, lsf-pc, nil-migration, linux-cxl, linux-mm Dragan Stancevic <dragan@stancevic.com> writes: > On 4/11/23 01:37, Huang, Ying wrote: >> Gregory Price <gregory.price@memverge.com> writes: >> [snip] >> >>> 2. During the migration process, the memory needs to be forced not to be >>> migrated to another node by other means (tiering software, swap, >>> etc). The obvious way of doing this would be to migrate and >>> temporarily pin the page... but going back to problem #1 we see that >>> ZONE_MOVABLE and Pinning are mutually exclusive. So that's >>> troublesome. >> Can we use memory policy (cpusets, mbind(), set_mempolicy(), etc.) >> to >> avoid move pages out of CXL.mem node? Now, there are gaps in tiering, >> but I think it is fixable. > > > Hmmm, I don't know about cpusets. For mbind, are you thinking > something along the lines of MPOL_MF_MOVE_ALL? I guess it does have > that deterministic placement, but this would have to be called from > the process itself. Unlike migrate_pages which takes a pid. You can still use migrate_pages(2). But after that, if you want to prevent the pages to be migrated out of CXL.mem, you can use some kind of memory policy, such as cpusets, mbind(), set_mempolicy(). Best Regards, Huang, Ying > Same for set_mempolicy, right? > > I mean I guess, if some of this needs to be added into qemu it's not > the end of the word... > > >> Best Regards, >> Huang, Ying >> [snip] >> ^ permalink raw reply [flat|nested] 40+ messages in thread
* RE: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-07 21:05 [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory Dragan Stancevic 2023-04-07 22:23 ` James Houghton 2023-04-08 0:05 ` Gregory Price @ 2023-04-09 17:40 ` Shreyas Shah 2023-04-11 1:08 ` Dragan Stancevic [not found] ` <CGME20230410030532epcas2p49eae675396bf81658c1a3401796da1d4@epcas2p4.samsung.com> ` (3 subsequent siblings) 6 siblings, 1 reply; 40+ messages in thread From: Shreyas Shah @ 2023-04-09 17:40 UTC (permalink / raw) To: Dragan Stancevic, lsf-pc; +Cc: nil-migration, linux-cxl, linux-mm Hi Dragon, The concept is great to time share the CXL attached memory across two NUMA nodes for live migration and create a cluster of VMs to increase the compute capacity. When and where is the BoF? Regards, Shreyas -----Original Message----- From: Dragan Stancevic <dragan@stancevic.com> Sent: Friday, April 7, 2023 2:06 PM To: lsf-pc@lists.linux-foundation.org Cc: nil-migration@lists.linux.dev; linux-cxl@vger.kernel.org; linux-mm@kvack.org Subject: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory Hi folks- if it's not too late for the schedule... I am starting to tackle VM live migration and hypervisor clustering over switched CXL memory[1][2], intended for cloud virtualization types of loads. I'd be interested in doing a small BoF session with some slides and get into a discussion/brainstorming with other people that deal with VM/LM cloud loads. Among other things to discuss would be page migrations over switched CXL memory, shared in-memory ABI to allow VM hand-off between hypervisors, etc... A few of us discussed some of this under the ZONE_XMEM thread, but I figured it might be better to start a separate thread. If there is interested, thank you. [1]. High-level overview available at http://nil-migration.org/ [2]. Based on CXL spec 3.0 -- Peace can only come as a natural consequence of universal enlightenment -Dr. Nikola Tesla ^ permalink raw reply [flat|nested] 40+ messages in thread
* Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-09 17:40 ` Shreyas Shah @ 2023-04-11 1:08 ` Dragan Stancevic 2023-04-11 1:17 ` Shreyas Shah 0 siblings, 1 reply; 40+ messages in thread From: Dragan Stancevic @ 2023-04-11 1:08 UTC (permalink / raw) To: Shreyas Shah, lsf-pc; +Cc: nil-migration, linux-cxl, linux-mm Hi Shreyas- On 4/9/23 12:40, Shreyas Shah wrote: > Hi Dragon, > > The concept is great to time share the CXL attached memory across two NUMA nodes for live migration and create a cluster of VMs to increase the compute capacity. > > When and where is the BoF? It's a proposal sent under (CFP), it has not been accepted yet. The agenda is selected by the program committee based on interest. The current proposal is for LSF/MM/BPF summit[1] running May 8 - May 10th, but it's not happening if not approved by committee. [1]. https://events.linuxfoundation.org/lsfmm/ > > > Regards, > Shreyas > > > -----Original Message----- > From: Dragan Stancevic <dragan@stancevic.com> > Sent: Friday, April 7, 2023 2:06 PM > To: lsf-pc@lists.linux-foundation.org > Cc: nil-migration@lists.linux.dev; linux-cxl@vger.kernel.org; linux-mm@kvack.org > Subject: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory > > Hi folks- > > if it's not too late for the schedule... > > I am starting to tackle VM live migration and hypervisor clustering over switched CXL memory[1][2], intended for cloud virtualization types of loads. > > I'd be interested in doing a small BoF session with some slides and get into a discussion/brainstorming with other people that deal with VM/LM cloud loads. Among other things to discuss would be page migrations over switched CXL memory, shared in-memory ABI to allow VM hand-off between hypervisors, etc... > > A few of us discussed some of this under the ZONE_XMEM thread, but I figured it might be better to start a separate thread. > > If there is interested, thank you. > > > [1]. High-level overview available at http://nil-migration.org/ [2]. Based on CXL spec 3.0 > > -- > Peace can only come as a natural consequence of universal enlightenment -Dr. Nikola Tesla -- -- Peace can only come as a natural consequence of universal enlightenment -Dr. Nikola Tesla ^ permalink raw reply [flat|nested] 40+ messages in thread
* RE: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-11 1:08 ` Dragan Stancevic @ 2023-04-11 1:17 ` Shreyas Shah 2023-04-11 1:32 ` Dragan Stancevic 0 siblings, 1 reply; 40+ messages in thread From: Shreyas Shah @ 2023-04-11 1:17 UTC (permalink / raw) To: Dragan Stancevic, lsf-pc; +Cc: nil-migration, linux-cxl, linux-mm Thank you, Dragon. Btw, we can demonstrate the VM live migration with our FPGA based CXL memory and our demonstration today. We are not application expert, looked at the last diagram in your link and we are confident we can achieve it. Will there be any interest from the group? I can present for 15 mins and Q&A. Regards, Shreyas -----Original Message----- From: Dragan Stancevic <dragan@stancevic.com> Sent: Monday, April 10, 2023 6:09 PM To: Shreyas Shah <shreyas.shah@elastics.cloud>; lsf-pc@lists.linux-foundation.org Cc: nil-migration@lists.linux.dev; linux-cxl@vger.kernel.org; linux-mm@kvack.org Subject: Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory Hi Shreyas- On 4/9/23 12:40, Shreyas Shah wrote: > Hi Dragon, > > The concept is great to time share the CXL attached memory across two NUMA nodes for live migration and create a cluster of VMs to increase the compute capacity. > > When and where is the BoF? It's a proposal sent under (CFP), it has not been accepted yet. The agenda is selected by the program committee based on interest. The current proposal is for LSF/MM/BPF summit[1] running May 8 - May 10th, but it's not happening if not approved by committee. [1]. https://events.linuxfoundation.org/lsfmm/ > > > Regards, > Shreyas > > > -----Original Message----- > From: Dragan Stancevic <dragan@stancevic.com> > Sent: Friday, April 7, 2023 2:06 PM > To: lsf-pc@lists.linux-foundation.org > Cc: nil-migration@lists.linux.dev; linux-cxl@vger.kernel.org; > linux-mm@kvack.org > Subject: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory > > Hi folks- > > if it's not too late for the schedule... > > I am starting to tackle VM live migration and hypervisor clustering over switched CXL memory[1][2], intended for cloud virtualization types of loads. > > I'd be interested in doing a small BoF session with some slides and get into a discussion/brainstorming with other people that deal with VM/LM cloud loads. Among other things to discuss would be page migrations over switched CXL memory, shared in-memory ABI to allow VM hand-off between hypervisors, etc... > > A few of us discussed some of this under the ZONE_XMEM thread, but I figured it might be better to start a separate thread. > > If there is interested, thank you. > > > [1]. High-level overview available at http://nil-migration.org/ [2]. > Based on CXL spec 3.0 > > -- > Peace can only come as a natural consequence of universal > enlightenment -Dr. Nikola Tesla -- -- Peace can only come as a natural consequence of universal enlightenment -Dr. Nikola Tesla ^ permalink raw reply [flat|nested] 40+ messages in thread
* Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-11 1:17 ` Shreyas Shah @ 2023-04-11 1:32 ` Dragan Stancevic 2023-04-11 4:33 ` Shreyas Shah 0 siblings, 1 reply; 40+ messages in thread From: Dragan Stancevic @ 2023-04-11 1:32 UTC (permalink / raw) To: Shreyas Shah, lsf-pc; +Cc: nil-migration, linux-cxl, linux-mm Hi Shreyas- speaking strictly for myself, sounds interesting On 4/10/23 20:17, Shreyas Shah wrote: > Thank you, Dragon. > > Btw, we can demonstrate the VM live migration with our FPGA based CXL memory and our demonstration today. We are not application expert, looked at the last diagram in your link and we are confident we can achieve it. > > Will there be any interest from the group? I can present for 15 mins and Q&A. > > Regards, > Shreyas > > > > -----Original Message----- > From: Dragan Stancevic <dragan@stancevic.com> > Sent: Monday, April 10, 2023 6:09 PM > To: Shreyas Shah <shreyas.shah@elastics.cloud>; lsf-pc@lists.linux-foundation.org > Cc: nil-migration@lists.linux.dev; linux-cxl@vger.kernel.org; linux-mm@kvack.org > Subject: Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory > > Hi Shreyas- > > On 4/9/23 12:40, Shreyas Shah wrote: >> Hi Dragon, >> >> The concept is great to time share the CXL attached memory across two NUMA nodes for live migration and create a cluster of VMs to increase the compute capacity. >> >> When and where is the BoF? > > It's a proposal sent under (CFP), it has not been accepted yet. The agenda is selected by the program committee based on interest. The current proposal is for LSF/MM/BPF summit[1] running May 8 - May 10th, but it's not happening if not approved by committee. > > > [1]. https://events.linuxfoundation.org/lsfmm/ > > >> >> >> Regards, >> Shreyas >> >> >> -----Original Message----- >> From: Dragan Stancevic <dragan@stancevic.com> >> Sent: Friday, April 7, 2023 2:06 PM >> To: lsf-pc@lists.linux-foundation.org >> Cc: nil-migration@lists.linux.dev; linux-cxl@vger.kernel.org; >> linux-mm@kvack.org >> Subject: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory >> >> Hi folks- >> >> if it's not too late for the schedule... >> >> I am starting to tackle VM live migration and hypervisor clustering over switched CXL memory[1][2], intended for cloud virtualization types of loads. >> >> I'd be interested in doing a small BoF session with some slides and get into a discussion/brainstorming with other people that deal with VM/LM cloud loads. Among other things to discuss would be page migrations over switched CXL memory, shared in-memory ABI to allow VM hand-off between hypervisors, etc... >> >> A few of us discussed some of this under the ZONE_XMEM thread, but I figured it might be better to start a separate thread. >> >> If there is interested, thank you. >> >> >> [1]. High-level overview available at http://nil-migration.org/ [2]. >> Based on CXL spec 3.0 >> >> -- >> Peace can only come as a natural consequence of universal >> enlightenment -Dr. Nikola Tesla > > -- > -- > Peace can only come as a natural consequence of universal enlightenment -Dr. Nikola Tesla > -- -- Peace can only come as a natural consequence of universal enlightenment -Dr. Nikola Tesla ^ permalink raw reply [flat|nested] 40+ messages in thread
* RE: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-11 1:32 ` Dragan Stancevic @ 2023-04-11 4:33 ` Shreyas Shah 2023-04-14 3:26 ` Dragan Stancevic 0 siblings, 1 reply; 40+ messages in thread From: Shreyas Shah @ 2023-04-11 4:33 UTC (permalink / raw) To: Dragan Stancevic, lsf-pc; +Cc: nil-migration, linux-cxl, linux-mm Hi Dragon, Do you all meet on Zoom or Teams weekly call? Maybe next time I can present if you have a slot. Regards, Shreyas -----Original Message----- From: Dragan Stancevic <dragan@stancevic.com> Sent: Monday, April 10, 2023 6:33 PM To: Shreyas Shah <shreyas.shah@elastics.cloud>; lsf-pc@lists.linux-foundation.org Cc: nil-migration@lists.linux.dev; linux-cxl@vger.kernel.org; linux-mm@kvack.org Subject: Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory Hi Shreyas- speaking strictly for myself, sounds interesting On 4/10/23 20:17, Shreyas Shah wrote: > Thank you, Dragon. > > Btw, we can demonstrate the VM live migration with our FPGA based CXL memory and our demonstration today. We are not application expert, looked at the last diagram in your link and we are confident we can achieve it. > > Will there be any interest from the group? I can present for 15 mins and Q&A. > > Regards, > Shreyas > > > > -----Original Message----- > From: Dragan Stancevic <dragan@stancevic.com> > Sent: Monday, April 10, 2023 6:09 PM > To: Shreyas Shah <shreyas.shah@elastics.cloud>; > lsf-pc@lists.linux-foundation.org > Cc: nil-migration@lists.linux.dev; linux-cxl@vger.kernel.org; > linux-mm@kvack.org > Subject: Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory > > Hi Shreyas- > > On 4/9/23 12:40, Shreyas Shah wrote: >> Hi Dragon, >> >> The concept is great to time share the CXL attached memory across two NUMA nodes for live migration and create a cluster of VMs to increase the compute capacity. >> >> When and where is the BoF? > > It's a proposal sent under (CFP), it has not been accepted yet. The agenda is selected by the program committee based on interest. The current proposal is for LSF/MM/BPF summit[1] running May 8 - May 10th, but it's not happening if not approved by committee. > > > [1]. https://events.linuxfoundation.org/lsfmm/ > > >> >> >> Regards, >> Shreyas >> >> >> -----Original Message----- >> From: Dragan Stancevic <dragan@stancevic.com> >> Sent: Friday, April 7, 2023 2:06 PM >> To: lsf-pc@lists.linux-foundation.org >> Cc: nil-migration@lists.linux.dev; linux-cxl@vger.kernel.org; >> linux-mm@kvack.org >> Subject: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory >> >> Hi folks- >> >> if it's not too late for the schedule... >> >> I am starting to tackle VM live migration and hypervisor clustering over switched CXL memory[1][2], intended for cloud virtualization types of loads. >> >> I'd be interested in doing a small BoF session with some slides and get into a discussion/brainstorming with other people that deal with VM/LM cloud loads. Among other things to discuss would be page migrations over switched CXL memory, shared in-memory ABI to allow VM hand-off between hypervisors, etc... >> >> A few of us discussed some of this under the ZONE_XMEM thread, but I figured it might be better to start a separate thread. >> >> If there is interested, thank you. >> >> >> [1]. High-level overview available at http://nil-migration.org/ [2]. >> Based on CXL spec 3.0 >> >> -- >> Peace can only come as a natural consequence of universal >> enlightenment -Dr. Nikola Tesla > > -- > -- > Peace can only come as a natural consequence of universal > enlightenment -Dr. Nikola Tesla > -- -- Peace can only come as a natural consequence of universal enlightenment -Dr. Nikola Tesla ^ permalink raw reply [flat|nested] 40+ messages in thread
* Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-11 4:33 ` Shreyas Shah @ 2023-04-14 3:26 ` Dragan Stancevic 0 siblings, 0 replies; 40+ messages in thread From: Dragan Stancevic @ 2023-04-14 3:26 UTC (permalink / raw) To: Shreyas Shah, lsf-pc; +Cc: nil-migration, linux-cxl, linux-mm On 4/10/23 23:33, Shreyas Shah wrote: > Hi Dragon, > > Do you all meet on Zoom or Teams weekly call? > > Maybe next time I can present if you have a slot. Hi Shreyas- no, sorry there is no zoom call cadence at the time. > Regards, > Shreyas > -----Original Message----- > From: Dragan Stancevic <dragan@stancevic.com> > Sent: Monday, April 10, 2023 6:33 PM > To: Shreyas Shah <shreyas.shah@elastics.cloud>; lsf-pc@lists.linux-foundation.org > Cc: nil-migration@lists.linux.dev; linux-cxl@vger.kernel.org; linux-mm@kvack.org > Subject: Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory > > Hi Shreyas- > > speaking strictly for myself, sounds interesting > > > On 4/10/23 20:17, Shreyas Shah wrote: >> Thank you, Dragon. >> >> Btw, we can demonstrate the VM live migration with our FPGA based CXL memory and our demonstration today. We are not application expert, looked at the last diagram in your link and we are confident we can achieve it. >> >> Will there be any interest from the group? I can present for 15 mins and Q&A. >> >> Regards, >> Shreyas >> >> >> >> -----Original Message----- >> From: Dragan Stancevic <dragan@stancevic.com> >> Sent: Monday, April 10, 2023 6:09 PM >> To: Shreyas Shah <shreyas.shah@elastics.cloud>; >> lsf-pc@lists.linux-foundation.org >> Cc: nil-migration@lists.linux.dev; linux-cxl@vger.kernel.org; >> linux-mm@kvack.org >> Subject: Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory >> >> Hi Shreyas- >> >> On 4/9/23 12:40, Shreyas Shah wrote: >>> Hi Dragon, >>> >>> The concept is great to time share the CXL attached memory across two NUMA nodes for live migration and create a cluster of VMs to increase the compute capacity. >>> >>> When and where is the BoF? >> >> It's a proposal sent under (CFP), it has not been accepted yet. The agenda is selected by the program committee based on interest. The current proposal is for LSF/MM/BPF summit[1] running May 8 - May 10th, but it's not happening if not approved by committee. >> >> >> [1]. https://events.linuxfoundation.org/lsfmm/ >> >> >>> >>> >>> Regards, >>> Shreyas >>> >>> >>> -----Original Message----- >>> From: Dragan Stancevic <dragan@stancevic.com> >>> Sent: Friday, April 7, 2023 2:06 PM >>> To: lsf-pc@lists.linux-foundation.org >>> Cc: nil-migration@lists.linux.dev; linux-cxl@vger.kernel.org; >>> linux-mm@kvack.org >>> Subject: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory >>> >>> Hi folks- >>> >>> if it's not too late for the schedule... >>> >>> I am starting to tackle VM live migration and hypervisor clustering over switched CXL memory[1][2], intended for cloud virtualization types of loads. >>> >>> I'd be interested in doing a small BoF session with some slides and get into a discussion/brainstorming with other people that deal with VM/LM cloud loads. Among other things to discuss would be page migrations over switched CXL memory, shared in-memory ABI to allow VM hand-off between hypervisors, etc... >>> >>> A few of us discussed some of this under the ZONE_XMEM thread, but I figured it might be better to start a separate thread. >>> >>> If there is interested, thank you. >>> >>> >>> [1]. High-level overview available at http://nil-migration.org/ [2]. >>> Based on CXL spec 3.0 >>> >>> -- >>> Peace can only come as a natural consequence of universal >>> enlightenment -Dr. Nikola Tesla >> >> -- >> -- >> Peace can only come as a natural consequence of universal >> enlightenment -Dr. Nikola Tesla >> > > -- > -- > Peace can only come as a natural consequence of universal enlightenment -Dr. Nikola Tesla > -- -- Peace can only come as a natural consequence of universal enlightenment -Dr. Nikola Tesla ^ permalink raw reply [flat|nested] 40+ messages in thread
[parent not found: <CGME20230410030532epcas2p49eae675396bf81658c1a3401796da1d4@epcas2p4.samsung.com>]
* RE: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory [not found] ` <CGME20230410030532epcas2p49eae675396bf81658c1a3401796da1d4@epcas2p4.samsung.com> @ 2023-04-10 3:05 ` Kyungsan Kim 2023-04-10 17:46 ` [External] " Viacheslav A.Dubeyko 2023-04-14 3:27 ` Dragan Stancevic 0 siblings, 2 replies; 40+ messages in thread From: Kyungsan Kim @ 2023-04-10 3:05 UTC (permalink / raw) To: dragan Cc: lsf-pc, linux-mm, linux-fsdevel, linux-cxl, a.manzanares, viacheslav.dubeyko, dan.j.williams, seungjun.ha, wj28.lee >Hi folks- > >if it's not too late for the schedule... > >I am starting to tackle VM live migration and hypervisor clustering over >switched CXL memory[1][2], intended for cloud virtualization types of loads. > >I'd be interested in doing a small BoF session with some slides and get >into a discussion/brainstorming with other people that deal with VM/LM >cloud loads. Among other things to discuss would be page migrations over >switched CXL memory, shared in-memory ABI to allow VM hand-off between >hypervisors, etc... > >A few of us discussed some of this under the ZONE_XMEM thread, but I >figured it might be better to start a separate thread. > >If there is interested, thank you. I would like join the discussion as well. Let me kindly suggest it would be more great if it includes the data flow of VM/hypervisor as background and kernel interaction expected. > > >[1]. High-level overview available at http://nil-migration.org/ >[2]. Based on CXL spec 3.0 > >-- >Peace can only come as a natural consequence >of universal enlightenment -Dr. Nikola Tesla ^ permalink raw reply [flat|nested] 40+ messages in thread
* Re: [External] [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-10 3:05 ` [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory Kyungsan Kim @ 2023-04-10 17:46 ` Viacheslav A.Dubeyko 2023-04-14 3:27 ` Dragan Stancevic 1 sibling, 0 replies; 40+ messages in thread From: Viacheslav A.Dubeyko @ 2023-04-10 17:46 UTC (permalink / raw) To: Kyungsan Kim Cc: dragan, lsf-pc, linux-mm, Linux FS Devel, linux-cxl, Adam Manzanares, Dan Williams, seungjun.ha, wj28.lee > On Apr 9, 2023, at 8:05 PM, Kyungsan Kim <ks0204.kim@samsung.com> wrote: > >> Hi folks- >> >> if it's not too late for the schedule... >> >> I am starting to tackle VM live migration and hypervisor clustering over >> switched CXL memory[1][2], intended for cloud virtualization types of loads. >> >> I'd be interested in doing a small BoF session with some slides and get >> into a discussion/brainstorming with other people that deal with VM/LM >> cloud loads. Among other things to discuss would be page migrations over >> switched CXL memory, shared in-memory ABI to allow VM hand-off between >> hypervisors, etc... >> >> A few of us discussed some of this under the ZONE_XMEM thread, but I >> figured it might be better to start a separate thread. >> >> If there is interested, thank you. > > I would like join the discussion as well. > Let me kindly suggest it would be more great if it includes the data flow of VM/hypervisor as background and kernel interaction expected. > Sounds like interesting topic to me. I would like to attend the discussion. Thanks, Slava. >> >> >> [1]. High-level overview available at http://nil-migration.org/ >> [2]. Based on CXL spec 3.0 >> >> -- >> Peace can only come as a natural consequence >> of universal enlightenment -Dr. Nikola Tesla ^ permalink raw reply [flat|nested] 40+ messages in thread
* Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-10 3:05 ` [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory Kyungsan Kim 2023-04-10 17:46 ` [External] " Viacheslav A.Dubeyko @ 2023-04-14 3:27 ` Dragan Stancevic 1 sibling, 0 replies; 40+ messages in thread From: Dragan Stancevic @ 2023-04-14 3:27 UTC (permalink / raw) To: Kyungsan Kim Cc: lsf-pc, linux-mm, linux-fsdevel, linux-cxl, a.manzanares, viacheslav.dubeyko, dan.j.williams, seungjun.ha, wj28.lee Hi Kyungsan- On 4/9/23 22:05, Kyungsan Kim wrote: >> Hi folks- >> >> if it's not too late for the schedule... >> >> I am starting to tackle VM live migration and hypervisor clustering over >> switched CXL memory[1][2], intended for cloud virtualization types of loads. >> >> I'd be interested in doing a small BoF session with some slides and get >> into a discussion/brainstorming with other people that deal with VM/LM >> cloud loads. Among other things to discuss would be page migrations over >> switched CXL memory, shared in-memory ABI to allow VM hand-off between >> hypervisors, etc... >> >> A few of us discussed some of this under the ZONE_XMEM thread, but I >> figured it might be better to start a separate thread. >> >> If there is interested, thank you. > > I would like join the discussion as well. > Let me kindly suggest it would be more great if it includes the data flow of VM/hypervisor as background and kernel interaction expected. Thank you for the suggestion, have you had a chance to check out http://nil-migration.org/ I have a high-level data flow between hypervisors, both for VM migration and hypervisor clustering. If that is not enough, I can definitely throw more things together. Let me know, thank you >> >> >> [1]. High-level overview available at http://nil-migration.org/ >> [2]. Based on CXL spec 3.0 >> >> -- >> Peace can only come as a natural consequence >> of universal enlightenment -Dr. Nikola Tesla > -- -- Peace can only come as a natural consequence of universal enlightenment -Dr. Nikola Tesla ^ permalink raw reply [flat|nested] 40+ messages in thread
* Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-07 21:05 [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory Dragan Stancevic ` (3 preceding siblings ...) [not found] ` <CGME20230410030532epcas2p49eae675396bf81658c1a3401796da1d4@epcas2p4.samsung.com> @ 2023-04-11 18:00 ` Dave Hansen 2023-05-01 23:49 ` Dragan Stancevic 2023-04-11 18:16 ` RAGHU H 2023-05-09 15:08 ` Dragan Stancevic 6 siblings, 1 reply; 40+ messages in thread From: Dave Hansen @ 2023-04-11 18:00 UTC (permalink / raw) To: Dragan Stancevic, lsf-pc; +Cc: nil-migration, linux-cxl, linux-mm On 4/7/23 14:05, Dragan Stancevic wrote: > I'd be interested in doing a small BoF session with some slides and get > into a discussion/brainstorming with other people that deal with VM/LM > cloud loads. Among other things to discuss would be page migrations over > switched CXL memory, shared in-memory ABI to allow VM hand-off between > hypervisors, etc... How would 'struct page' or other kernel metadata be handled? I assume you'd want a really big CXL memory device with as many hosts connected to it as is feasible. But, in order to hand the memory off from one host to another, both would need to have metadata for it at _some_ point. So, do all hosts have metadata for the whole CXL memory device all the time? Or, would they create the metadata (hotplug) when a VM is migrated in and destroy it (hot unplug) when a VM is migrated out? That gets back to the granularity question discussed elsewhere in the thread. How would the metadata allocation granularity interact with the page allocation granularity? How would fragmentation be avoided so that hosts don't eat up all their RAM with unused metadata? ^ permalink raw reply [flat|nested] 40+ messages in thread
* Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-11 18:00 ` [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory Dave Hansen @ 2023-05-01 23:49 ` Dragan Stancevic 0 siblings, 0 replies; 40+ messages in thread From: Dragan Stancevic @ 2023-05-01 23:49 UTC (permalink / raw) To: Dave Hansen, lsf-pc; +Cc: nil-migration, linux-cxl, linux-mm Hi Dave- sorry, looks like I've missed your email On 4/11/23 13:00, Dave Hansen wrote: > On 4/7/23 14:05, Dragan Stancevic wrote: >> I'd be interested in doing a small BoF session with some slides and get >> into a discussion/brainstorming with other people that deal with VM/LM >> cloud loads. Among other things to discuss would be page migrations over >> switched CXL memory, shared in-memory ABI to allow VM hand-off between >> hypervisors, etc... > > How would 'struct page' or other kernel metadata be handled? > > I assume you'd want a really big CXL memory device with as many hosts > connected to it as is feasible. But, in order to hand the memory off > from one host to another, both would need to have metadata for it at > _some_ point. To be honest, I have not been thinking of this in terms of a "star" connection topology. Where say each host in a rack connects to the same memory device, I think I'd get bottle-necked on a singular device. Evac of a few hypervisors simultaneously might get a bit dicey. I've been thinking of it more in terms of multiple memory devices per rack, connected to various hypervisors to form a hypervisor traversal graph[1]. For example in this graph, a VM would migrate across a single hop, or a few hops to reach it's destination hypervisor. And for the lack of better word, this would be your "migration namespace" to migrate the VM across the rack. The critical connections in the graph are hostfoo04 and hostfoo09, and those you'd use if you want to pop the VM into a different "migration namespace", for example a different rack or maybe even a pod. Of course, this is quite a ways out since there are no CXL 3.0 devices yet. As a first step I would like to get to a point where I can emulate this with qemu and just prototype various approaches, but starting with a single emulated memory device and two hosts. > So, do all hosts have metadata for the whole CXL memory device all the > time? Or, would they create the metadata (hotplug) when a VM is > migrated in and destroy it (hot unplug) when a VM is migrated out? To be honest I have not thought about hot plugging, but might be something for me to keep in mind and ponder about it. And if you have additional thoughts on this I'd love to hear them. What I was thinking, and this may or may not be possible, or may be possible only to a certain extent, but my preference would be to keep as much of the metadata as possible on the memory device itself and have the hypervisors cooperate through some kind of ownership mechanism. > That gets back to the granularity question discussed elsewhere in the > thread. How would the metadata allocation granularity interact with the > page allocation granularity? How would fragmentation be avoided so that > hosts don't eat up all their RAM with unused metadata? Yeah, this is something I am still running through my head. Even if we have this "ownership-cooperation", is this based on pages, what happens to the sub-page allocations, do we move them through the buckets or do we attach ownership to sub-page allocations too. In my ideal world, you'd have two hypervisors cooperate over this memory as transparently as CPUs in a single system collaborating across NUMA nodes. A lot to think about, many problems to solve and a lot of work to do. I don't have all the answers yet, but value all input & help [1]. https://nil-migration.org/VM-Graph.png -- Peace can only come as a natural consequence of universal enlightenment -Dr. Nikola Tesla ^ permalink raw reply [flat|nested] 40+ messages in thread
* Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-07 21:05 [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory Dragan Stancevic ` (4 preceding siblings ...) 2023-04-11 18:00 ` [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory Dave Hansen @ 2023-04-11 18:16 ` RAGHU H 2023-05-09 15:08 ` Dragan Stancevic 6 siblings, 0 replies; 40+ messages in thread From: RAGHU H @ 2023-04-11 18:16 UTC (permalink / raw) To: Dragan Stancevic; +Cc: lsf-pc, nil-migration, linux-cxl, linux-mm Hi Dragan Please add me to the discussion! Regards Raghu On Sat, Apr 8, 2023 at 2:56 AM Dragan Stancevic <dragan@stancevic.com> wrote: > > Hi folks- > > if it's not too late for the schedule... > > I am starting to tackle VM live migration and hypervisor clustering over > switched CXL memory[1][2], intended for cloud virtualization types of loads. > > I'd be interested in doing a small BoF session with some slides and get > into a discussion/brainstorming with other people that deal with VM/LM > cloud loads. Among other things to discuss would be page migrations over > switched CXL memory, shared in-memory ABI to allow VM hand-off between > hypervisors, etc... > > A few of us discussed some of this under the ZONE_XMEM thread, but I > figured it might be better to start a separate thread. > > If there is interested, thank you. > > > [1]. High-level overview available at http://nil-migration.org/ > [2]. Based on CXL spec 3.0 > > -- > Peace can only come as a natural consequence > of universal enlightenment -Dr. Nikola Tesla ^ permalink raw reply [flat|nested] 40+ messages in thread
* Re: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory 2023-04-07 21:05 [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory Dragan Stancevic ` (5 preceding siblings ...) 2023-04-11 18:16 ` RAGHU H @ 2023-05-09 15:08 ` Dragan Stancevic 6 siblings, 0 replies; 40+ messages in thread From: Dragan Stancevic @ 2023-05-09 15:08 UTC (permalink / raw) To: lsf-pc; +Cc: nil-migration, linux-cxl, linux-mm Hey folks- to those that attended the BoF, just wanted to say thank you for your time and attention, I appreciate it. It was a bit challenging being remote, getting choppy sound, and I already have hearing loss so I wasn't able to 100% hear what people were saying. So if you asked me "how you like them apples" and I said "Yeah, bananas are cool", I apologize. Please feel free to email me with any additional thoughts or questions. Thanks On 4/7/23 16:05, Dragan Stancevic wrote: > Hi folks- > > if it's not too late for the schedule... > > I am starting to tackle VM live migration and hypervisor clustering over > switched CXL memory[1][2], intended for cloud virtualization types of > loads. > > I'd be interested in doing a small BoF session with some slides and get > into a discussion/brainstorming with other people that deal with VM/LM > cloud loads. Among other things to discuss would be page migrations over > switched CXL memory, shared in-memory ABI to allow VM hand-off between > hypervisors, etc... > > A few of us discussed some of this under the ZONE_XMEM thread, but I > figured it might be better to start a separate thread. > > If there is interested, thank you. > > > [1]. High-level overview available at http://nil-migration.org/ > [2]. Based on CXL spec 3.0 > > -- > Peace can only come as a natural consequence > of universal enlightenment -Dr. Nikola Tesla > -- Peace can only come as a natural consequence of universal enlightenment -Dr. Nikola Tesla ^ permalink raw reply [flat|nested] 40+ messages in thread
end of thread, other threads:[~2023-05-09 15:08 UTC | newest]
Thread overview: 40+ messages (download: mbox.gz / follow: Atom feed)
-- links below jump to the message on this page --
2023-04-07 21:05 [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory Dragan Stancevic
2023-04-07 22:23 ` James Houghton
2023-04-07 23:17 ` David Rientjes
2023-04-08 1:33 ` Dragan Stancevic
2023-04-08 16:24 ` Dragan Stancevic
2023-04-08 0:05 ` Gregory Price
2023-04-11 0:56 ` Dragan Stancevic
2023-04-11 1:48 ` Gregory Price
2023-04-14 3:32 ` Dragan Stancevic
2023-04-14 13:16 ` [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory Jonathan Cameron
2023-04-11 6:37 ` [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory Huang, Ying
2023-04-11 15:36 ` Gregory Price
2023-04-12 2:54 ` Huang, Ying
2023-04-12 8:38 ` David Hildenbrand
[not found] ` <CGME20230412111034epcas2p1b46d2a26b7d3ac5db3b0e454255527b0@epcas2p1.samsung.com>
2023-04-12 11:10 ` FW: [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory Kyungsan Kim
2023-04-12 11:26 ` David Hildenbrand
[not found] ` <CGME20230414084110epcas2p20b90a8d1892110d7ca3ac16290cd4686@epcas2p2.samsung.com>
2023-04-14 8:41 ` Kyungsan Kim
2023-04-12 15:40 ` Matthew Wilcox
[not found] ` <CGME20230414084114epcas2p4754d6c0d3c86a0d6d4e855058562100f@epcas2p4.samsung.com>
2023-04-14 8:41 ` Kyungsan Kim
2023-04-12 15:15 ` [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory James Bottomley
2023-05-03 23:42 ` Dragan Stancevic
2023-04-12 15:26 ` Gregory Price
2023-04-12 15:50 ` David Hildenbrand
2023-04-12 16:34 ` Gregory Price
2023-04-14 4:16 ` Dragan Stancevic
2023-04-14 3:33 ` Dragan Stancevic
2023-04-14 5:35 ` Huang, Ying
2023-04-09 17:40 ` Shreyas Shah
2023-04-11 1:08 ` Dragan Stancevic
2023-04-11 1:17 ` Shreyas Shah
2023-04-11 1:32 ` Dragan Stancevic
2023-04-11 4:33 ` Shreyas Shah
2023-04-14 3:26 ` Dragan Stancevic
[not found] ` <CGME20230410030532epcas2p49eae675396bf81658c1a3401796da1d4@epcas2p4.samsung.com>
2023-04-10 3:05 ` [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory Kyungsan Kim
2023-04-10 17:46 ` [External] " Viacheslav A.Dubeyko
2023-04-14 3:27 ` Dragan Stancevic
2023-04-11 18:00 ` [LSF/MM/BPF TOPIC] BoF VM live migration over CXL memory Dave Hansen
2023-05-01 23:49 ` Dragan Stancevic
2023-04-11 18:16 ` RAGHU H
2023-05-09 15:08 ` Dragan Stancevic
This is a public inbox, see mirroring instructions for how to clone and mirror all data and code used for this inbox; as well as URLs for NNTP newsgroup(s).
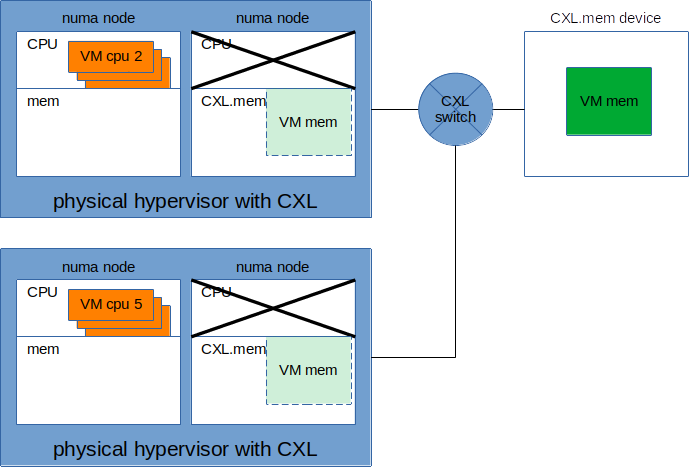{kind=link}
{kind=link}